 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's a Matter of Time: Three Lessons on Long-Term Motion for Perception
Feb 16, 2026Temporal information has long been considered to be essential for perception. While there is extensive research on the role of image information for perceptual tasks, the role of the temporal dimension remains less well understood: What can we learn about the world from long-term motion information? What properties does long-term motion information have for visual learning? We leverage recent success in point-track estimation, which offers an excellent opportunity to learn temporal representations and experiment on a variety of perceptual tasks. We draw 3 clear lessons: 1) Long-term motion representations contain information to understand actions, but also objects, materials, and spatial information, often even better than images. 2) Long-term motion representations generalize far better than image representations in low-data settings and in zero-shot tasks. 3) The very low dimensionality of motion information makes motion representations a better trade-off between GFLOPs and accuracy than standard video representations, and used together they achieve higher performance than video representations alone. We hope these insights will pave the way for the design of future models that leverage the power of long-term motion information for perception.
GaussianHeadTalk: Wobble-Free 3D Talking Heads with Audio Driven Gaussian Splatting
Dec 11, 2025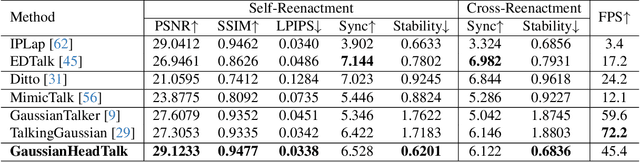
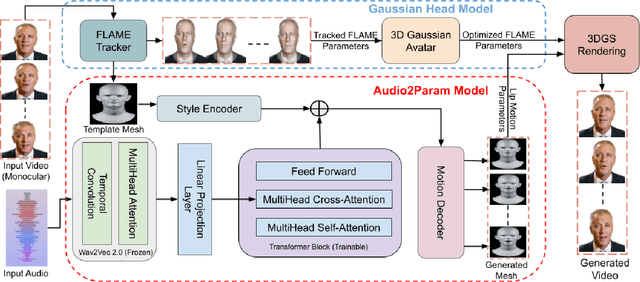
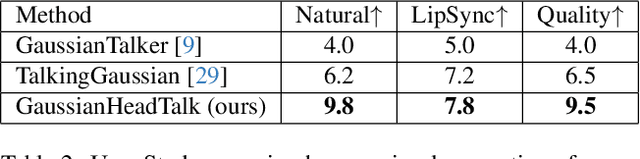

Speech-driven talking heads have recently emerged and enable interactive avatars. However, real-world applications are limited, as current methods achieve high visual fidelity but slow or fast yet temporally unstable. Diffusion methods provide realistic image generation, yet struggle with oneshot settings. Gaussian Splatting approaches are real-time, yet inaccuracies in facial tracking, or inconsistent Gaussian mappings, lead to unstable outputs and video artifacts that are detrimental to realistic use cases. We address this problem by mapping Gaussian Splatting using 3D Morphable Models to generate person-specific avatars. We introduce transformer-based prediction of model parameters, directly from audio, to drive temporal consistency. From monocular video and independent audio speech inputs, our method enables generation of real-time talking head videos where we report competitive quantitative and qualitative performance.
