 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSockpuppetting: Jailbreaking LLMs Without Optimization Through Output Prefix Injection
Jan 19, 2026As open-weight large language models (LLMs) increase in capabilities, safeguarding them against malicious prompts and understanding possible attack vectors becomes ever more important. While automated jailbreaking methods like GCG [Zou et al., 2023] remain effective, they often require substantial computational resources and specific expertise. We introduce "sockpuppetting'', a simple method for jailbreaking open-weight LLMs by inserting an acceptance sequence (e.g., "Sure, here is how to...'') at the start of a model's output and allowing it to complete the response. Requiring only a single line of code and no optimization, sockpuppetting achieves up to 80% higher attack success rate (ASR) than GCG on Qwen3-8B in per-prompt comparisons. We also explore a hybrid approach that optimizes the adversarial suffix within the assistant message block rather than the user prompt, increasing ASR by 64% over GCG on Llama-3.1-8B in a prompt-agnostic setting. The results establish sockpuppetting as an effective low-cost attack accessible to unsophisticated adversaries, highlighting the need for defences against output-prefix injection in open-weight models.
Unsupervised Corpus Poisoning Attacks in Continuous Space for Dense Retrieval
Apr 24, 2025This paper concerns corpus poisoning attacks in dense information retrieval, where an adversary attempts to compromise the ranking performance of a search algorithm by injecting a small number of maliciously generated documents into the corpus. Our work addresses two limitations in the current literature. First, attacks that perform adversarial gradient-based word substitution search do so in the discrete lexical space, while retrieval itself happens in the continuous embedding space. We thus propose an optimization method that operates in the embedding space directly. Specifically, we train a perturbation model with the objective of maintaining the geometric distance between the original and adversarial document embeddings, while also maximizing the token-level dissimilarity between the original and adversarial documents. Second, it is common for related work to have a strong assumption that the adversary has prior knowledge about the queries. In this paper, we focus on a more challenging variant of the problem where the adversary assumes no prior knowledge about the query distribution (hence, unsupervised). Our core contribution is an adversarial corpus attack that is fast and effective. We present comprehensive experimental results on both in- and out-of-domain datasets, focusing on two related tasks: a top-1 attack and a corpus poisoning attack. We consider attacks under both a white-box and a black-box setting. Notably, our method can generate successful adversarial examples in under two minutes per target document; four times faster compared to the fastest gradient-based word substitution methods in the literature with the same hardware. Furthermore, our adversarial generation method generates text that is more likely to occur under the distribution of natural text (low perplexity), and is therefore more difficult to detect.
Information Leakage of Sentence Embeddings via Generative Embedding Inversion Attacks
Apr 23, 2025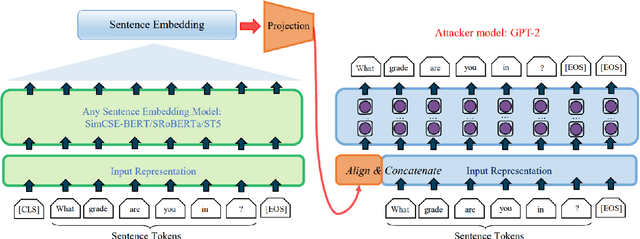

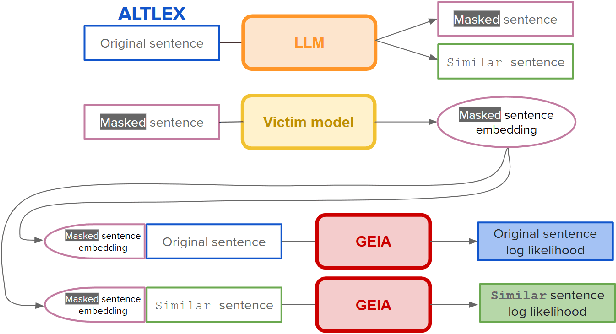
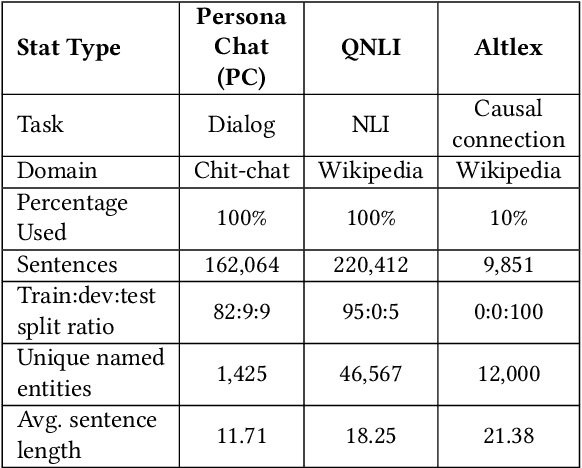
