 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Model Robustness via Fisher Information: Spectral Bounds, Theoretical Guarantees, and Practical Algorithms
Jun 03, 2026The robustness of deep neural networks is crucial for safety-critical deployments, yet existing evaluation methods are often attack-dependent and lack interpretability. We propose a principled, attack-agnostic robustness metric based on the spectral norm of the Fisher Information Matrix (FIM), which quantifies the worst-case sensitivity of the model's output distribution to input perturbations. Theoretically, we establish that the FIM equals the variance of the input Jacobian and derive closed-form spectral bounds for common architectures, including VGG, ResNet, DenseNet, and Transformer, providing the first theoretical robustness ranking. To enable scalable evaluation, we develop efficient algorithms, including power iteration and Hutchinson-based estimation, that support both white-box and black-box settings. Extensive experiments across multiple datasets, including CIFAR, ImageNet, and medical images, and across multiple architectures show a strong correlation between our metric and adversarial vulnerability. Our framework serves as an interpretable diagnostic tool that complements attack-based evaluations, offering insights into architectural sensitivity and guiding the design of more robust models. Code is available at: https://github.com/franz-chang/SRP/.
Singularity-aware Optimization via Randomized Geometric Probing: Towards Stable Non-smooth Optimization
May 28, 2026Deep learning optimization relies heavily on the assumption of smooth loss landscapes, a condition systematically violated by modern architectures due to non-smooth components such as ReLU activations and quantization operators. In such non-smooth regimes, adaptive optimizers such as Adam suffer from gradient chattering, violent oscillations caused by conflicting signals within the Clarke subdifferential, leading to poor convergence and suboptimal generalization. To address this, we introduce Singularity-aware Adam (S-Adam), a novel optimizer that stabilizes training by dynamically modulating step sizes based on local geometric instability. Our key contribution is the Local Geometric Instability (LGI) metric, a computationally efficient estimator of the Clarke subdifferential diameter derived from the variance of randomized directional derivatives. S-Adam incorporates an adaptive damping mechanism exp(-$λ$$ρ$) that decelerates updates in high-instability regions while preserving fast convergence in smooth basins. We provide a rigorous convergence analysis using differential inclusions, proving that S-Adam converges almost surely to ($δ$,$ε$)-Clarke stationary points at the optimal O(1/$\sqrt(T)$) rate. Empirical evaluations on Quantization-Aware Training (QAT) and high-noise small-batch learning demonstrate that S-Adam consistently outperforms AdamW and Prox-SGD, achieving accuracy gains of up to 6 percent on CIFAR-100 and 3 percent on TinyImageNet while effectively mitigating gradient oscillations.
StealthMark: Harmless and Stealthy Ownership Verification for Medical Segmentation via Uncertainty-Guided Backdoors
Jan 23, 2026Annotating medical data for training AI models is often costly and limited due to the shortage of specialists with relevant clinical expertise. This challenge is further compounded by privacy and ethical concerns associated with sensitive patient information. As a result, well-trained medical segmentation models on private datasets constitute valuable intellectual property requiring robust protection mechanisms. Existing model protection techniques primarily focus on classification and generative tasks, while segmentation models-crucial to medical image analysis-remain largely underexplored. In this paper, we propose a novel, stealthy, and harmless method, StealthMark, for verifying the ownership of medical segmentation models under black-box conditions. Our approach subtly modulates model uncertainty without altering the final segmentation outputs, thereby preserving the model's performance. To enable ownership verification, we incorporate model-agnostic explanation methods, e.g. LIME, to extract feature attributions from the model outputs. Under specific triggering conditions, these explanations reveal a distinct and verifiable watermark. We further design the watermark as a QR code to facilitate robust and recognizable ownership claims. We conducted extensive experiments across four medical imaging datasets and five mainstream segmentation models. The results demonstrate the effectiveness, stealthiness, and harmlessness of our method on the original model's segmentation performance. For example, when applied to the SAM model, StealthMark consistently achieved ASR above 95% across various datasets while maintaining less than a 1% drop in Dice and AUC scores, significantly outperforming backdoor-based watermarking methods and highlighting its strong potential for practical deployment. Our implementation code is made available at: https://github.com/Qinkaiyu/StealthMark.