Progressive Data Dropout: An Embarrassingly Simple Approach to Faster Training
May 28, 2025The success of the machine learning field has reliably depended on training on large datasets. While effective, this trend comes at an extraordinary cost. This is due to two deeply intertwined factors: the size of models and the size of datasets. While promising research efforts focus on reducing the size of models, the other half of the equation remains fairly mysterious. Indeed, it is surprising that the standard approach to training remains to iterate over and over, uniformly sampling the training dataset. In this paper we explore a series of alternative training paradigms that leverage insights from hard-data-mining and dropout, simple enough to implement and use that can become the new training standard. The proposed Progressive Data Dropout reduces the number of effective epochs to as little as 12.4% of the baseline. This savings actually do not come at any cost for accuracy. Surprisingly, the proposed method improves accuracy by up to 4.82%. Our approach requires no changes to model architecture or optimizer, and can be applied across standard training pipelines, thus posing an excellent opportunity for wide adoption. Code can be found here: https://github.com/bazyagami/LearningWithRevision
Predicting Implicit Arguments in Procedural Video Instructions
May 27, 2025Procedural texts help AI enhance reasoning about context and action sequences. Transforming these into Semantic Role Labeling (SRL) improves understanding of individual steps by identifying predicate-argument structure like {verb,what,where/with}. Procedural instructions are highly elliptic, for instance, (i) add cucumber to the bowl and (ii) add sliced tomatoes, the second step's where argument is inferred from the context, referring to where the cucumber was placed. Prior SRL benchmarks often miss implicit arguments, leading to incomplete understanding. To address this, we introduce Implicit-VidSRL, a dataset that necessitates inferring implicit and explicit arguments from contextual information in multimodal cooking procedures. Our proposed dataset benchmarks multimodal models' contextual reasoning, requiring entity tracking through visual changes in recipes. We study recent multimodal LLMs and reveal that they struggle to predict implicit arguments of what and where/with from multi-modal procedural data given the verb. Lastly, we propose iSRL-Qwen2-VL, which achieves a 17% relative improvement in F1-score for what-implicit and a 14.7% for where/with-implicit semantic roles over GPT-4o.
Principles of Visual Tokens for Efficient Video Understanding
Nov 20, 2024



