 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Language Models are Good Too: An Empirical Study of Zero-Shot Classification
Apr 17, 2024
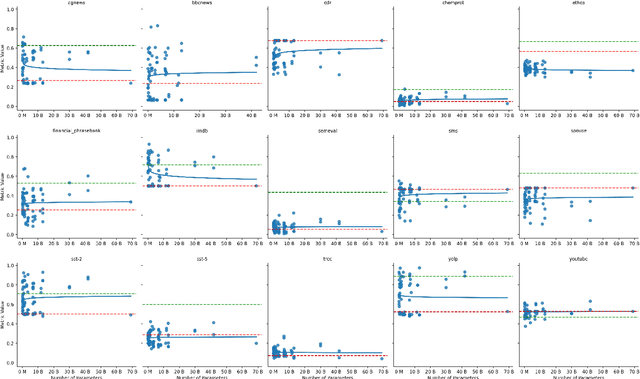
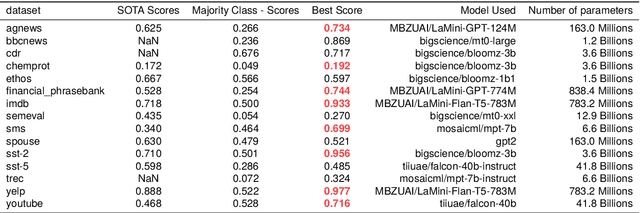
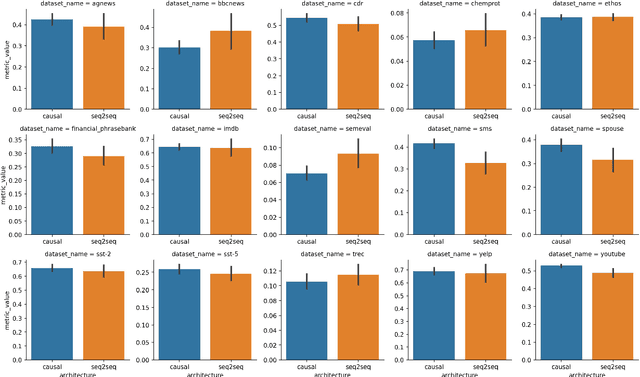
This study is part of the debate on the efficiency of large versus small language models for text classification by prompting.We assess the performance of small language models in zero-shot text classification, challenging the prevailing dominance of large models.Across 15 datasets, our investigation benchmarks language models from 77M to 40B parameters using different architectures and scoring functions. Our findings reveal that small models can effectively classify texts, getting on par with or surpassing their larger counterparts.We developed and shared a comprehensive open-source repository that encapsulates our methodologies. This research underscores the notion that bigger isn't always better, suggesting that resource-efficient small models may offer viable solutions for specific data classification challenges.
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Jan 11, 2023


Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.