Wavelet-Aware Anomaly Detection in Multi-Channel User Logs via Deviation Modulation and Resolution-Adaptive Attention
Jan 18, 2026Insider threat detection is a key challenge in enterprise security, relying on user activity logs that capture rich and complex behavioral patterns. These logs are often multi-channel, non-stationary, and anomalies are rare, making anomaly detection challenging. To address these issues, we propose a novel framework that integrates wavelet-aware modulation, multi-resolution wavelet decomposition, and resolution-adaptive attention for robust anomaly detection. Our approach first applies a deviation-aware modulation scheme to suppress routine behaviors while amplifying anomalous deviations. Next, discrete wavelet transform (DWT) decomposes the log signals into multi-resolution representations, capturing both long-term trends and short-term anomalies. Finally, a learnable attention mechanism dynamically reweights the most discriminative frequency bands for detection. On the CERT r4.2 benchmark, our approach consistently outperforms existing baselines in precision, recall, and F1 score across various time granularities and scenarios.
Accelerating Evolution: Integrating PSO Principles into Real-Coded Genetic Algorithm Crossover
May 06, 2025This study introduces an innovative crossover operator named Particle Swarm Optimization-inspired Crossover (PSOX), which is specifically developed for real-coded genetic algorithms. Departing from conventional crossover approaches that only exchange information between individuals within the same generation, PSOX uniquely incorporates guidance from both the current global best solution and historical optimal solutions across multiple generations. This novel mechanism enables the algorithm to maintain population diversity while simultaneously accelerating convergence toward promising regions of the search space. The effectiveness of PSOX is rigorously evaluated through comprehensive experiments on 15 benchmark test functions with diverse characteristics, including unimodal, multimodal, and highly complex landscapes. Comparative analysis against five state-of-the-art crossover operators reveals that PSOX consistently delivers superior performance in terms of solution accuracy, algorithmic stability, and convergence speed, especially when combined with an appropriate mutation strategy. Furthermore, the study provides an in-depth investigation of how different mutation rates influence PSOX's performance, yielding practical guidelines for parameter tuning when addressing optimization problems with varying landscape properties.