Video understanding has made huge strides in recent years, relying largely on the power of the transformer architecture. As this architecture is notoriously expensive and video is highly redundant, research into improving efficiency has become particularly relevant. This has led to many creative solutions, including token merging and token selection. While most methods succeed in reducing the cost of the model and maintaining accuracy, an interesting pattern arises: most methods do not outperform the random sampling baseline. In this paper we take a closer look at this phenomenon and make several observations. First, we develop an oracle for the value of tokens which exposes a clear Pareto distribution where most tokens have remarkably low value, and just a few carry most of the perceptual information. Second, we analyze why this oracle is extremely hard to learn, as it does not consistently coincide with visual cues. Third, we observe that easy videos need fewer tokens to maintain accuracy. We build on these and further insights to propose a lightweight video model we call LITE that can select a small number of tokens effectively, outperforming state-of-the-art and existing baselines across datasets (Kinetics400 and Something-Something-V2) in the challenging trade-off of computation (GFLOPs) vs accuracy.
Continual Learning Improves Zero-Shot Action Recognition
Oct 14, 2024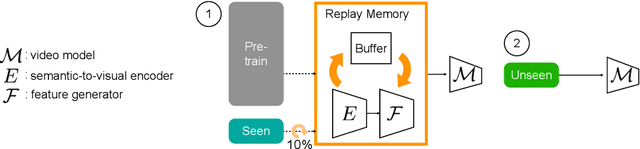
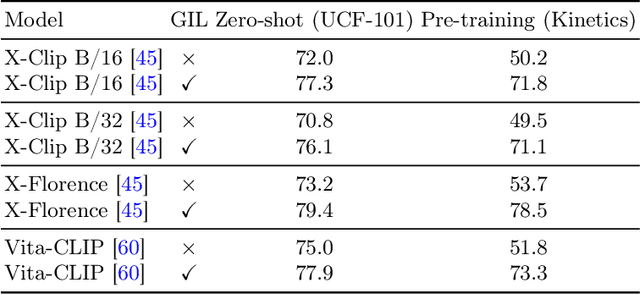

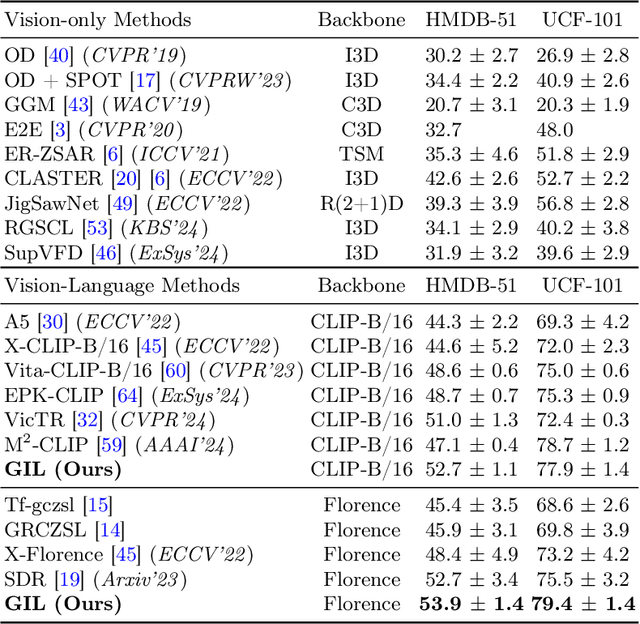
Zero-shot action recognition requires a strong ability to generalize from pre-training and seen classes to novel unseen classes. Similarly, continual learning aims to develop models that can generalize effectively and learn new tasks without forgetting the ones previously learned. The generalization goals of zero-shot and continual learning are closely aligned, however techniques from continual learning have not been applied to zero-shot action recognition. In this paper, we propose a novel method based on continual learning to address zero-shot action recognition. This model, which we call {\em Generative Iterative Learning} (GIL) uses a memory of synthesized features of past classes, and combines these synthetic features with real ones from novel classes. The memory is used to train a classification model, ensuring a balanced exposure to both old and new classes. Experiments demonstrate that {\em GIL} improves generalization in unseen classes, achieving a new state-of-the-art in zero-shot recognition across multiple benchmarks. Importantly, {\em GIL} also boosts performance in the more challenging generalized zero-shot setting, where models need to retain knowledge about classes seen before fine-tuning.
Learning Precise Affordances from Egocentric Videos for Robotic Manipulation
Aug 19, 2024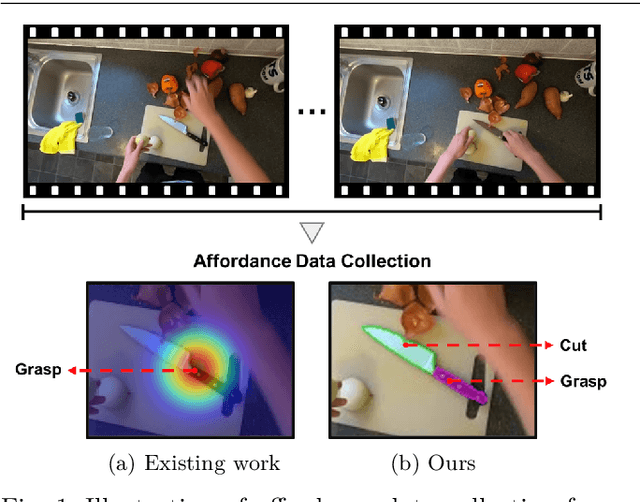

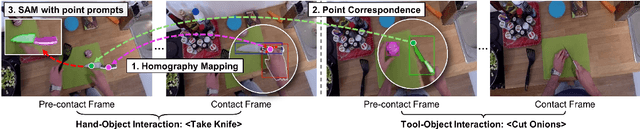
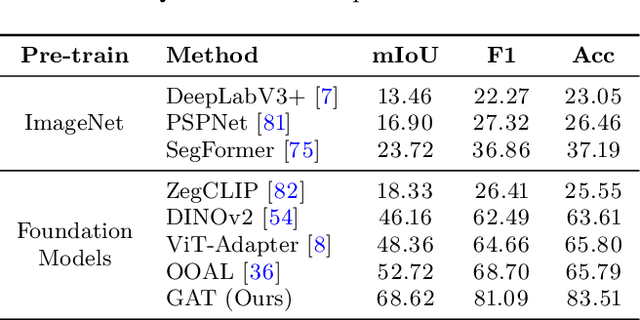
