 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining Reality: A Comprehensive Survey of Video Inpainting Techniques
Jan 31, 2024This paper offers a comprehensive analysis of recent advancements in video inpainting techniques, a critical subset of computer vision and artificial intelligence. As a process that restores or fills in missing or corrupted portions of video sequences with plausible content, video inpainting has evolved significantly with the advent of deep learning methodologies. Despite the plethora of existing methods and their swift development, the landscape remains complex, posing challenges to both novices and established researchers. Our study deconstructs major techniques, their underpinning theories, and their effective applications. Moreover, we conduct an exhaustive comparative study, centering on two often-overlooked dimensions: visual quality and computational efficiency. We adopt a human-centric approach to assess visual quality, enlisting a panel of annotators to evaluate the output of different video inpainting techniques. This provides a nuanced qualitative understanding that complements traditional quantitative metrics. Concurrently, we delve into the computational aspects, comparing inference times and memory demands across a standardized hardware setup. This analysis underscores the balance between quality and efficiency: a critical consideration for practical applications where resources may be constrained. By integrating human validation and computational resource comparison, this survey not only clarifies the present landscape of video inpainting techniques but also charts a course for future explorations in this vibrant and evolving field.
Watt For What: Rethinking Deep Learning's Energy-Performance Relationship
Oct 10, 2023Deep learning models have revolutionized various fields, from image recognition to natural language processing, by achieving unprecedented levels of accuracy. However, their increasing energy consumption has raised concerns about their environmental impact, disadvantaging smaller entities in research and exacerbating global energy consumption. In this paper, we explore the trade-off between model accuracy and electricity consumption, proposing a metric that penalizes large consumption of electricity. We conduct a comprehensive study on the electricity consumption of various deep learning models across different GPUs, presenting a detailed analysis of their accuracy-efficiency trade-offs. By evaluating accuracy per unit of electricity consumed, we demonstrate how smaller, more energy-efficient models can significantly expedite research while mitigating environmental concerns. Our results highlight the potential for a more sustainable approach to deep learning, emphasizing the importance of optimizing models for efficiency. This research also contributes to a more equitable research landscape, where smaller entities can compete effectively with larger counterparts. This advocates for the adoption of efficient deep learning practices to reduce electricity consumption, safeguarding the environment for future generations whilst also helping ensure a fairer competitive landscape.
From Pixels to Portraits: A Comprehensive Survey of Talking Head Generation Techniques and Applications
Aug 30, 2023
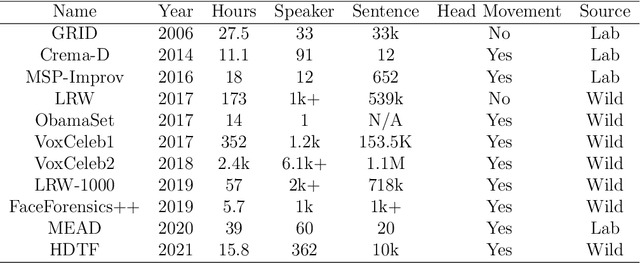


Recent advancements in deep learning and computer vision have led to a surge of interest in generating realistic talking heads. This paper presents a comprehensive survey of state-of-the-art methods for talking head generation. We systematically categorises them into four main approaches: image-driven, audio-driven, video-driven and others (including neural radiance fields (NeRF), and 3D-based methods). We provide an in-depth analysis of each method, highlighting their unique contributions, strengths, and limitations. Furthermore, we thoroughly compare publicly available models, evaluating them on key aspects such as inference time and human-rated quality of the generated outputs. Our aim is to provide a clear and concise overview of the current landscape in talking head generation, elucidating the relationships between different approaches and identifying promising directions for future research. This survey will serve as a valuable reference for researchers and practitioners interested in this rapidly evolving field.