Continual Learning of Long Topic Sequences in Neural Information Retrieval
Jan 10, 2022
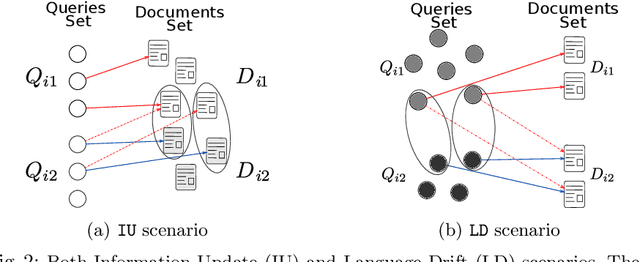
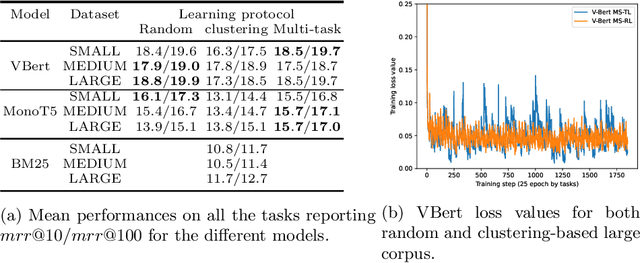
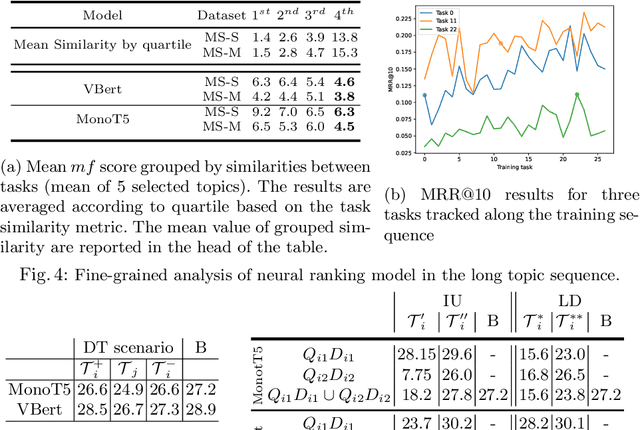
In information retrieval (IR) systems, trends and users' interests may change over time, altering either the distribution of requests or contents to be recommended. Since neural ranking approaches heavily depend on the training data, it is crucial to understand the transfer capacity of recent IR approaches to address new domains in the long term. In this paper, we first propose a dataset based upon the MSMarco corpus aiming at modeling a long stream of topics as well as IR property-driven controlled settings. We then in-depth analyze the ability of recent neural IR models while continually learning those streams. Our empirical study highlights in which particular cases catastrophic forgetting occurs (e.g., level of similarity between tasks, peculiarities on text length, and ways of learning models) to provide future directions in terms of model design.
Does Structure Matter? Leveraging Data-to-Text Generation for Answering Complex Information Needs
Dec 08, 2021

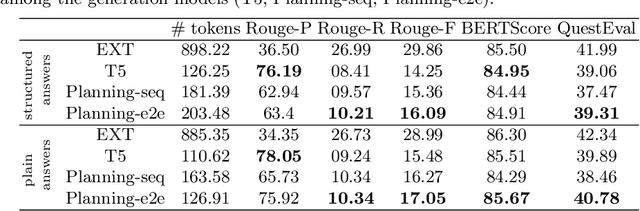

In this work, our aim is to provide a structured answer in natural language to a complex information need. Particularly, we envision using generative models from the perspective of data-to-text generation. We propose the use of a content selection and planning pipeline which aims at structuring the answer by generating intermediate plans. The experimental evaluation is performed using the TREC Complex Answer Retrieval (CAR) dataset. We evaluate both the generated answer and its corresponding structure and show the effectiveness of planning-based models in comparison to a text-to-text model.
Geomstats: A Python Package for Riemannian Geometry in Machine Learning
Apr 07, 2020
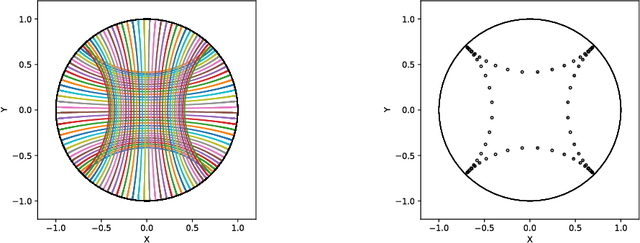
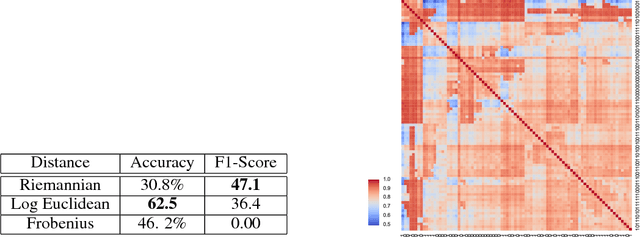

We introduce Geomstats, an open-source Python toolbox for computations and statistics on nonlinear manifolds, such as hyperbolic spaces, spaces of symmetric positive definite matrices, Lie groups of transformations, and many more. We provide object-oriented and extensively unit-tested implementations. Among others, manifolds come equipped with families of Riemannian metrics, with associated exponential and logarithmic maps, geodesics and parallel transport. Statistics and learning algorithms provide methods for estimation, clustering and dimension reduction on manifolds. All associated operations are vectorized for batch computation and provide support for different execution backends, namely NumPy, PyTorch and TensorFlow, enabling GPU acceleration. This paper presents the package, compares it with related libraries and provides relevant code examples. We show that Geomstats provides reliable building blocks to foster research in differential geometry and statistics, and to democratize the use of Riemannian geometry in machine learning applications. The source code is freely available under the MIT license at \url{geomstats.ai}.
