 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Explainability as a Training-Time Reliability Signal for Efficient ECG Classification
Jun 10, 2026Training deep neural networks for clinical time-series analysis is computationally demanding, yet many healthcare settings lack the resources required for repeated model development and deployment. This challenge is particularly evident in electrocardiogram classification, where large datasets and long training schedules make efficiency practically important. Progressive Data Dropout reduces training cost by excluding samples from gradient updates once they are learned, but it relies on model confidence and may retain samples that are difficult due to noise or ambiguity rather than useful signal. In this work, we introduce ERTS, an explainability-based reliability training signal for efficient ECG classification. ERTS uses explanation quality during training to distinguish between informative and unreliable uncertainty. Building on progressive data selection, we compute Grad-CAM attention maps for candidate samples and derive a focus score that measures whether model predictions are supported by coherent and localised patterns. Samples with low focus are filtered out, while those with meaningful attention are prioritised for gradient updates. We evaluate ERTS across three ECG datasets and multiple backbone architectures, showing consistent improvements in macro-F1 alongside reduced effective training cost. These results suggest that explanation quality can serve as a practical signal for improving both efficiency and reliability in clinical time-series learning. Code will be released.
Can News Predict the Market? Limits of Zero-Shot Financial NLP and the Role of Explainable AI
Jun 10, 2026Can financial news reliably predict short-term stock movements? Despite advances in large language models, this question remains unresolved. We revisit this problem using a zero-shot natural language processing framework, investigating whether models can extract actionable signals from financial news without domain-specific training. We design a structured pipeline that combines zero-shot natural language inference with temporal aggregation, explicitly modelling recency and event-dependent impact horizons when integrating information across articles. To address the need for transparency in high-stakes settings, we introduce a multi-layered explainability framework that links predictions to token-level, article-level, and aggregate evidence, and produces grounded natural language rationales. Across multiple models and prediction horizons, we find that zero-shot approaches consistently fail to outperform simple baselines, with particularly weak performance on negative movements, suggesting deeper structural limitations in mapping news sentiment to short-term price dynamics. However, explainability signals reliably distinguish between trustworthy and unreliable predictions, offering practical value even when accuracy is limited. These findings highlight the limits of zero-shot financial NLP and motivate a shift toward decision-support systems that prioritise transparency and uncertainty awareness. Code: https://github.com/alimert05/zero-shot-stock-xai
Prompt Injection Detection is Regime-Dependent: A Deployment-Aware Evaluation with Interpretable Structural Signals
May 26, 2026Prompt injection poses a critical threat to the safe deployment of large language models, yet existing detection approaches are typically evaluated under limited settings that do not reflect real-world operating constraints. In this work, we present a deployment-aware evaluation of prompt injection detection using a multi-model and multi-regime experimental framework. We compare lexical, semantic, structural, and transformer-based detectors across multiple out-of-distribution settings, repeated data splits, and both ranking and thresholded deployment metrics. We introduce interpretable structural signals that capture hierarchy overrides, system prompt spoofing, role redefinition, and evasion patterns, and assess their contribution both within sparse models and in combination with strong encoder baselines. Our results show that detection performance is highly regime-dependent and sensitive to threshold selection, with no single model dominating across all settings. Transformer-based models achieve the strongest overall performance, while structural signals provide modest but consistent gains in certain regimes and improve low false positive rate behaviour in harder scenarios. These findings highlight the gap between ranking performance and deployment effectiveness and underscore the importance of evaluating prompt injection defences under realistic operational constraints. Code will be released.
An Empirical Study of Multi-Generation Sampling for Jailbreak Detection in Large Language Models
Apr 20, 2026Detecting jailbreak behaviour in large language models remains challenging, particularly when strongly aligned models produce harmful outputs only rarely. In this work, we present an empirical study of output based jailbreak detection under realistic conditions using the JailbreakBench Behaviors dataset and multiple generator models with varying alignment strengths. We evaluate both a lexical TF-IDF detector and a generation inconsistency based detector across different sampling budgets. Our results show that single output evaluation systematically underestimates jailbreak vulnerability, as increasing the number of sampled generations reveals additional harmful behaviour. The most significant improvements occur when moving from a single generation to moderate sampling, while larger sampling budgets yield diminishing returns. Cross generator experiments demonstrate that detection signals partially generalise across models, with stronger transfer observed within related model families. A category level analysis further reveals that lexical detectors capture a mixture of behavioural signals and topic specific cues, rather than purely harmful behaviour. Overall, our findings suggest that moderate multi sample auditing provides a more reliable and practical approach for estimating model vulnerability and improving jailbreak detection in large language models. Code will be released.
