 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLATE: Sparse Late Interaction Retrieval
Apr 22, 2024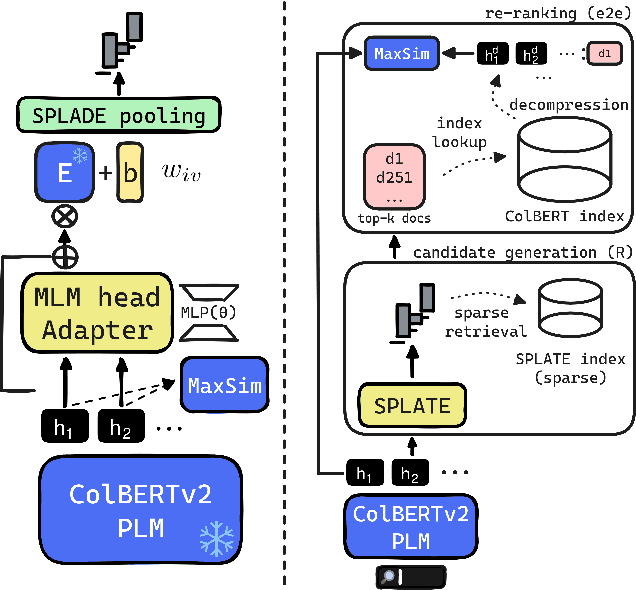
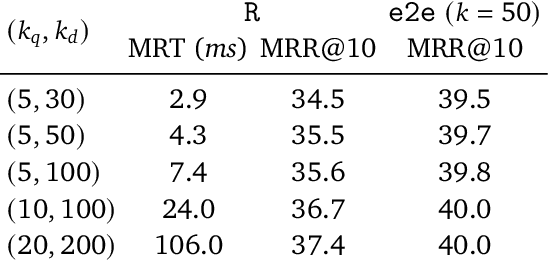
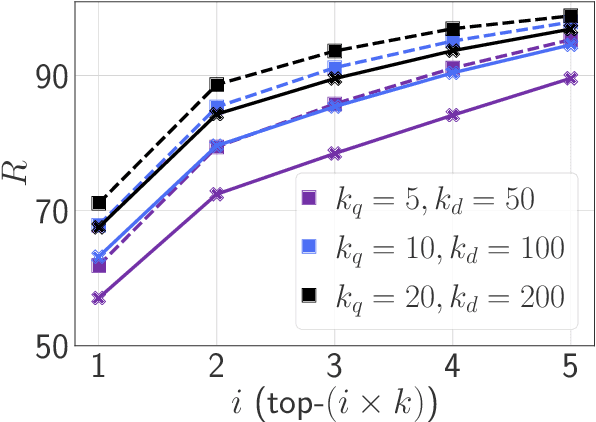
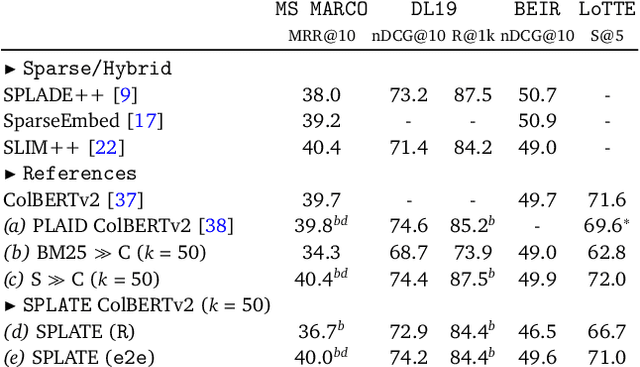
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
Two-Step SPLADE: Simple, Efficient and Effective Approximation of SPLADE
Apr 20, 2024Learned sparse models such as SPLADE have successfully shown how to incorporate the benefits of state-of-the-art neural information retrieval models into the classical inverted index data structure. Despite their improvements in effectiveness, learned sparse models are not as efficient as classical sparse model such as BM25. The problem has been investigated and addressed by recently developed strategies, such as guided traversal query processing and static pruning, with different degrees of success on in-domain and out-of-domain datasets. In this work, we propose a new query processing strategy for SPLADE based on a two-step cascade. The first step uses a pruned and reweighted version of the SPLADE sparse vectors, and the second step uses the original SPLADE vectors to re-score a sample of documents retrieved in the first stage. Our extensive experiments, performed on 30 different in-domain and out-of-domain datasets, show that our proposed strategy is able to improve mean and tail response times over the original single-stage SPLADE processing by up to $30\times$ and $40\times$, respectively, for in-domain datasets, and by 12x to 25x, for mean response on out-of-domain datasets, while not incurring in statistical significant difference in 60\% of datasets.