Affordance, defined as the potential actions that an object offers, is crucial for robotic manipulation tasks. A deep understanding of affordance can lead to more intelligent AI systems. For example, such knowledge directs an agent to grasp a knife by the handle for cutting and by the blade when passing it to someone. In this paper, we present a streamlined affordance learning system that encompasses data collection, effective model training, and robot deployment. First, we collect training data from egocentric videos in an automatic manner. Different from previous methods that focus only on the object graspable affordance and represent it as coarse heatmaps, we cover both graspable (e.g., object handles) and functional affordances (e.g., knife blades, hammer heads) and extract data with precise segmentation masks. We then propose an effective model, termed Geometry-guided Affordance Transformer (GKT), to train on the collected data. GKT integrates an innovative Depth Feature Injector (DFI) to incorporate 3D shape and geometric priors, enhancing the model's understanding of affordances. To enable affordance-oriented manipulation, we further introduce Aff-Grasp, a framework that combines GKT with a grasp generation model. For comprehensive evaluation, we create an affordance evaluation dataset with pixel-wise annotations, and design real-world tasks for robot experiments. The results show that GKT surpasses the state-of-the-art by 15.9% in mIoU, and Aff-Grasp achieves high success rates of 95.5% in affordance prediction and 77.1% in successful grasping among 179 trials, including evaluations with seen, unseen objects, and cluttered scenes.
Coarse or Fine? Recognising Action End States without Labels
May 13, 2024We focus on the problem of recognising the end state of an action in an image, which is critical for understanding what action is performed and in which manner. We study this focusing on the task of predicting the coarseness of a cut, i.e., deciding whether an object was cut "coarsely" or "finely". No dataset with these annotated end states is available, so we propose an augmentation method to synthesise training data. We apply this method to cutting actions extracted from an existing action recognition dataset. Our method is object agnostic, i.e., it presupposes the location of the object but not its identity. Starting from less than a hundred images of a whole object, we can generate several thousands images simulating visually diverse cuts of different coarseness. We use our synthetic data to train a model based on UNet and test it on real images showing coarsely/finely cut objects. Results demonstrate that the model successfully recognises the end state of the cutting action despite the domain gap between training and testing, and that the model generalises well to unseen objects.
