 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXProvence: Zero-Cost Multilingual Context Pruning for Retrieval-Augmented Generation
Jan 26, 2026This paper introduces XProvence, a multilingual zero-cost context pruning model for retrieval-augmented generation (RAG), trained on 16 languages and supporting 100+ languages through effective cross-lingual transfer. Motivated by the growing use of RAG systems across diverse languages, we explore several strategies to generalize the Provence framework-which first integrated efficient zero-cost context pruning directly into the re-ranking model-beyond English. Across four multilingual question answering benchmarks, we show how XProvence can prune RAG contexts with minimal-to-no performance degradation and outperforms strong baselines. Our model is available at https://huggingface.co/naver/xprovence-reranker-bgem3-v2.
Provence: efficient and robust context pruning for retrieval-augmented generation
Jan 27, 2025



Retrieval-augmented generation improves various aspects of large language models (LLMs) generation, but suffers from computational overhead caused by long contexts as well as the propagation of irrelevant retrieved information into generated responses. Context pruning deals with both aspects, by removing irrelevant parts of retrieved contexts before LLM generation. Existing context pruning approaches are however limited, and do not provide a universal model that would be both efficient and robust in a wide range of scenarios, e.g., when contexts contain a variable amount of relevant information or vary in length, or when evaluated on various domains. In this work, we close this gap and introduce Provence (Pruning and Reranking Of retrieVEd relevaNt ContExts), an efficient and robust context pruner for Question Answering, which dynamically detects the needed amount of pruning for a given context and can be used out-of-the-box for various domains. The three key ingredients of Provence are formulating the context pruning task as sequence labeling, unifying context pruning capabilities with context reranking, and training on diverse data. Our experimental results show that Provence enables context pruning with negligible to no drop in performance, in various domains and settings, at almost no cost in a standard RAG pipeline. We also conduct a deeper analysis alongside various ablations to provide insights into training context pruners for future work.