SPLADE-v3: New baselines for SPLADE
Mar 11, 2024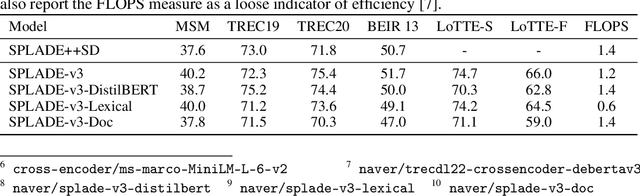
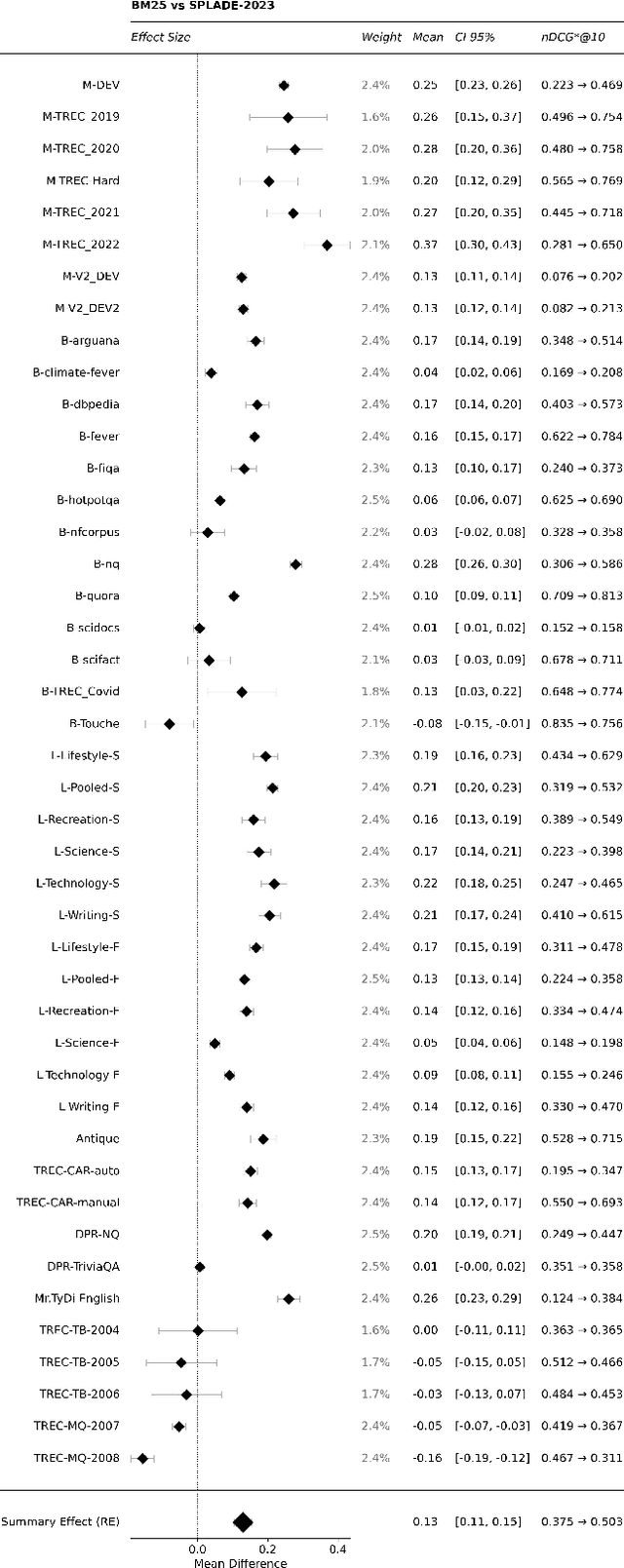
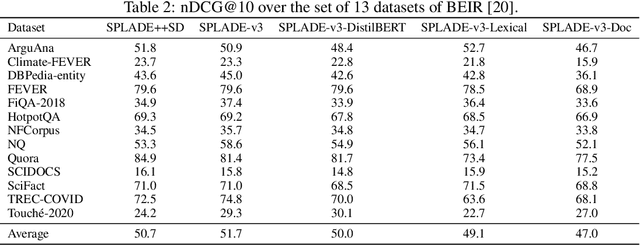
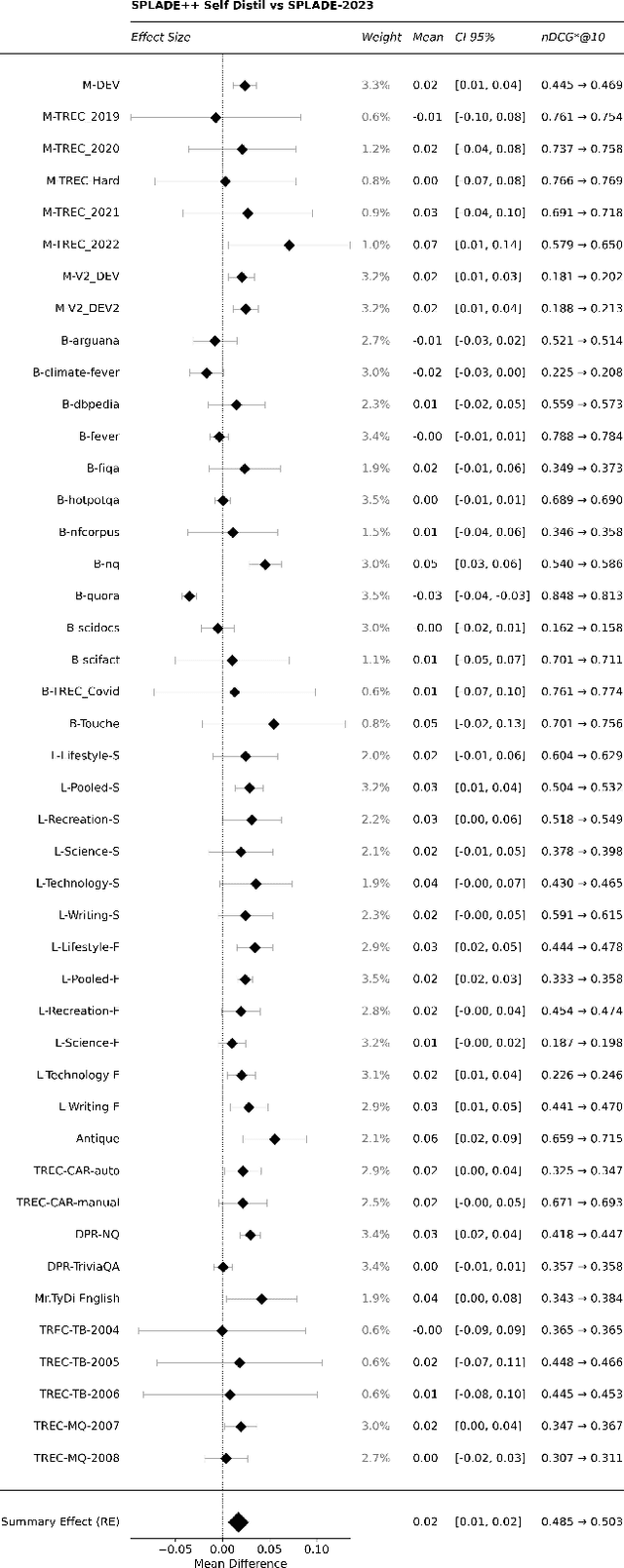
A companion to the release of the latest version of the SPLADE library. We describe changes to the training structure and present our latest series of models -- SPLADE-v3. We compare this new version to BM25, SPLADE++, as well as re-rankers, and showcase its effectiveness via a meta-analysis over more than 40 query sets. SPLADE-v3 further pushes the limit of SPLADE models: it is statistically significantly more effective than both BM25 and SPLADE++, while comparing well to cross-encoder re-rankers. Specifically, it gets more than 40 MRR@10 on the MS MARCO dev set, and improves by 2% the out-of-domain results on the BEIR benchmark.