Interpretable Zero-shot Learning with Infinite Class Concepts
May 06, 2025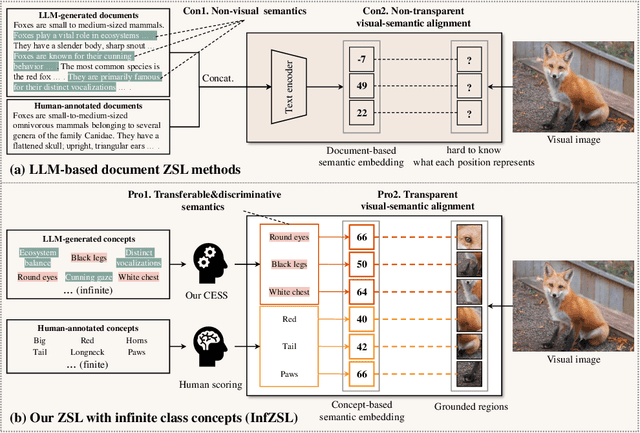
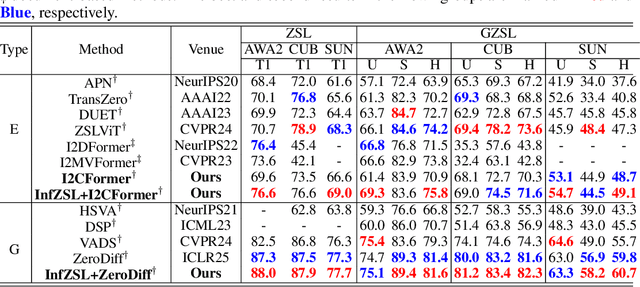
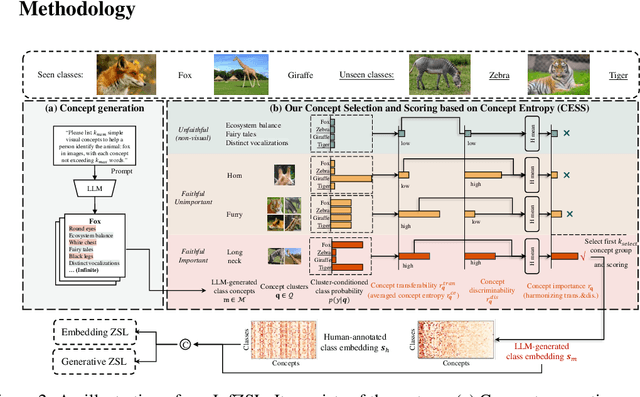
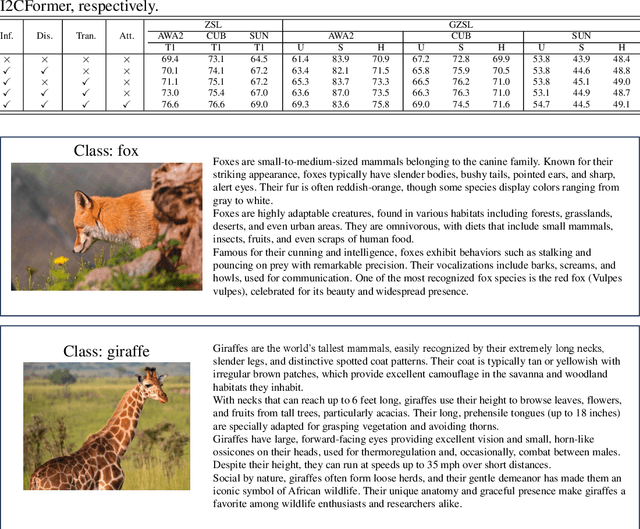
Zero-shot learning (ZSL) aims to recognize unseen classes by aligning images with intermediate class semantics, like human-annotated concepts or class definitions. An emerging alternative leverages Large-scale Language Models (LLMs) to automatically generate class documents. However, these methods often face challenges with transparency in the classification process and may suffer from the notorious hallucination problem in LLMs, resulting in non-visual class semantics. This paper redefines class semantics in ZSL with a focus on transferability and discriminability, introducing a novel framework called Zero-shot Learning with Infinite Class Concepts (InfZSL). Our approach leverages the powerful capabilities of LLMs to dynamically generate an unlimited array of phrase-level class concepts. To address the hallucination challenge, we introduce an entropy-based scoring process that incorporates a ``goodness" concept selection mechanism, ensuring that only the most transferable and discriminative concepts are selected. Our InfZSL framework not only demonstrates significant improvements on three popular benchmark datasets but also generates highly interpretable, image-grounded concepts. Code will be released upon acceptance.
Is Temporal Prompting All We Need For Limited Labeled Action Recognition?
Apr 02, 2025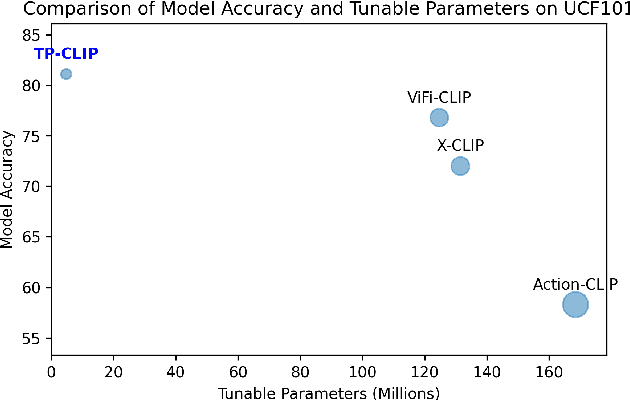
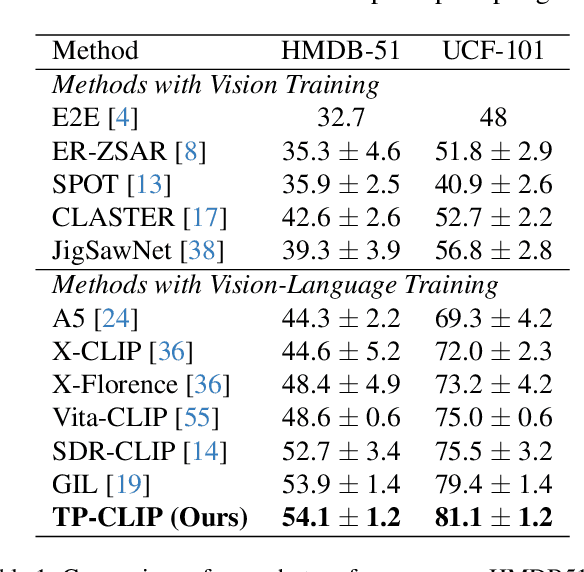
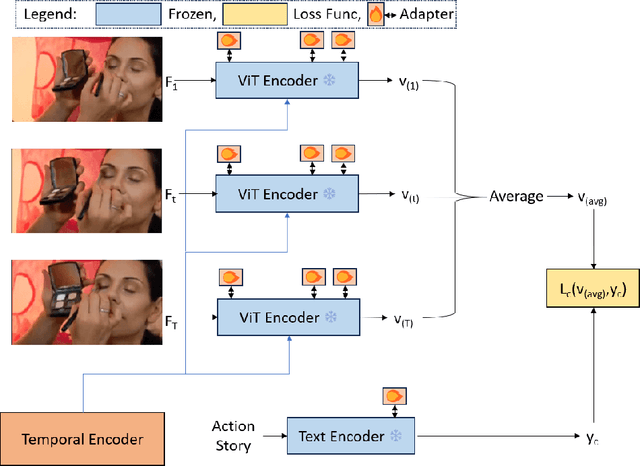
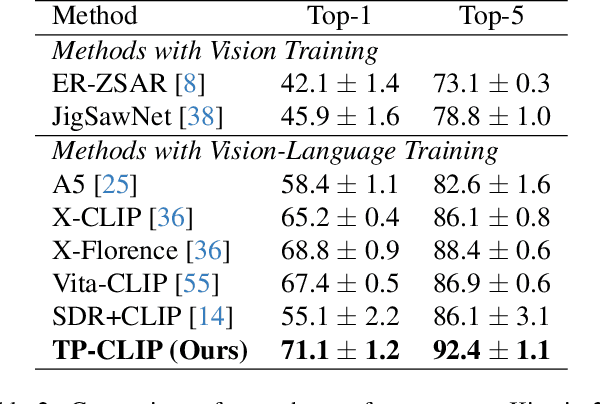
Video understanding has shown remarkable improvements in recent years, largely dependent on the availability of large scaled labeled datasets. Recent advancements in visual-language models, especially based on contrastive pretraining, have shown remarkable generalization in zero-shot tasks, helping to overcome this dependence on labeled datasets. Adaptations of such models for videos, typically involve modifying