One-Shot Open Affordance Learning with Foundation Models
Nov 29, 2023
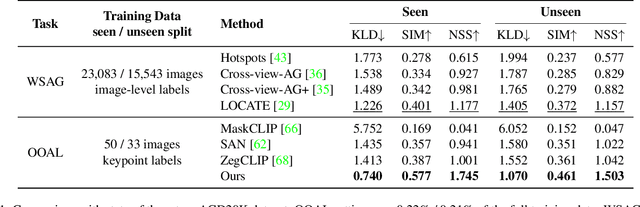
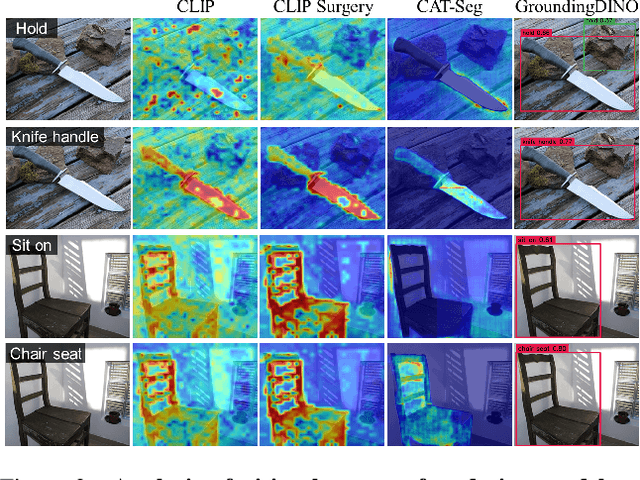
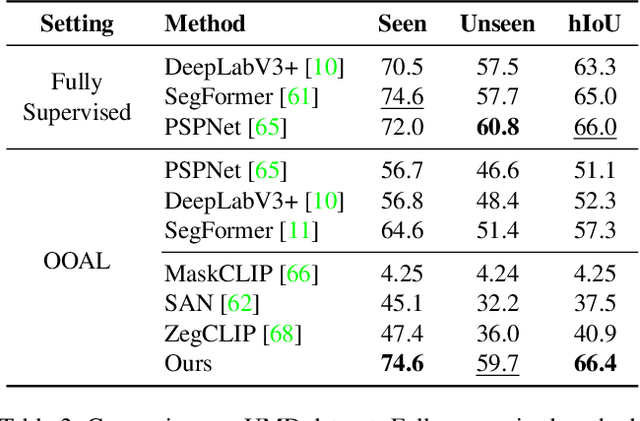
We introduce One-shot Open Affordance Learning (OOAL), where a model is trained with just one example per base object category, but is expected to identify novel objects and affordances. While vision-language models excel at recognizing novel objects and scenes, they often struggle to understand finer levels of granularity such as affordances. To handle this issue, we conduct a comprehensive analysis of existing foundation models, to explore their inherent understanding of affordances and assess the potential for data-limited affordance learning. We then propose a vision-language framework with simple and effective designs that boost the alignment between visual features and affordance text embeddings. Experiments on two affordance segmentation benchmarks show that the proposed method outperforms state-of-the-art models with less than 1% of the full training data, and exhibits reasonable generalization capability on unseen objects and affordances.
Efficient Pre-training for Localized Instruction Generation of Videos
Nov 27, 2023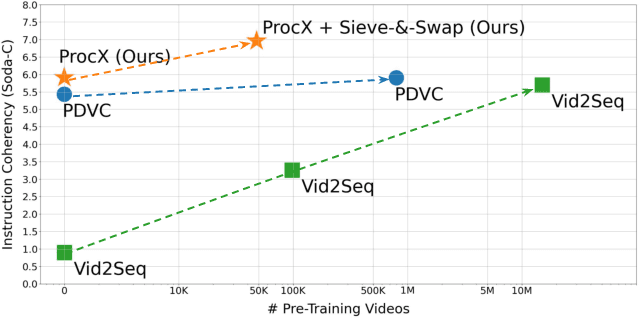


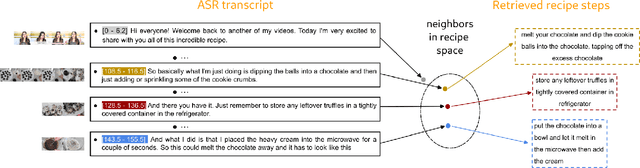
Procedural videos show step-by-step demonstrations of tasks like recipe preparation. Understanding such videos is challenging, involving the precise localization of steps and the generation of textual instructions. Manually annotating steps and writing instructions is costly, which limits the size of current datasets and hinders effective learning. Leveraging large but noisy video-transcript datasets for pre-training can boost performance, but demands significant computational resources. Furthermore, transcripts contain irrelevant content and exhibit style variation compared to instructions written by human annotators. To mitigate both issues, we propose a technique, Sieve-&-Swap, to automatically curate a smaller dataset: (i) Sieve filters irrelevant transcripts and (ii) Swap enhances the quality of the text instruction by automatically replacing the transcripts with human-written instructions from a text-only recipe dataset. The curated dataset, three orders of magnitude smaller than current web-scale datasets, enables efficient training of large-scale models with competitive performance. We complement our Sieve-\&-Swap approach with a Procedure Transformer (ProcX) for end-to-end step localization and instruction generation for procedural videos. When this model is pre-trained on our curated dataset, it achieves state-of-the-art performance in zero-shot and finetuning settings on YouCook2 and Tasty, while using a fraction of the computational resources.