End-to-End Retrieval with Learned Dense and Sparse Representations Using Lucene
Nov 30, 2023The bi-encoder architecture provides a framework for understanding machine-learned retrieval models based on dense and sparse vector representations. Although these representations capture parametric realizations of the same underlying conceptual framework, their respective implementations of top-$k$ similarity search require the coordination of different software components (e.g., inverted indexes, HNSW indexes, and toolkits for neural inference), often knitted together in complex architectures. In this work, we ask the following question: What's the simplest design, in terms of requiring the fewest changes to existing infrastructure, that can support end-to-end retrieval with modern dense and sparse representations? The answer appears to be that Lucene is sufficient, as we demonstrate in Anserini, a toolkit for reproducible information retrieval research. That is, effective retrieval with modern single-vector neural models can be efficiently performed directly in Java on the CPU. We examine the implications of this design for information retrieval researchers pushing the state of the art as well as for software engineers building production search systems.
Resources for Brewing BEIR: Reproducible Reference Models and an Official Leaderboard
Jun 13, 2023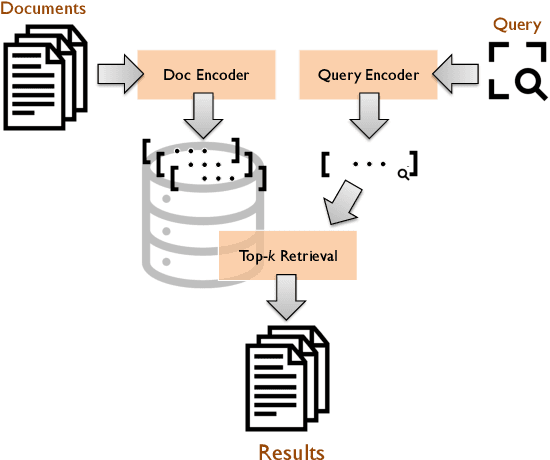
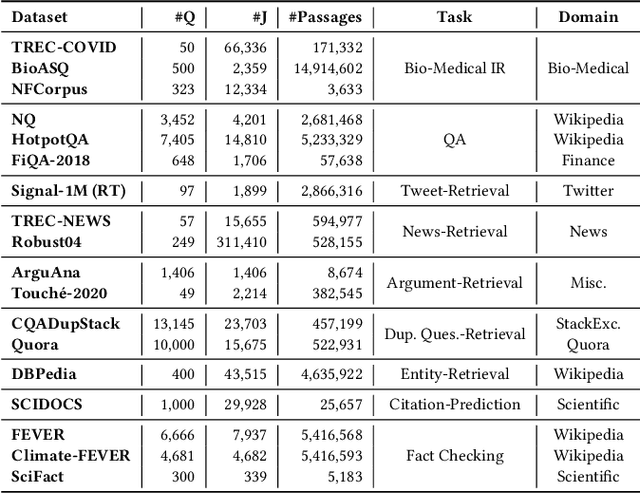

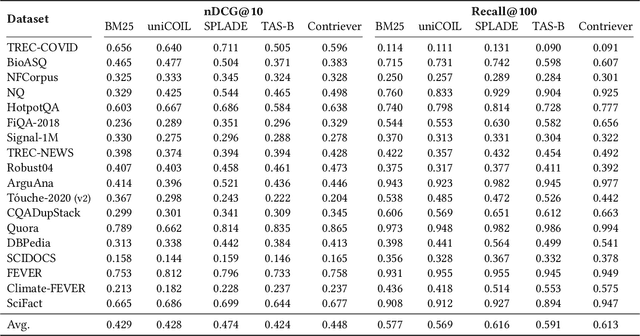
BEIR is a benchmark dataset for zero-shot evaluation of information retrieval models across 18 different domain/task combinations. In recent years, we have witnessed the growing popularity of a representation learning approach to building retrieval models, typically using pretrained transformers in a supervised setting. This naturally begs the question: How effective are these models when presented with queries and documents that differ from the training data? Examples include searching in different domains (e.g., medical or legal text) and with different types of queries (e.g., keywords vs. well-formed questions). While BEIR was designed to answer these questions, our work addresses two shortcomings that prevent the benchmark from achieving its full potential: First, the sophistication of modern neural methods and the complexity of current software infrastructure create barriers to entry for newcomers. To this end, we provide reproducible reference implementations that cover the two main classes of approaches: learned dense and sparse models. Second, there does not exist a single authoritative nexus for reporting the effectiveness of different models on BEIR, which has led to difficulty in comparing different methods. To remedy this, we present an official self-service BEIR leaderboard that provides fair and consistent comparisons of retrieval models. By addressing both shortcomings, our work facilitates future explorations in a range of interesting research questions that BEIR enables.