Text data are often encoded as dense vectors, known as embeddings, which capture semantic, syntactic, contextual, and domain-specific information. These embeddings, widely adopted in various applications, inherently contain rich information that may be susceptible to leakage under certain attacks. The GEIA framework highlights vulnerabilities in sentence embeddings, demonstrating that they can reveal the original sentences they represent. In this study, we reproduce GEIA's findings across various neural sentence embedding models. Additionally, we contribute new analysis to examine whether these models leak sensitive information from their training datasets. We propose a simple yet effective method without any modification to the attacker's architecture proposed in GEIA. The key idea is to examine differences between log-likelihood for masked and original variants of data that sentence embedding models have been pre-trained on, calculated on the embedding space of the attacker. Our findings indicate that following our approach, an adversary party can recover meaningful sensitive information related to the pre-training knowledge of the popular models used for creating sentence embeddings, seriously undermining their security. Our code is available on: https://github.com/taslanidis/GEIA
Agent-centric Information Access
Feb 26, 2025As large language models (LLMs) become more specialized, we envision a future where millions of expert LLMs exist, each trained on proprietary data and excelling in specific domains. In such a system, answering a query requires selecting a small subset of relevant models, querying them efficiently, and synthesizing their responses. This paper introduces a framework for agent-centric information access, where LLMs function as knowledge agents that are dynamically ranked and queried based on their demonstrated expertise. Unlike traditional document retrieval, this approach requires inferring expertise on the fly, rather than relying on static metadata or predefined model descriptions. This shift introduces several challenges, including efficient expert selection, cost-effective querying, response aggregation across multiple models, and robustness against adversarial manipulation. To address these issues, we propose a scalable evaluation framework that leverages retrieval-augmented generation and clustering techniques to construct and assess thousands of specialized models, with the potential to scale toward millions.
Reproducing HotFlip for Corpus Poisoning Attacks in Dense Retrieval
Jan 08, 2025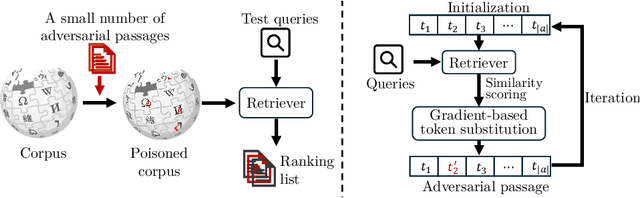
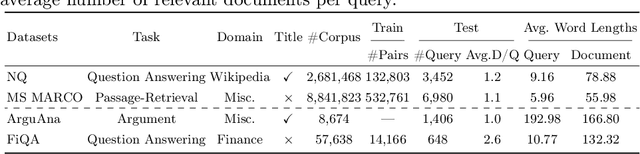
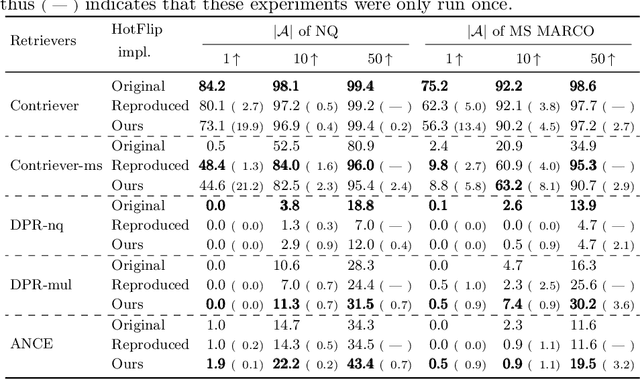
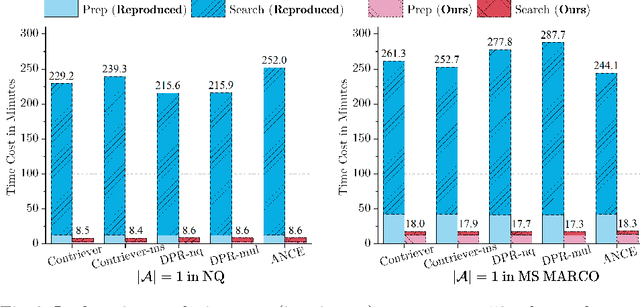
HotFlip is a topical gradient-based word substitution method for attacking language models. Recently, this method has been further applied to attack retrieval systems by generating malicious passages that are injected into a corpus, i.e., corpus poisoning. However, HotFlip is known to be computationally inefficient, with the majority of time being spent on gradient accumulation for each query-passage pair during the adversarial token generation phase, making it impossible to generate an adequate number of adversarial passages in a reasonable amount of time. Moreover, the attack method itself assumes access to a set of user queries, a strong assumption that does not correspond to how real-world adversarial attacks are usually performed. In this paper, we first significantly boost the efficiency of HotFlip, reducing the adversarial generation process from 4 hours per document to only 15 minutes, using the same hardware. We further contribute experiments and analysis on two additional tasks: (1) transfer-based black-box attacks, and (2) query-agnostic attacks. Whenever possible, we provide comparisons between the original method and our improved version. Our experiments demonstrate that HotFlip can effectively attack a variety of dense retrievers, with an observed trend that its attack performance diminishes against more advanced and recent methods. Interestingly, we observe that while HotFlip performs poorly in a black-box setting, indicating limited capacity for generalization, in query-agnostic scenarios its performance is correlated to the volume of injected adversarial passages.
