 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-centric Information Access
Feb 26, 2025As large language models (LLMs) become more specialized, we envision a future where millions of expert LLMs exist, each trained on proprietary data and excelling in specific domains. In such a system, answering a query requires selecting a small subset of relevant models, querying them efficiently, and synthesizing their responses. This paper introduces a framework for agent-centric information access, where LLMs function as knowledge agents that are dynamically ranked and queried based on their demonstrated expertise. Unlike traditional document retrieval, this approach requires inferring expertise on the fly, rather than relying on static metadata or predefined model descriptions. This shift introduces several challenges, including efficient expert selection, cost-effective querying, response aggregation across multiple models, and robustness against adversarial manipulation. To address these issues, we propose a scalable evaluation framework that leverages retrieval-augmented generation and clustering techniques to construct and assess thousands of specialized models, with the potential to scale toward millions.
Table Question Answering for Low-resourced Indic Languages
Oct 04, 2024



TableQA is the task of answering questions over tables of structured information, returning individual cells or tables as output. TableQA research has focused primarily on high-resource languages, leaving medium- and low-resource languages with little progress due to scarcity of annotated data and neural models. We address this gap by introducing a fully automatic large-scale tableQA data generation process for low-resource languages with limited budget. We incorporate our data generation method on two Indic languages, Bengali and Hindi, which have no tableQA datasets or models. TableQA models trained on our large-scale datasets outperform state-of-the-art LLMs. We further study the trained models on different aspects, including mathematical reasoning capabilities and zero-shot cross-lingual transfer. Our work is the first on low-resource tableQA focusing on scalable data generation and evaluation procedures. Our proposed data generation method can be applied to any low-resource language with a web presence. We release datasets, models, and code (https://github.com/kolk/Low-Resource-TableQA-Indic-languages).
QFMTS: Generating Query-Focused Summaries over Multi-Table Inputs
May 08, 2024Table summarization is a crucial task aimed at condensing information from tabular data into concise and comprehensible textual summaries. However, existing approaches often fall short of adequately meeting users' information and quality requirements and tend to overlook the complexities of real-world queries. In this paper, we propose a novel method to address these limitations by introducing query-focused multi-table summarization. Our approach, which comprises a table serialization module, a summarization controller, and a large language model (LLM), utilizes textual queries and multiple tables to generate query-dependent table summaries tailored to users' information needs. To facilitate research in this area, we present a comprehensive dataset specifically tailored for this task, consisting of 4909 query-summary pairs, each associated with multiple tables. Through extensive experiments using our curated dataset, we demonstrate the effectiveness of our proposed method compared to baseline approaches. Our findings offer insights into the challenges of complex table reasoning for precise summarization, contributing to the advancement of research in query-focused multi-table summarization.
MultiTabQA: Generating Tabular Answers for Multi-Table Question Answering
May 24, 2023


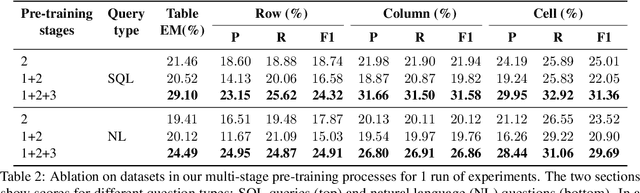
Recent advances in tabular question answering (QA) with large language models are constrained in their coverage and only answer questions over a single table. However, real-world queries are complex in nature, often over multiple tables in a relational database or web page. Single table questions do not involve common table operations such as set operations, Cartesian products (joins), or nested queries. Furthermore, multi-table operations often result in a tabular output, which necessitates table generation capabilities of tabular QA models. To fill this gap, we propose a new task of answering questions over multiple tables. Our model, MultiTabQA, not only answers questions over multiple tables, but also generalizes to generate tabular answers. To enable effective training, we build a pre-training dataset comprising of 132,645 SQL queries and tabular answers. Further, we evaluate the generated tables by introducing table-specific metrics of varying strictness assessing various levels of granularity of the table structure. MultiTabQA outperforms state-of-the-art single table QA models adapted to a multi-table QA setting by finetuning on three datasets: Spider, Atis and GeoQuery.
Parameter-Efficient Sparse Retrievers and Rerankers using Adapters
Mar 23, 2023Parameter-Efficient transfer learning with Adapters have been studied in Natural Language Processing (NLP) as an alternative to full fine-tuning. Adapters are memory-efficient and scale well with downstream tasks by training small bottle-neck layers added between transformer layers while keeping the large pretrained language model (PLMs) frozen. In spite of showing promising results in NLP, these methods are under-explored in Information Retrieval. While previous studies have only experimented with dense retriever or in a cross lingual retrieval scenario, in this paper we aim to complete the picture on the use of adapters in IR. First, we study adapters for SPLADE, a sparse retriever, for which adapters not only retain the efficiency and effectiveness otherwise achieved by finetuning, but are memory-efficient and orders of magnitude lighter to train. We observe that Adapters-SPLADE not only optimizes just 2\% of training parameters, but outperforms fully fine-tuned counterpart and existing parameter-efficient dense IR models on IR benchmark datasets. Secondly, we address domain adaptation of neural retrieval thanks to adapters on cross-domain BEIR datasets and TripClick. Finally, we also consider knowledge sharing between rerankers and first stage rankers. Overall, our study complete the examination of adapters for neural IR
Parameter-Efficient Abstractive Question Answering over Tables or Text
Apr 07, 2022
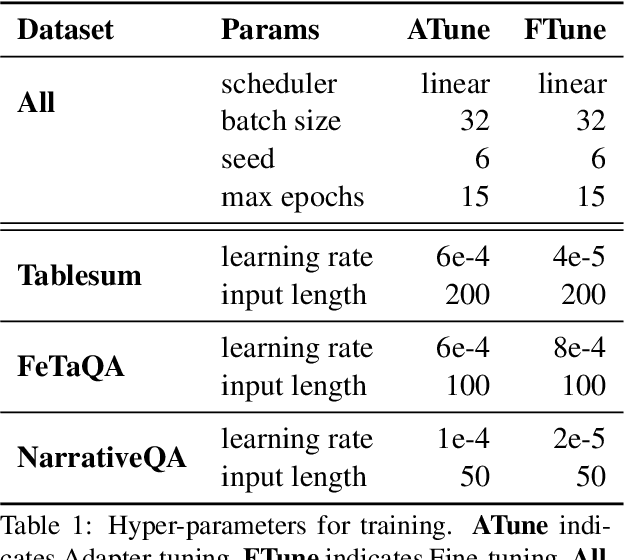


