 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Portraits: A Comprehensive Survey of Talking Head Generation Techniques and Applications
Aug 30, 2023
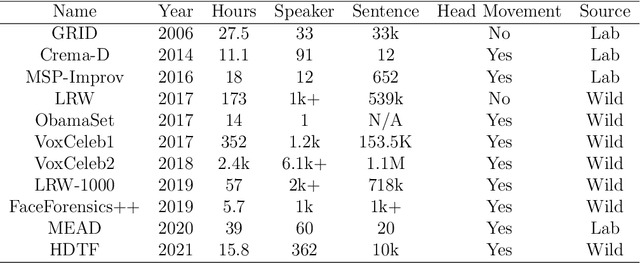


Recent advancements in deep learning and computer vision have led to a surge of interest in generating realistic talking heads. This paper presents a comprehensive survey of state-of-the-art methods for talking head generation. We systematically categorises them into four main approaches: image-driven, audio-driven, video-driven and others (including neural radiance fields (NeRF), and 3D-based methods). We provide an in-depth analysis of each method, highlighting their unique contributions, strengths, and limitations. Furthermore, we thoroughly compare publicly available models, evaluating them on key aspects such as inference time and human-rated quality of the generated outputs. Our aim is to provide a clear and concise overview of the current landscape in talking head generation, elucidating the relationships between different approaches and identifying promising directions for future research. This survey will serve as a valuable reference for researchers and practitioners interested in this rapidly evolving field.