the architecture of vision-language models to cater to video data. However, this is not trivial, since such adaptations are mostly computationally intensive and struggle with temporal modeling. We present TP-CLIP, an adaptation of CLIP that leverages temporal visual prompting for temporal adaptation without modifying the core CLIP architecture. This preserves its generalization abilities. TP-CLIP efficiently integrates into the CLIP architecture, leveraging its pre-trained capabilities for video data. Extensive experiments across various datasets demonstrate its efficacy in zero-shot and few-shot learning, outperforming existing approaches with fewer parameters and computational efficiency. In particular, we use just 1/3 the GFLOPs and 1/28 the number of tuneable parameters in comparison to recent state-of-the-art and still outperform it by up to 15.8% depending on the task and dataset.
Improved Feature Generating Framework for Transductive Zero-shot Learning
Dec 24, 2024Feature Generative Adversarial Networks have emerged as powerful generative models in producing high-quality representations of unseen classes within the scope of Zero-shot Learning (ZSL). This paper delves into the pivotal influence of unseen class priors within the framework of transductive ZSL (TZSL) and illuminates the finding that even a marginal prior bias can result in substantial accuracy declines. Our extensive analysis uncovers that this inefficacy fundamentally stems from the utilization of an unconditional unseen discriminator - a core component in existing TZSL. We further establish that the detrimental effects of this component are inevitable unless the generator perfectly fits class-specific distributions. Building on these insights, we introduce our Improved Feature Generation Framework, termed I-VAEGAN, which incorporates two novel components: Pseudo-conditional Feature Adversarial (PFA) learning and Variational Embedding Regression (VER). PFA circumvents the need for prior estimation by explicitly injecting the predicted semantics as pseudo conditions for unseen classes premised by precise semantic regression. Meanwhile, VER utilizes reconstructive pre-training to learn class statistics, obtaining better semantic regression. Our I-VAEGAN achieves state-of-the-art TZSL accuracy across various benchmarks and priors. Our code would be released upon acceptance.
