 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALBA : Reinforcement Learning for Video Object Segmentation
Paper and Code

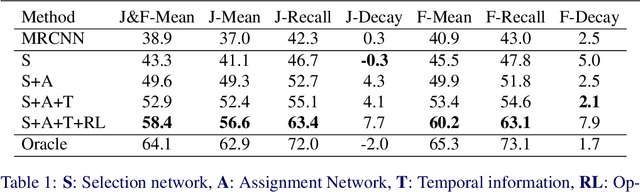
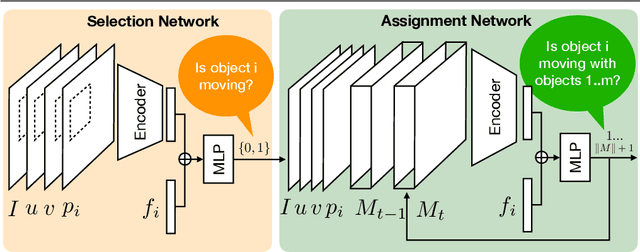
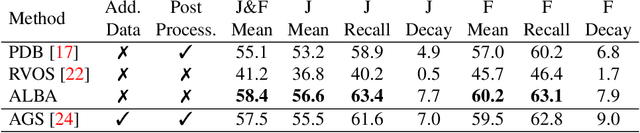
We consider the challenging problem of zero-shot video object segmentation (VOS). That is, segmenting and tracking multiple moving objects within a video fully automatically, without any manual initialization. We treat this as a grouping problem by exploiting object proposals and making a joint inference about grouping over both space and time. We propose a network architecture for tractably performing proposal selection and joint grouping. Crucially, we then show how to train this network with reinforcement learning so that it learns to perform the optimal non-myopic sequence of grouping decisions to segment the whole video. Unlike standard supervised techniques, this also enables us to directly optimize for the non-differentiable overlap-based metrics used to evaluate VOS. We show that the proposed method, which we call ALBA outperforms the previous stateof-the-art on three benchmarks: DAVIS 2017 [2], FBMS [20] and Youtube-VOS [27].