Binary Stochastic Representations for Large Multi-class Classification
Jun 24, 2019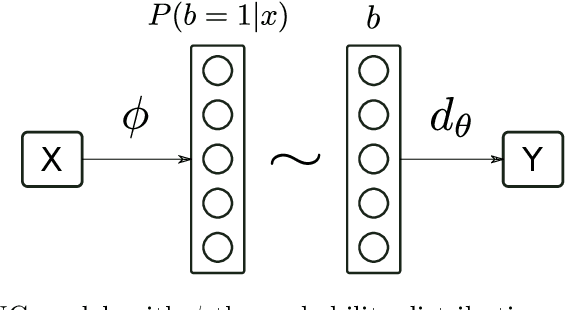
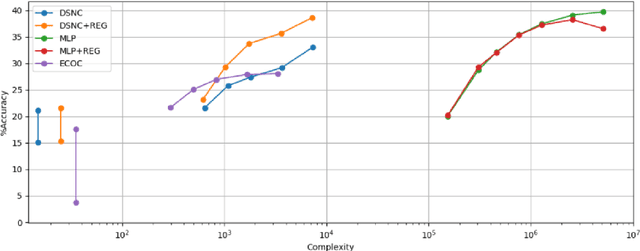
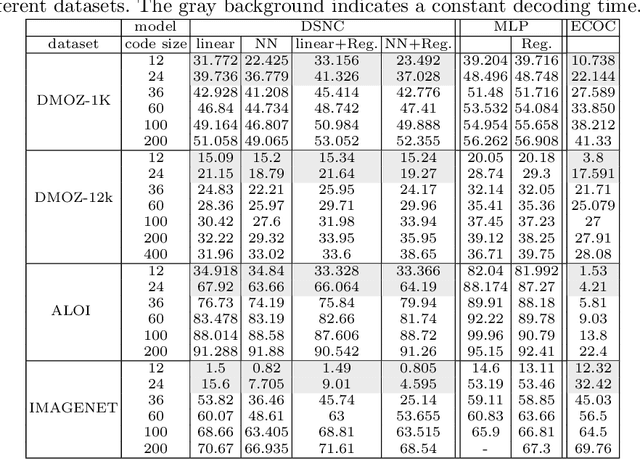
Classification with a large number of classes is a key problem in machine learning and corresponds to many real-world applications like tagging of images or textual documents in social networks. If one-vs-all methods usually reach top performance in this context, these approaches suffer from a high inference complexity, linear w.r.t the number of categories. Different models based on the notion of binary codes have been proposed to overcome this limitation, achieving in a sublinear inference complexity. But they a priori need to decide which binary code to associate to which category before learning using more or less complex heuristics. We propose a new end-to-end model which aims at simultaneously learning to associate binary codes with categories, but also learning to map inputs to binary codes. This approach called Deep Stochastic Neural Codes (DSNC) keeps the sublinear inference complexity but do not need any a priori tuning. Experimental results on different datasets show the effectiveness of the approach w.r.t baseline methods.