Template-Driven LLM-Paraphrased Framework for Tabular Math Word Problem Generation
Dec 20, 2024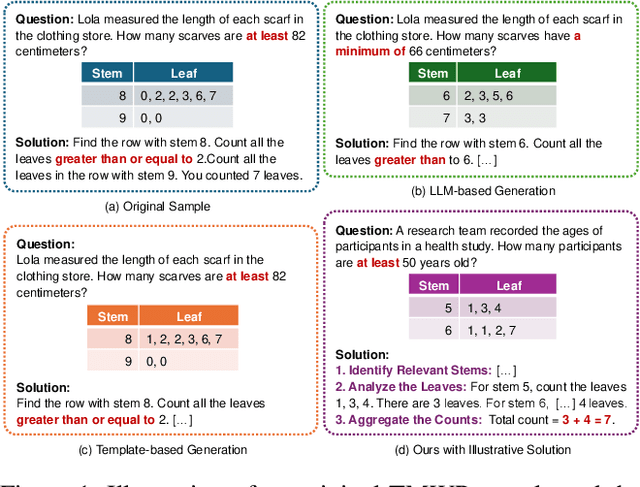
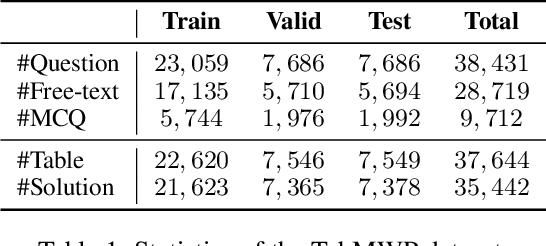
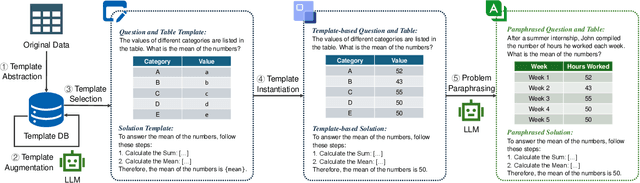
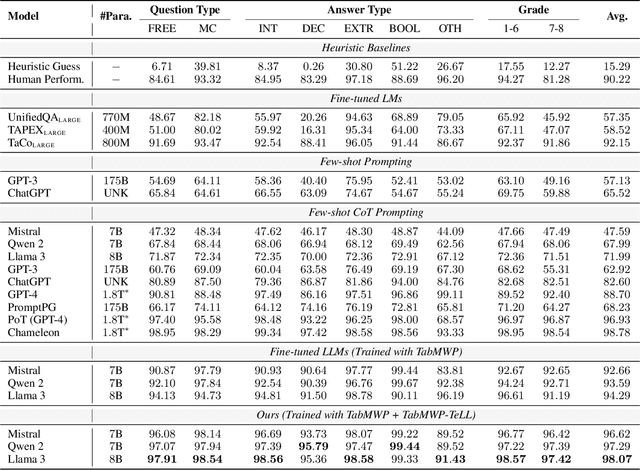
Solving tabular math word problems (TMWPs) has become a critical role in evaluating the mathematical reasoning ability of large language models (LLMs), where large-scale TMWP samples are commonly required for LLM fine-tuning. Since the collection of high-quality TMWP datasets is costly and time-consuming, recent research has concentrated on automatic TMWP generation. However, current generated samples usually suffer from issues of either correctness or diversity. In this paper, we propose a Template-driven LLM-paraphrased (TeLL) framework for generating high-quality TMWP samples with diverse backgrounds and accurate tables, questions, answers, and solutions. To this end, we first extract templates from existing real samples to generate initial problems, ensuring correctness. Then, we adopt an LLM to extend templates and paraphrase problems, obtaining diverse TMWP samples. Furthermore, we find the reasoning annotation is important for solving TMWPs. Therefore, we propose to enrich each solution with illustrative reasoning steps. Through the proposed framework, we construct a high-quality dataset TabMWP-TeLL by adhering to the question types in the TabMWP dataset, and we conduct extensive experiments on a variety of LLMs to demonstrate the effectiveness of TabMWP-TeLL in improving TMWP solving performance. The code and data of this paper are available at: https://github.com/Jason8Kang/TELL.