BERGEN: A Benchmarking Library for Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-Augmented Generation allows to enhance Large Language Models with external knowledge. In response to the recent popularity of generative LLMs, many RAG approaches have been proposed, which involve an intricate number of different configurations such as evaluation datasets, collections, metrics, retrievers, and LLMs. Inconsistent benchmarking poses a major challenge in comparing approaches and understanding the impact of each component in the pipeline. In this work, we study best practices that lay the groundwork for a systematic evaluation of RAG and present BERGEN, an end-to-end library for reproducible research standardizing RAG experiments. In an extensive study focusing on QA, we benchmark different state-of-the-art retrievers, rerankers, and LLMs. Additionally, we analyze existing RAG metrics and datasets. Our open-source library BERGEN is available under \url{https://github.com/naver/bergen}.
Retrieval-augmented generation in multilingual settings
Jul 01, 2024



Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
SPLATE: Sparse Late Interaction Retrieval
Apr 22, 2024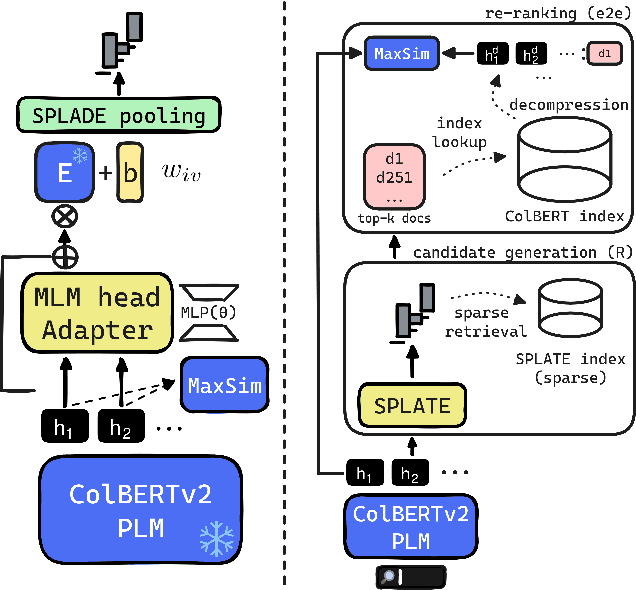
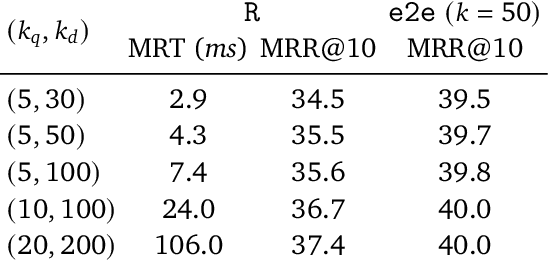
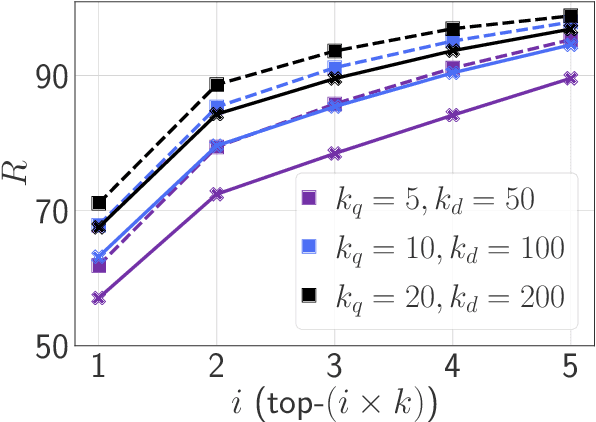
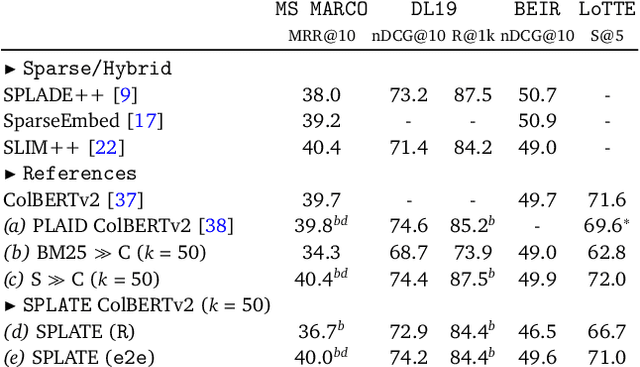
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
A Thorough Comparison of Cross-Encoders and LLMs for Reranking SPLADE
Mar 15, 2024We present a comparative study between cross-encoder and LLMs rerankers in the context of re-ranking effective SPLADE retrievers. We conduct a large evaluation on TREC Deep Learning datasets and out-of-domain datasets such as BEIR and LoTTE. In the first set of experiments, we show how cross-encoder rerankers are hard to distinguish when it comes to re-rerank SPLADE on MS MARCO. Observations shift in the out-of-domain scenario, where both the type of model and the number of documents to re-rank have an impact on effectiveness. Then, we focus on listwise