 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrinciples of Visual Tokens for Efficient Video Understanding
Nov 20, 2024



Video understanding has made huge strides in recent years, relying largely on the power of the transformer architecture. As this architecture is notoriously expensive and video is highly redundant, research into improving efficiency has become particularly relevant. This has led to many creative solutions, including token merging and token selection. While most methods succeed in reducing the cost of the model and maintaining accuracy, an interesting pattern arises: most methods do not outperform the random sampling baseline. In this paper we take a closer look at this phenomenon and make several observations. First, we develop an oracle for the value of tokens which exposes a clear Pareto distribution where most tokens have remarkably low value, and just a few carry most of the perceptual information. Second, we analyze why this oracle is extremely hard to learn, as it does not consistently coincide with visual cues. Third, we observe that easy videos need fewer tokens to maintain accuracy. We build on these and further insights to propose a lightweight video model we call LITE that can select a small number of tokens effectively, outperforming state-of-the-art and existing baselines across datasets (Kinetics400 and Something-Something-V2) in the challenging trade-off of computation (GFLOPs) vs accuracy.
OPPH: A Vision-Based Operator for Measuring Body Movements for Personal Healthcare
Aug 18, 2024



Vision-based motion estimation methods show promise in accurately and unobtrusively estimating human body motion for healthcare purposes. However, these methods are not specifically designed for healthcare purposes and face challenges in real-world applications. Human pose estimation methods often lack the accuracy needed for detecting fine-grained, subtle body movements, while optical flow-based methods struggle with poor lighting conditions and unseen real-world data. These issues result in human body motion estimation errors, particularly during critical medical situations where the body is motionless, such as during unconsciousness. To address these challenges and improve the accuracy of human body motion estimation for healthcare purposes, we propose the OPPH operator designed to enhance current vision-based motion estimation methods. This operator, which considers human body movement and noise properties, functions as a multi-stage filter. Results tested on two real-world and one synthetic human motion dataset demonstrate that the operator effectively removes real-world noise, significantly enhances the detection of motionless states, maintains the accuracy of estimating active body movements, and maintains long-term body movement trends. This method could be beneficial for analyzing both critical medical events and chronic medical conditions.
Adversarial Augmentation Training Makes Action Recognition Models More Robust to Realistic Video Distribution Shifts
Jan 21, 2024Despite recent advances in video action recognition achieving strong performance on existing benchmarks, these models often lack robustness when faced with natural distribution shifts between training and test data. We propose two novel evaluation methods to assess model resilience to such distribution disparity. One method uses two different datasets collected from different sources and uses one for training and validation, and the other for testing. More precisely, we created dataset splits of HMDB-51 or UCF-101 for training, and Kinetics-400 for testing, using the subset of the classes that are overlapping in both train and test datasets. The other proposed method extracts the feature mean of each class from the target evaluation dataset's training data (i.e. class prototype) and estimates test video prediction as a cosine similarity score between each sample to the class prototypes of each target class. This procedure does not alter model weights using the target dataset and it does not require aligning overlapping classes of two different datasets, thus is a very efficient method to test the model robustness to distribution shifts without prior knowledge of the target distribution. We address the robustness problem by adversarial augmentation training - generating augmented views of videos that are "hard" for the classification model by applying gradient ascent on the augmentation parameters - as well as "curriculum" scheduling the strength of the video augmentations. We experimentally demonstrate the superior performance of the proposed adversarial augmentation approach over baselines across three state-of-the-art action recognition models - TSM, Video Swin Transformer, and Uniformer. The presented work provides critical insight into model robustness to distribution shifts and presents effective techniques to enhance video action recognition performance in a real-world deployment.