Adaptive Data Dropout: Towards Self-Regulated Learning in Deep Neural Networks
Apr 14, 2026Deep neural networks are typically trained by uniformly sampling large datasets across epochs, despite evidence that not all samples contribute equally throughout learning. Recent work shows that progressively reducing the amount of training data can improve efficiency and generalization, but existing methods rely on fixed schedules that do not adapt during training. In this work, we propose Adaptive Data Dropout, a simple framework that dynamically adjusts the subset of training data based on performance feedback. Inspired by self-regulated learning, our approach treats data selection as an adaptive process, increasing or decreasing data exposure in response to changes in training accuracy. We introduce a lightweight stochastic update mechanism that modulates the dropout schedule online, allowing the model to balance exploration and consolidation over time. Experiments on standard image classification benchmarks show that our method reduces effective training steps while maintaining competitive accuracy compared to static data dropout strategies. These results highlight adaptive data selection as a promising direction for efficient and robust training. Code will be released.
Compression as an Adversarial Amplifier Through Decision Space Reduction
Apr 08, 2026Image compression is a ubiquitous component of modern visual pipelines, routinely applied by social media platforms and resource-constrained systems prior to inference. Despite its prevalence, the impact of compression on adversarial robustness remains poorly understood. We study a previously unexplored adversarial setting in which attacks are applied directly in compressed representations, and show that compression can act as an adversarial amplifier for deep image classifiers. Under identical nominal perturbation budgets, compression-aware attacks are substantially more effective than their pixel-space counterparts. We attribute this effect to decision space reduction, whereby compression induces a non-invertible, information-losing transformation that contracts classification margins and increases sensitivity to perturbations. Extensive experiments across standard benchmarks and architectures support our analysis and reveal a critical vulnerability in compression-in-the-loop deployment settings. Code will be released.
Low-Effort Jailbreak Attacks Against Text-to-Image Safety Filters
Apr 02, 2026Text-to-image generative models are widely deployed in creative tools and online platforms. To mitigate misuse, these systems rely on safety filters and moderation pipelines that aim to block harmful or policy violating content. In this work we show that modern text-to-image models remain vulnerable to low-effort jailbreak attacks that require only natural language prompts. We present a systematic study of prompt-based strategies that bypass safety filters without model access, optimization, or adversarial training. We introduce a taxonomy of visual jailbreak techniques including artistic reframing, material substitution, pseudo-educational framing, lifestyle aesthetic camouflage, and ambiguous action substitution. These strategies exploit weaknesses in prompt moderation and visual safety filtering by masking unsafe intent within benign semantic contexts. We evaluate these attacks across several state-of-the-art text-to-image systems and demonstrate that simple linguistic modifications can reliably evade existing safeguards and produce restricted imagery. Our findings highlight a critical gap between surface-level prompt filtering and the semantic understanding required to detect adversarial intent in generative media systems. Across all tested models and attack categories we observe an attack success rate (ASR) of up to 74.47%.
ZeroDiff++: Substantial Unseen Visual-semantic Correlation in Zero-shot Learning
Feb 12, 2026Zero-shot Learning (ZSL) enables classifiers to recognize classes unseen during training, commonly via generative two stage methods: (1) learn visual semantic correlations from seen classes; (2) synthesize unseen class features from semantics to train classifiers. In this paper, we identify spurious visual semantic correlations in existing generative ZSL worsened by scarce seen class samples and introduce two metrics to quantify spuriousness for seen and unseen classes. Furthermore, we point out a more critical bottleneck: existing unadaptive fully noised generators produce features disconnected from real test samples, which also leads to the spurious correlation. To enhance the visual-semantic correlations on both seen and unseen classes, we propose ZeroDiff++, a diffusion-based generative framework. In training, ZeroDiff++ uses (i) diffusion augmentation to produce diverse noised samples, (ii) supervised contrastive (SC) representations for instance level semantics, and (iii) multi view discriminators with Wasserstein mutual learning to assess generated features. At generation time, we introduce (iv) Diffusion-based Test time Adaptation (DiffTTA) to adapt the generator using pseudo label reconstruction, and (v) Diffusion-based Test time Generation (DiffGen) to trace the diffusion denoising path and produce partially synthesized features that connect real and generated data, and mitigates data scarcity further. Extensive experiments on three ZSL benchmarks demonstrate that ZeroDiff++ not only achieves significant improvements over existing ZSL methods but also maintains robust performance even with scarce training data. Code would be available.