A long-term ambition of information seeking QA systems is to reason over multi-modal contexts and generate natural answers to user queries. Today, memory intensive pre-trained language models are adapted to downstream tasks such as QA by fine-tuning the model on QA data in a specific modality like unstructured text or structured tables. To avoid training such memory-hungry models while utilizing a uniform architecture for each modality, parameter-efficient adapters add and train small task-specific bottle-neck layers between transformer layers. In this work, we study parameter-efficient abstractive QA in encoder-decoder models over structured tabular data and unstructured textual data using only 1.5% additional parameters for each modality. We also ablate over adapter layers in both encoder and decoder modules to study the efficiency-performance trade-off and demonstrate that reducing additional trainable parameters down to 0.7%-1.0% leads to comparable results. Our models out-perform current state-of-the-art models on tabular QA datasets such as Tablesum and FeTaQA, and achieve comparable performance on a textual QA dataset such as NarrativeQA using significantly less trainable parameters than fine-tuning.
ConfNet2Seq: Full Length Answer Generation from Spoken Questions
Jun 11, 2020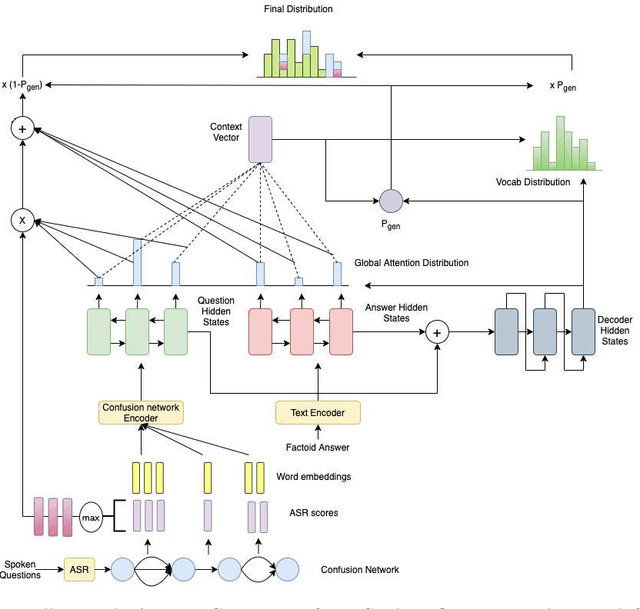

Conversational and task-oriented dialogue systems aim to interact with the user using natural responses through multi-modal interfaces, such as text or speech. These desired responses are in the form of full-length natural answers generated over facts retrieved from a knowledge source. While the task of generating natural answers to questions from an answer span has been widely studied, there has been little research on natural sentence generation over spoken content. We propose a novel system to generate full length natural language answers from spoken questions and factoid answers. The spoken sequence is compactly represented as a confusion network extracted from a pre-trained Automatic Speech Recognizer. This is the first attempt towards generating full-length natural answers from a graph input(confusion network) to the best of our knowledge. We release a large-scale dataset of 259,788 samples of spoken questions, their factoid answers and corresponding full-length textual answers. Following our proposed approach, we achieve comparable performance with best ASR hypothesis.
Modeling ASR Ambiguity for Dialogue State Tracking Using Word Confusion Networks
Feb 03, 2020



Spoken dialogue systems typically use a list of top-N ASR hypotheses for inferring the semantic meaning and tracking the state of the dialogue. However ASR graphs, such as confusion networks (confnets), provide a compact representation of a richer hypothesis space than a top-N ASR list. In this paper, we study the benefits of using confusion networks with a state-of-the-art neural dialogue state tracker (DST). We encode the 2-dimensional confnet into a 1-dimensional sequence of embeddings using an attentional confusion network encoder which can be used with any DST system. Our confnet encoder is plugged into the state-of-the-art 'Global-locally Self-Attentive Dialogue State Tacker' (GLAD) model for DST and obtains significant improvements in both accuracy and inference time compared to using top-N ASR hypotheses.