RGB-D-based Framework to Acquire, Visualize and Measure the Human Body for Dietetic Treatments
Jul 02, 2020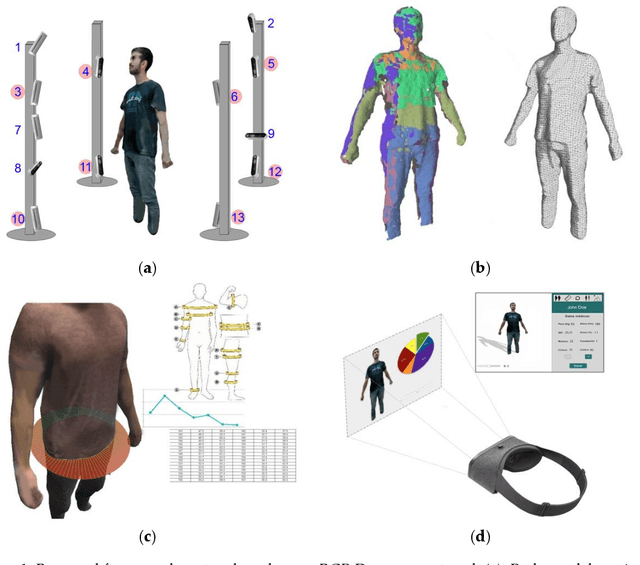
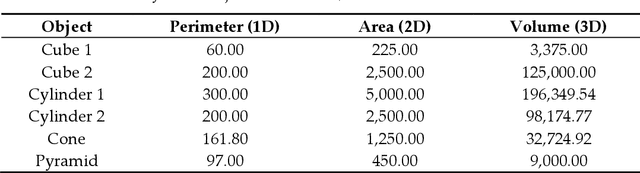

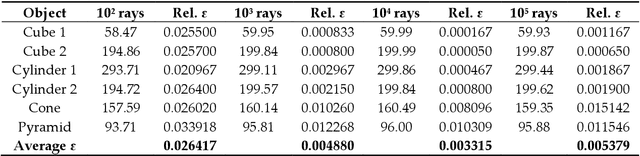
This research aims to improve dietetic-nutritional treatment using state-of-the-art RGB-D sensors and virtual reality (VR) technology. Recent studies show that adherence to treatment can be improved using multimedia technologies. However, there are few studies using 3D data and VR technologies for this purpose. On the other hand, obtaining 3D measurements of the human body and analyzing them over time (4D) in patients undergoing dietary treatment is a challenging field. The main contribution of the work is to provide a framework to study the effect of 4D body model visualization on adherence to obesity treatment. The system can obtain a complete 3D model of a body using low-cost technology, allowing future straightforward transference with sufficient accuracy and realistic visualization, enabling the analysis of the evolution (4D) of the shape during the treatment of obesity. The 3D body models will be used for studying the effect of visualization on adherence to obesity treatment using 2D and VR devices. Moreover, we will use the acquired 3D models to obtain measurements of the body. An analysis of the accuracy of the proposed methods for obtaining measurements with both synthetic and real objects has been carried out.
DUGMA: Dynamic Uncertainty-Based Gaussian Mixture Alignment
Aug 02, 2018


Registering accurately point clouds from a cheap low-resolution sensor is a challenging task. Existing rigid registration methods failed to use the physical 3D uncertainty distribution of each point from a real sensor in the dynamic alignment process mainly because the uncertainty model for a point is static and invariant and it is hard to describe the change of these physical uncertainty models in the registration process. Additionally, the