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models
Jun 28, 2024



Following multiple instructions is a crucial ability for large language models (LLMs). Evaluating this ability comes with significant challenges: (i) limited coherence between multiple instructions, (ii) positional bias where the order of instructions affects model performance, and (iii) a lack of objectively verifiable tasks. To address these issues, we introduce a benchmark designed to evaluate models' abilities to follow multiple instructions through sequential instruction following (SIFo) tasks. In SIFo, the successful completion of multiple instructions is verifiable by examining only the final instruction. Our benchmark evaluates instruction following using four tasks (text modification, question answering, mathematics, and security rule following), each assessing different aspects of sequential instruction following. Our evaluation of popular LLMs, both closed-source and open-source, shows that more recent and larger models significantly outperform their older and smaller counterparts on the SIFo tasks, validating the benchmark's effectiveness. All models struggle with following sequences of instructions, hinting at an important lack of robustness of today's language models.
Adversarial Augmentation Training Makes Action Recognition Models More Robust to Realistic Video Distribution Shifts
Jan 21, 2024Despite recent advances in video action recognition achieving strong performance on existing benchmarks, these models often lack robustness when faced with natural distribution shifts between training and test data. We propose two novel evaluation methods to assess model resilience to such distribution disparity. One method uses two different datasets collected from different sources and uses one for training and validation, and the other for testing. More precisely, we created dataset splits of HMDB-51 or UCF-101 for training, and Kinetics-400 for testing, using the subset of the classes that are overlapping in both train and test datasets. The other proposed method extracts the feature mean of each class from the target evaluation dataset's training data (i.e. class prototype) and estimates test video prediction as a cosine similarity score between each sample to the class prototypes of each target class. This procedure does not alter model weights using the target dataset and it does not require aligning overlapping classes of two different datasets, thus is a very efficient method to test the model robustness to distribution shifts without prior knowledge of the target distribution. We address the robustness problem by adversarial augmentation training - generating augmented views of videos that are "hard" for the classification model by applying gradient ascent on the augmentation parameters - as well as "curriculum" scheduling the strength of the video augmentations. We experimentally demonstrate the superior performance of the proposed adversarial augmentation approach over baselines across three state-of-the-art action recognition models - TSM, Video Swin Transformer, and Uniformer. The presented work provides critical insight into model robustness to distribution shifts and presents effective techniques to enhance video action recognition performance in a real-world deployment.
Neural Fine-Tuning Search for Few-Shot Learning
Jun 15, 2023



In few-shot recognition, a classifier that has been trained on one set of classes is required to rapidly adapt and generalize to a disjoint, novel set of classes. To that end, recent studies have shown the efficacy of fine-tuning with carefully crafted adaptation architectures. However this raises the question of: How can one design the optimal adaptation strategy? In this paper, we study this question through the lens of neural architecture search (NAS). Given a pre-trained neural network, our algorithm discovers the optimal arrangement of adapters, which layers to keep frozen and which to fine-tune. We demonstrate the generality of our NAS method by applying it to both residual networks and vision transformers and report state-of-the-art performance on Meta-Dataset and Meta-Album.