rerankers based on Large Language Models -- especially GPT-4. While GPT-4 demonstrates impressive (zero-shot) performance, we show that traditional cross-encoders remain very competitive. Overall, our findings aim to to provide a more nuanced perspective on the recent excitement surrounding LLM-based re-rankers -- by positioning them as another factor to consider in balancing effectiveness and efficiency in search systems.
SPLADE-v3: New baselines for SPLADE
Mar 11, 2024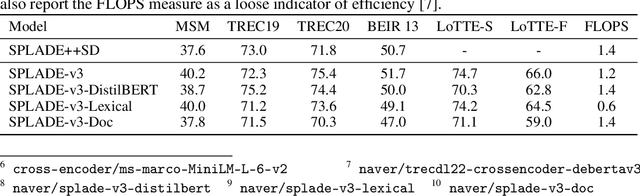
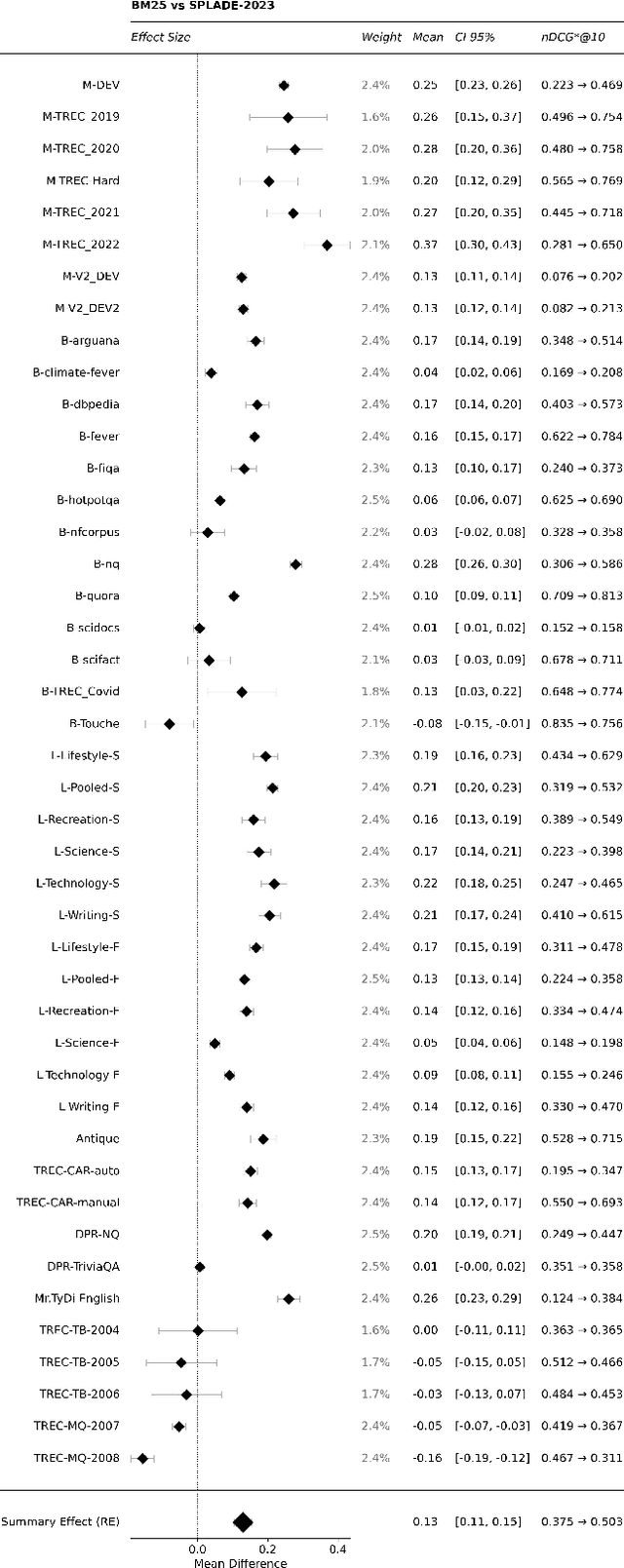
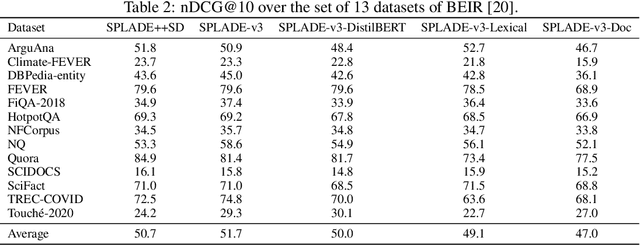
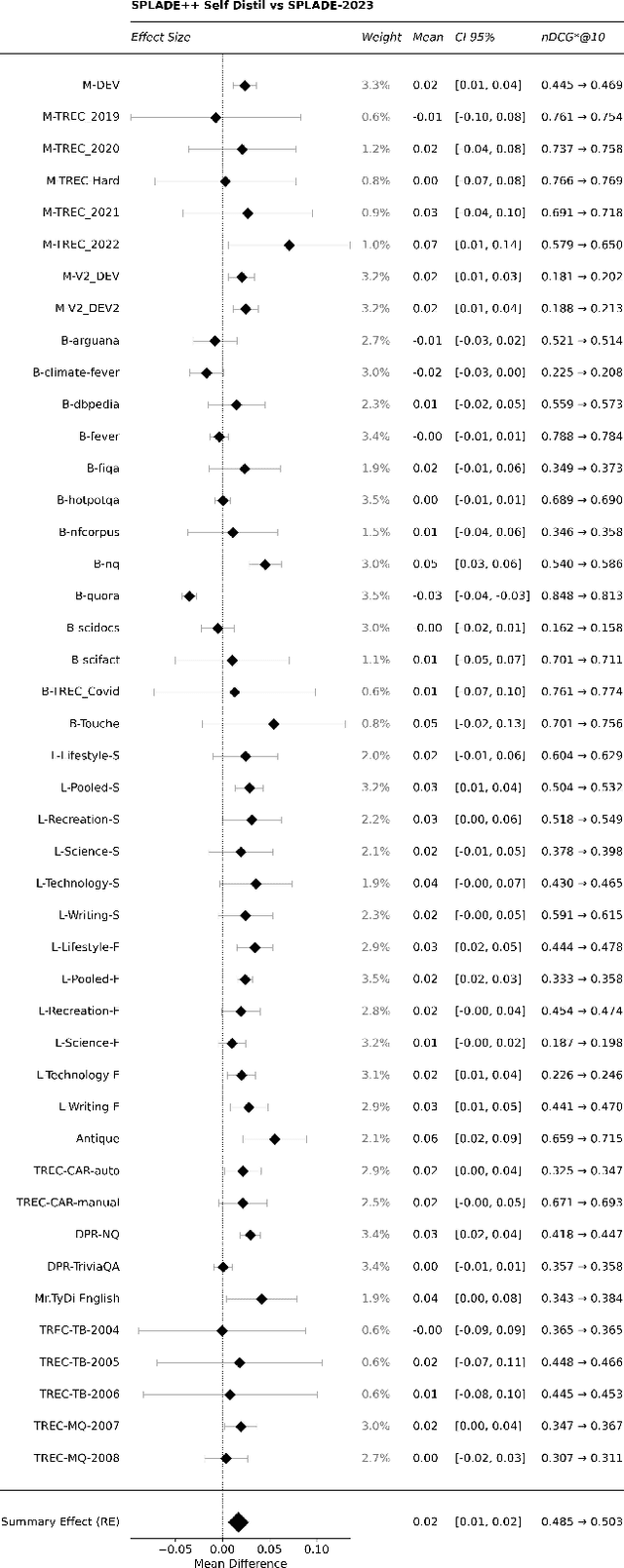
A companion to the release of the latest version of the SPLADE library. We describe changes to the training structure and present our latest series of models -- SPLADE-v3. We compare this new version to BM25, SPLADE++, as well as re-rankers, and showcase its effectiveness via a meta-analysis over more than 40 query sets. SPLADE-v3 further pushes the limit of SPLADE models: it is statistically significantly more effective than both BM25 and SPLADE++, while comparing well to cross-encoder re-rankers. Specifically, it gets more than 40 MRR@10 on the MS MARCO dev set, and improves by 2% the out-of-domain results on the BEIR benchmark.
Benchmarking Middle-Trained Language Models for Neural Search
Jun 05, 2023Middle training methods aim to bridge the gap between the Masked Language Model (MLM) pre-training and the final finetuning for retrieval. Recent models such as CoCondenser, RetroMAE, and LexMAE argue that the MLM task is not sufficient enough to pre-train a transformer network for retrieval and hence propose various tasks to do so. Intrigued by those novel methods, we noticed that all these models used different finetuning protocols, making it hard to assess the benefits of middle training. We propose in this paper a benchmark of CoCondenser, RetroMAE, and LexMAE, under the same finetuning conditions. We compare both dense and sparse approaches under various finetuning protocols and middle training on different collections (MS MARCO, Wikipedia or Tripclick). We use additional middle training baselines, such as a standard MLM finetuning on the retrieval collection, optionally augmented