existing Gaussian mixture alignment architecture cannot be efficiently implement these dynamic changes. This paper proposes a simple architecture combining error estimation from sample covariances and dual dynamic global probability alignment using the convolution of uncertainty-based Gaussian Mixture Models (GMM) from point clouds. Firstly, we propose an efficient way to describe the change of each 3D uncertainty model, which represents the structure of the point cloud much better. Unlike the invariant GMM (representing a fixed point cloud) in traditional Gaussian mixture alignment, we use two uncertainty-based GMMs that change and interact with each other in each iteration. In order to have a wider basin of convergence than other local algorithms, we design a more robust energy function by convolving efficiently the two GMMs over the whole 3D space. Tens of thousands of trials have been conducted on hundreds of models from multiple datasets to demonstrate the proposed method's superior performance compared with the current state-of-the-art methods. The new dataset and code is available from https://github.com/Canpu999
Sdf-GAN: Semi-supervised Depth Fusion with Multi-scale Adversarial Networks
Mar 18, 2018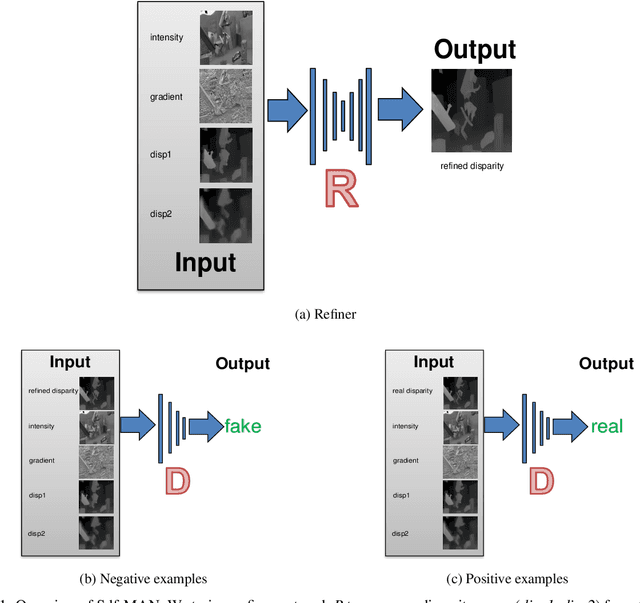
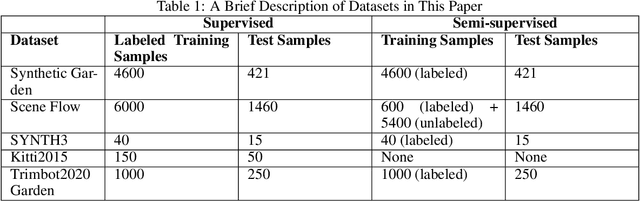
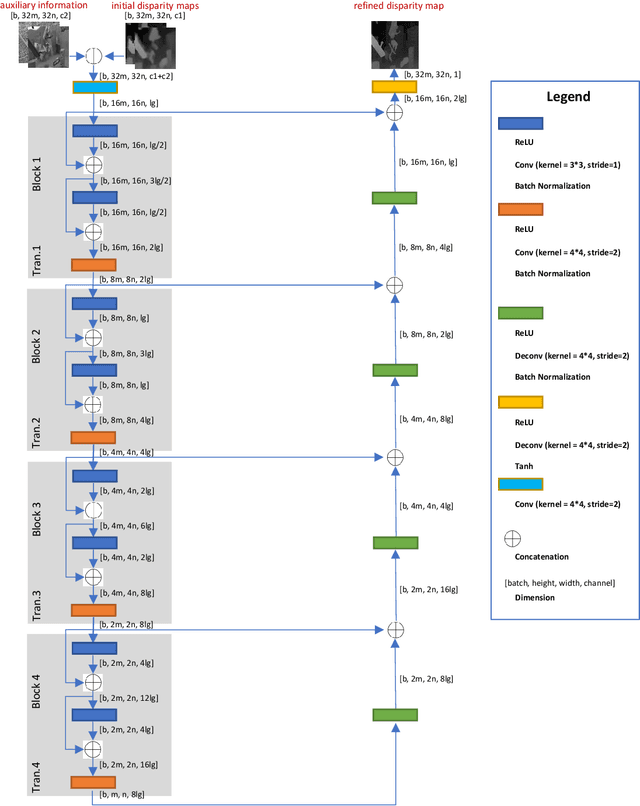
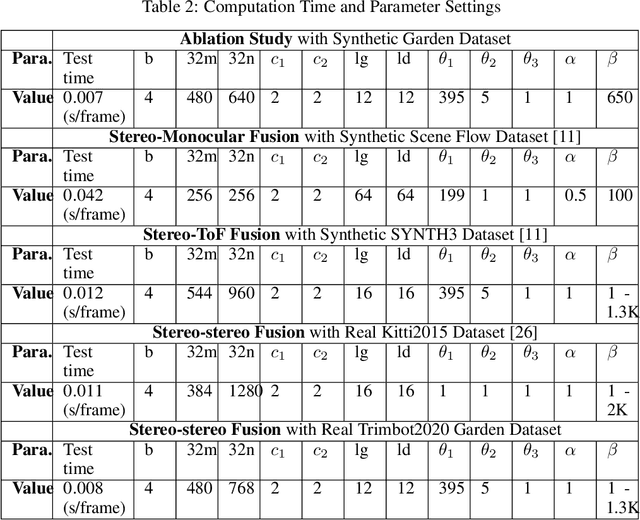
Fusing disparity maps from different algorithms to exploit their complementary advantages is still challenging. Uncertainty estimation and complex disparity relationships between neighboring pixels limit the accuracy and robustness of the existing methods and there is no common method for depth fusion of different kind of data. In this paper, we introduce a method to incorporate supplementary information (intensity, gradient constraints etc.) into a Generative Adversarial Network to better refine each input disparity value. By adopting a multi-scale strategy, the disparity