Attacking Adversarial Defences by Smoothing the Loss Landscape
Aug 05, 2022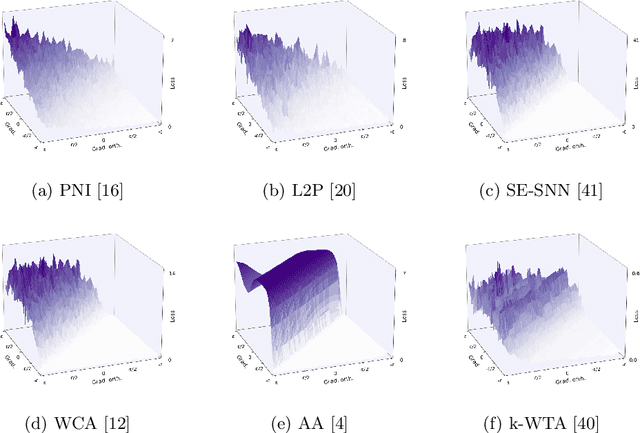
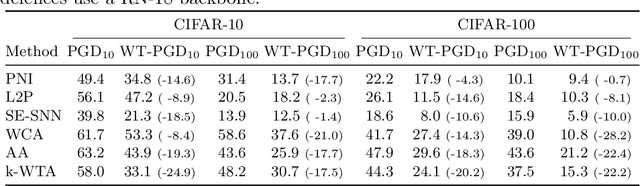
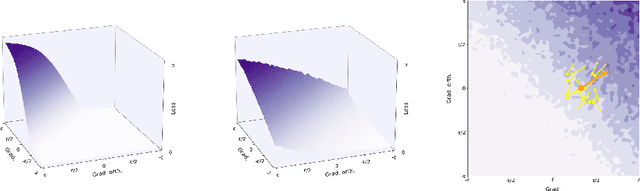
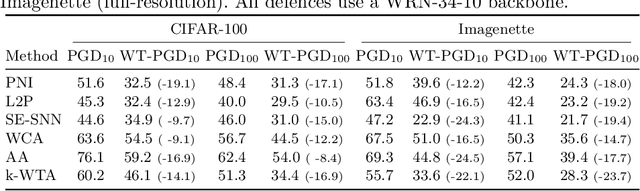
This paper investigates a family of methods for defending against adversarial attacks that owe part of their success to creating a noisy, discontinuous, or otherwise rugged loss landscape that adversaries find difficult to navigate. A common, but not universal, way to achieve this effect is via the use of stochastic neural networks. We show that this is a form of gradient obfuscation, and propose a general extension to gradient-based adversaries based on the Weierstrass transform, which smooths the surface of the loss function and provides more reliable gradient estimates. We further show that the same principle can strengthen gradient-free adversaries. We demonstrate the efficacy of our loss-smoothing method against both stochastic and non-stochastic adversarial defences that exhibit robustness due to this type of obfuscation. Furthermore, we provide analysis of how it interacts with Expectation over Transformation; a popular gradient-sampling method currently used to attack stochastic defences.
A Stochastic Neural Network for Attack-Agnostic Adversarial Robustness
Oct 17, 2020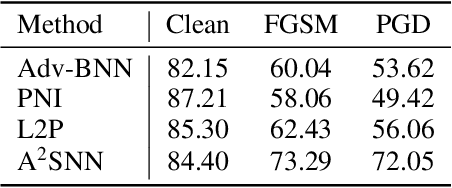
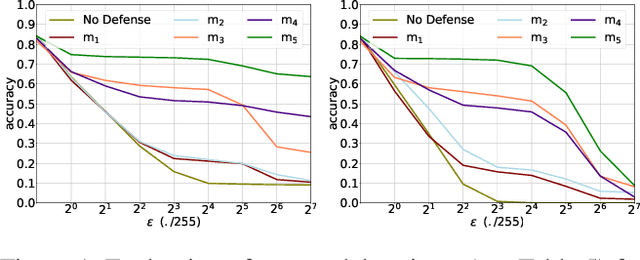
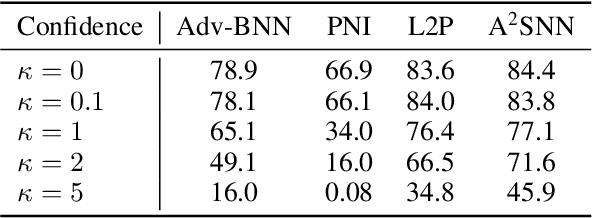
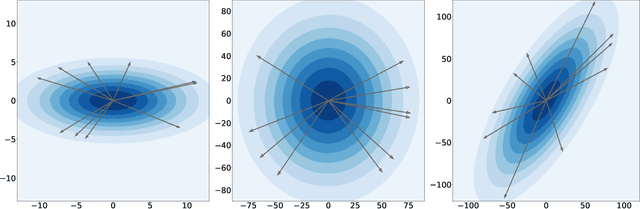
Stochastic Neural Networks (SNNs) that inject noise into their hidden layers have recently been shown to achieve strong robustness against adversarial attacks. However, existing SNNs are usually heuristically motivated, and further rely on adversarial training, which is computationally costly and biases models' defense towards a specific attack. We propose a new SNN that achieves state-of-the-art performance without relying on adversarial training, and enjoys solid theoretical justification. Specifically, while existing SNNs inject learned or hand-tuned isotropic noise, our SNN learns an anisotropic noise distribution to optimize a learning-theoretic bound on adversarial robustness. We evaluate our method on three benchmarks (CIFAR-10, SVHN, F-MNIST), show that it can be applied to different architectures (ResNet-18, LeNet++), and that it provides robustness to a variety of white-box and black-box attacks, while being simple and fast to train compared to existing alternatives. The source code is openly available on GitHub: https://github.com/peustr/A2SNN.