Twin Trigger Generative Networks for Backdoor Attacks against Object Detection
Nov 23, 2024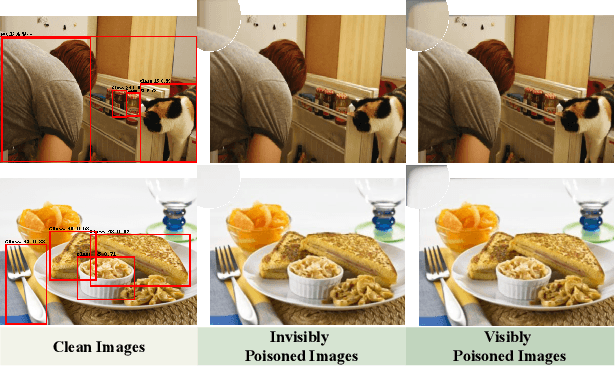
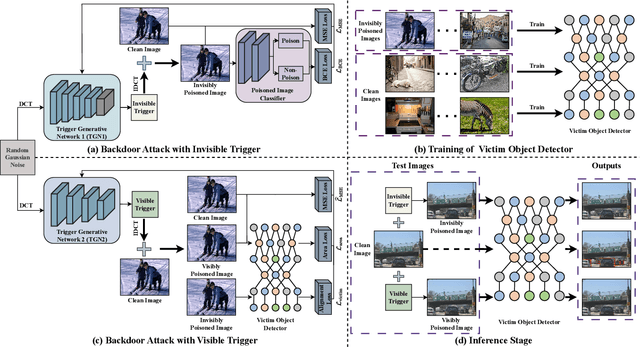
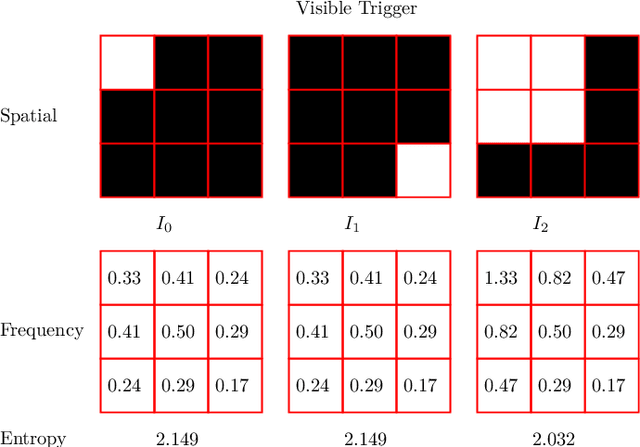
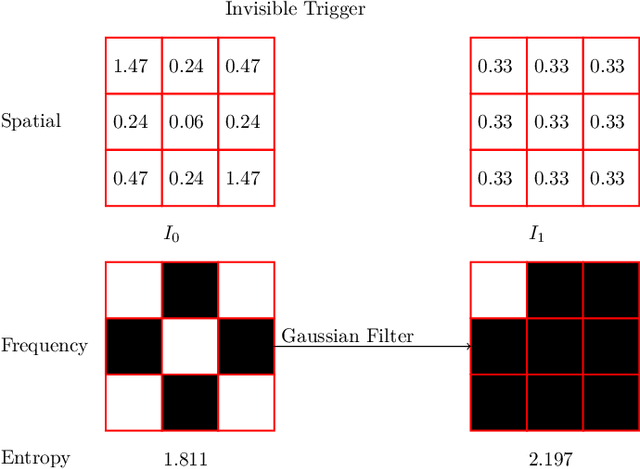
Object detectors, which are widely used in real-world applications, are vulnerable to backdoor attacks. This vulnerability arises because many users rely on datasets or pre-trained models provided by third parties due to constraints on data and resources. However, most research on backdoor attacks has focused on image classification, with limited investigation into object detection. Furthermore, the triggers for most existing backdoor attacks on object detection are manually generated, requiring prior knowledge and consistent patterns between the training and inference stages. This approach makes the attacks either easy to detect or difficult to adapt to various scenarios. To address these limitations, we propose novel twin trigger generative networks in the frequency domain to generate invisible triggers for implanting stealthy backdoors into models during training, and visible triggers for steady activation during inference, making the attack process difficult to trace. Specifically, for the invisible trigger generative network, we deploy a Gaussian smoothing layer and a high-frequency artifact classifier to enhance the stealthiness of backdoor implantation in object detectors. For the visible trigger generative network, we design a novel alignment loss to optimize the visible triggers so that they differ from the original patterns but still align with the malicious activation behavior of the invisible triggers. Extensive experimental results and analyses prove the possibility of using different triggers in the training stage and the inference stage, and demonstrate the attack effectiveness of our proposed visible trigger and invisible trigger generative networks, significantly reducing the mAP_0.5 of the object detectors by 70.0% and 84.5%, including YOLOv5 and YOLOv7 with different settings, respectively.