relationship in the fused disparity map is a better estimate of the real distribution. The approach includes a more robust object function to avoid blurry edges, impaints invalid disparity values and requires much fewer ground data to train. The algorithm can be generalized to different kinds of depth fusion. The experiments were conducted through simulation and real data, exploring different fusion opportunities: stereo-monocular fusion from coarse input, stereo-stereo fusion from moderately accurate input, fusion from accurate binocular input and Time of Flight sensor. The experiments show the superiority of the proposed algorithm compared with the most recent algorithms on the public Scene Flow and SYNTH3 datasets. The code is available from https://github.com/Canpu999
Robust Rigid Point Registration based on Convolution of Adaptive Gaussian Mixture Models
Jul 26, 2017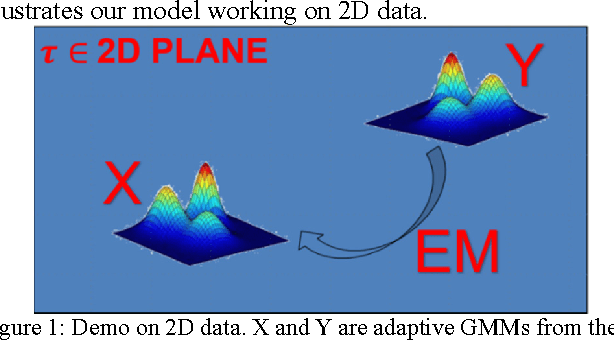
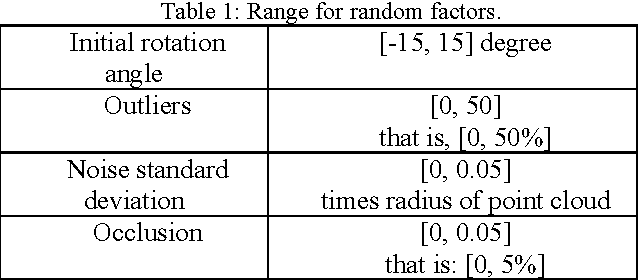

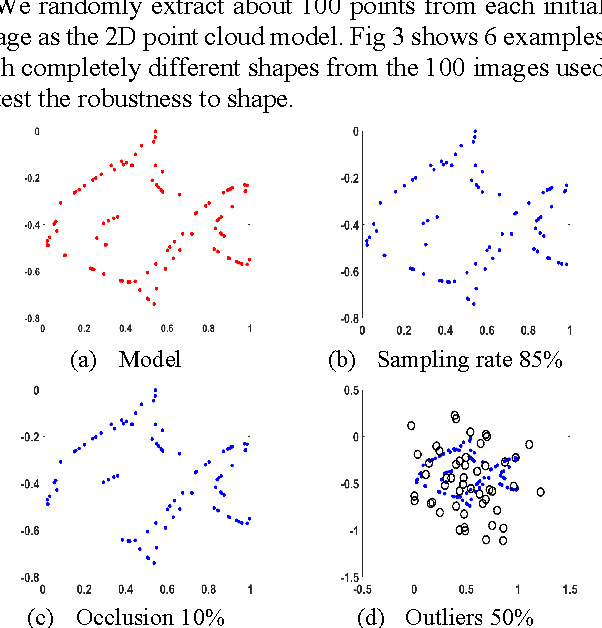
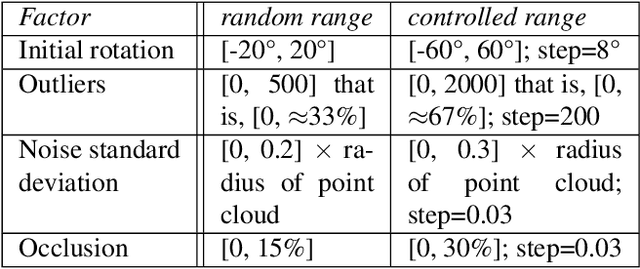
Matching 3D rigid point clouds in complex environments robustly and accurately is still a core technique used in many applications. This paper proposes a new architecture combining error estimation from sample covariances and dual global probability alignment based on the convolution of adaptive Gaussian Mixture Models (GMM) from point clouds. Firstly, a novel adaptive GMM is defined using probability distributions from the corresponding points. Then rigid point cloud alignment is performed by maximizing the global probability from the convolution of dual adaptive GMMs in the whole 2D or 3D space, which can be efficiently optimized and has a large zone of accurate convergence. Thousands of trials have been conducted on 200 models from public 2D and 3D datasets to demonstrate superior robustness and accuracy in complex environments with unpredictable noise, outliers, occlusion, initial rotation, shape and missing points.