Adversarial Robustness in Zero-Shot Learning:An Empirical Study on Class and Concept-Level Vulnerabilities
Dec 21, 2025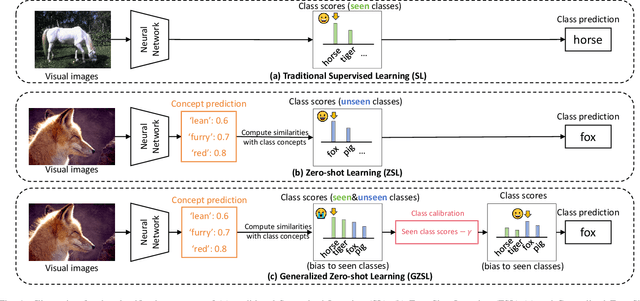

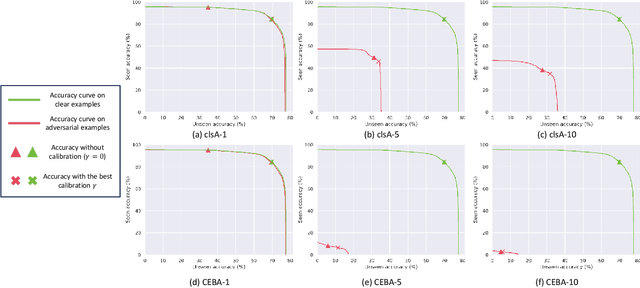
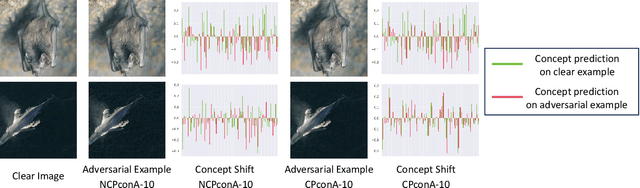
Zero-shot Learning (ZSL) aims to enable image classifiers to recognize images from unseen classes that were not included during training. Unlike traditional supervised classification, ZSL typically relies on learning a mapping from visual features to predefined, human-understandable class concepts. While ZSL models promise to improve generalization and interpretability, their robustness under systematic input perturbations remain unclear. In this study, we present an empirical analysis about the robustness of existing ZSL methods at both classlevel and concept-level. Specifically, we successfully disrupted their class prediction by the well-known non-target class attack (clsA). However, in the Generalized Zero-shot Learning (GZSL) setting, we observe that the success of clsA is only at the original best-calibrated point. After the attack, the optimal bestcalibration point shifts, and ZSL models maintain relatively strong performance at other calibration points, indicating that clsA results in a spurious attack success in the GZSL. To address this, we propose the Class-Bias Enhanced Attack (CBEA), which completely eliminates GZSL accuracy across all calibrated points by enhancing the gap between seen and unseen class probabilities.Next, at concept-level attack, we introduce two novel attack modes: Class-Preserving Concept Attack (CPconA) and NonClass-Preserving Concept Attack (NCPconA). Our extensive experiments evaluate three typical ZSL models across various architectures from the past three years and reveal that ZSL models are vulnerable not only to the traditional class attack but also to concept-based attacks. These attacks allow malicious actors to easily manipulate class predictions by erasing or introducing concepts. Our findings highlight a significant performance gap between existing approaches, emphasizing the need for improved adversarial robustness in current ZSL models.
Distribution-Based Masked Medical Vision-Language Model Using Structured Reports
Jul 29, 2025Medical image-language pre-training aims to align medical images with clinically relevant text to improve model performance on various downstream tasks. However, existing models often struggle with the variability and ambiguity inherent in medical data, limiting their ability to capture nuanced clinical information and uncertainty. This work introduces an uncertainty-aware medical image-text pre-training model that enhances generalization capabilities in medical image analysis. Building on previous methods and focusing on Chest X-Rays, our approach utilizes structured text reports generated by a large language model (LLM) to augment image data with clinically relevant context. These reports begin with a definition of the disease, followed by the `appearance' section to highlight critical regions of interest, and finally `observations' and `verdicts' that ground model predictions in clinical semantics. By modeling both inter- and intra-modal uncertainty, our framework captures the inherent ambiguity in medical images and text, yielding improved representations and performance on downstream tasks. Our model demonstrates significant advances in medical image-text pre-training, obtaining state-of-the-art performance on multiple downstream tasks.