by a CLS predicting the passage term frequency. For the sparse approach, our study reveals that there is almost no statistical difference between those methods: the more effective the finetuning procedure is, the less difference there is between those models. For the dense approach, RetroMAE using MS MARCO as middle-training collection shows excellent results in almost all the settings. Finally, we show that middle training on the retrieval collection, thus adapting the language model to it, is a critical factor. Overall, a better experimental setup should be adopted to evaluate middle training methods. Code available at https://github.com/naver/splade/tree/benchmarch-SIGIR23
Query Performance Prediction for Neural IR: Are We There Yet?
Feb 20, 2023Evaluation in Information Retrieval relies on post-hoc empirical procedures, which are time-consuming and expensive operations. To alleviate this, Query Performance Prediction (QPP) models have been developed to estimate the performance of a system without the need for human-made relevance judgements. Such models, usually relying on lexical features from queries and corpora, have been applied to traditional sparse IR methods - with various degrees of success. With the advent of neural IR and large Pre-trained Language Models, the retrieval paradigm has significantly shifted towards more semantic signals. In this work, we study and analyze to what extent current QPP models can predict the performance of such systems. Our experiments consider seven traditional bag-of-words and seven BERT-based IR approaches, as well as nineteen state-of-the-art QPPs evaluated on two collections, Deep Learning '19 and Robust '04. Our findings show that QPPs perform statistically significantly worse on neural IR systems. In settings where semantic signals are prominent (e.g., passage retrieval), their performance on neural models drops by as much as 10% compared to bag-of-words approaches. On top of that, in lexical-oriented scenarios, QPPs fail to predict performance for neural IR systems on those queries where they differ from traditional approaches the most.
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Jan 11, 2023


Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.