Benchmarking Middle-Trained Language Models for Neural Search
Jun 05, 2023Middle training methods aim to bridge the gap between the Masked Language Model (MLM) pre-training and the final finetuning for retrieval. Recent models such as CoCondenser, RetroMAE, and LexMAE argue that the MLM task is not sufficient enough to pre-train a transformer network for retrieval and hence propose various tasks to do so. Intrigued by those novel methods, we noticed that all these models used different finetuning protocols, making it hard to assess the benefits of middle training. We propose in this paper a benchmark of CoCondenser, RetroMAE, and LexMAE, under the same finetuning conditions. We compare both dense and sparse approaches under various finetuning protocols and middle training on different collections (MS MARCO, Wikipedia or Tripclick). We use additional middle training baselines, such as a standard MLM finetuning on the retrieval collection, optionally augmented by a CLS predicting the passage term frequency. For the sparse approach, our study reveals that there is almost no statistical difference between those methods: the more effective the finetuning procedure is, the less difference there is between those models. For the dense approach, RetroMAE using MS MARCO as middle-training collection shows excellent results in almost all the settings. Finally, we show that middle training on the retrieval collection, thus adapting the language model to it, is a critical factor. Overall, a better experimental setup should be adopted to evaluate middle training methods. Code available at https://github.com/naver/splade/tree/benchmarch-SIGIR23
The tale of two MS MARCO -- and their unfair comparisons
Apr 25, 2023The MS MARCO-passage dataset has been the main large-scale dataset open to the IR community and it has fostered successfully the development of novel neural retrieval models over the years. But, it turns out that two different corpora of MS MARCO are used in the literature, the official one and a second one where passages were augmented with titles, mostly due to the introduction of the Tevatron code base. However, the addition of titles actually leaks relevance information, while breaking the original guidelines of the MS MARCO-passage dataset. In this work, we investigate the differences between the two corpora and demonstrate empirically that they make a significant difference when evaluating a new method. In other words, we show that if a paper does not properly report which version is used, reproducing fairly its results is basically impossible. Furthermore, given the current status of reviewing, where monitoring state-of-the-art results is of great importance, having two different versions of a dataset is a large problem. This is why this paper aims to report the importance of this issue so that researchers can be made aware of this problem and appropriately report their results.
A Static Pruning Study on Sparse Neural Retrievers
Apr 25, 2023Sparse neural retrievers, such as DeepImpact, uniCOIL and SPLADE, have been introduced recently as an efficient and effective way to perform retrieval with inverted indexes. They aim to learn term importance and, in some cases, document expansions, to provide a more effective document ranking compared to traditional bag-of-words retrieval models such as BM25. However, these sparse neural retrievers have been shown to increase the computational costs and latency of query processing compared to their classical counterparts. To mitigate this, we apply a well-known family of techniques for boosting the efficiency of query processing over inverted indexes: static pruning. We experiment with three static pruning strategies, namely document-centric, term-centric and agnostic pruning, and we assess, over diverse datasets, that these techniques still work with sparse neural retrievers. In particular, static pruning achieves $2\times$ speedup with negligible effectiveness loss ($\leq 2\%$ drop) and, depending on the use case, even $4\times$ speedup with minimal impact on the effectiveness ($\leq 8\%$ drop). Moreover, we show that neural rerankers are robust to candidates from statically pruned indexes.
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023



This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.