 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Atomic Propositions help weak extractors: Evaluation of a Propositioner for triplet extraction
Apr 03, 2026Knowledge Graph construction from natural language requires extracting structured triplets from complex, information-dense sentences. In this paper, we investigate if the decomposition of text into atomic propositions (minimal, semantically autonomous units of information) can improve the triplet extraction. We introduce MPropositionneur-V2, a small multilingual model covering six European languages trained by knowledge distillation from Qwen3-32B into a Qwen3-0.6B architecture, and we evaluate its integration into two extraction paradigms: entity-centric (GLiREL) and generative (Qwen3). Experiments on SMiLER, FewRel, DocRED and CaRB show that atomic propositions benefit weaker extractors (GLiREL, CoreNLP, 0.6B models), improving relation recall and, in the multilingual setting, overall accuracy. For stronger LLMs, a fallback combination strategy recovers entity recall losses while preserving the gains in relation extraction. These results show that atomic propositions are an interpretable intermediate data structure that complements extractors without replacing them.
Small Language Models are Good Too: An Empirical Study of Zero-Shot Classification
Apr 17, 2024
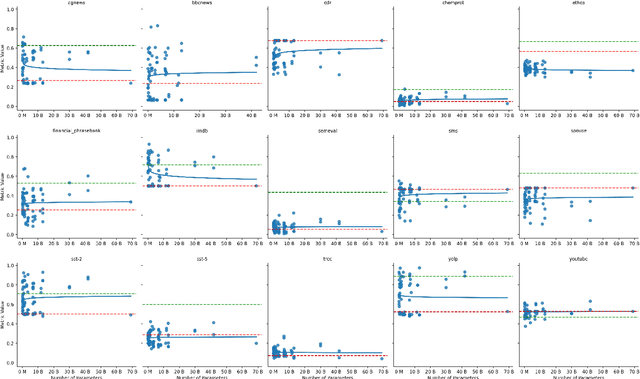
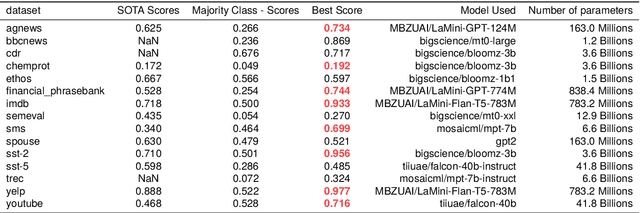
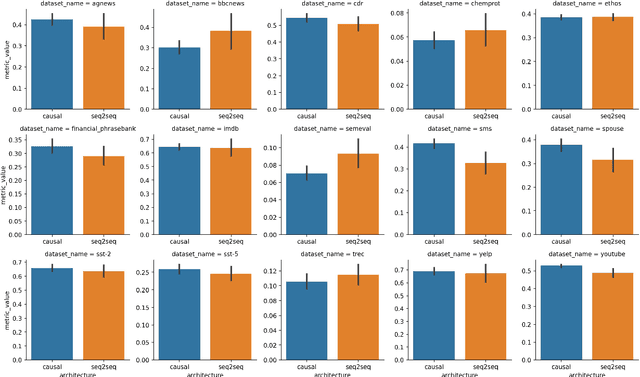
This study is part of the debate on the efficiency of large versus small language models for text classification by prompting.We assess the performance of small language models in zero-shot text classification, challenging the prevailing dominance of large models.Across 15 datasets, our investigation benchmarks language models from 77M to 40B parameters using different architectures and scoring functions. Our findings reveal that small models can effectively classify texts, getting on par with or surpassing their larger counterparts.We developed and shared a comprehensive open-source repository that encapsulates our methodologies. This research underscores the notion that bigger isn't always better, suggesting that resource-efficient small models may offer viable solutions for specific data classification challenges.
New Semantic Task for the French Spoken Language Understanding MEDIA Benchmark
Mar 28, 2024Intent classification and slot-filling are essential tasks of Spoken Language Understanding (SLU). In most SLUsystems, those tasks are realized by independent modules. For about fifteen years, models achieving both of themjointly and exploiting their mutual enhancement have been proposed. A multilingual module using a joint modelwas envisioned to create a touristic dialogue system for a European project, HumanE-AI-Net. A combination ofmultiple datasets, including the MEDIA dataset, was suggested for training this joint model. The MEDIA SLU datasetis a French dataset distributed since 2005 by ELRA, mainly used by the French research community and free foracademic research since 2020. Unfortunately, it is annotated only in slots but not intents. An enhanced version ofMEDIA annotated with intents has been built to extend its use to more tasks and use cases. This paper presents thesemi-automatic methodology used to obtain this enhanced version. In addition, we present the first results of SLUexperiments on this enhanced dataset using joint models for intent classification and slot-filling.
mALBERT: Is a Compact Multilingual BERT Model Still Worth It?
Mar 27, 2024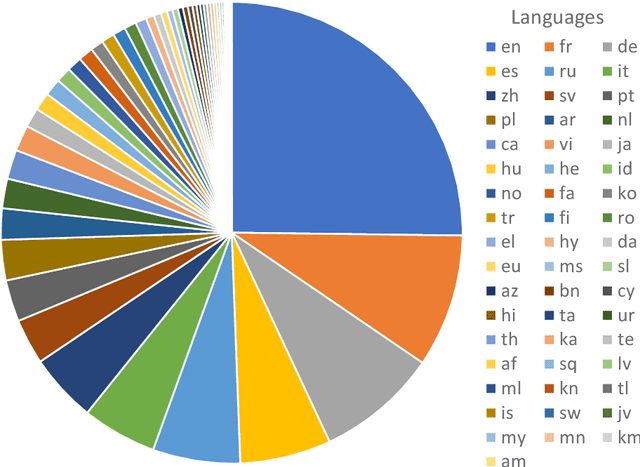
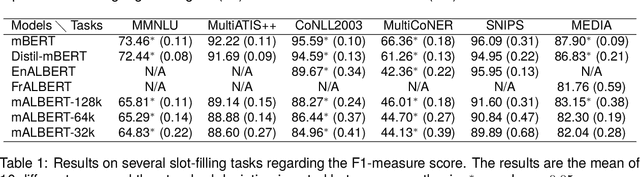
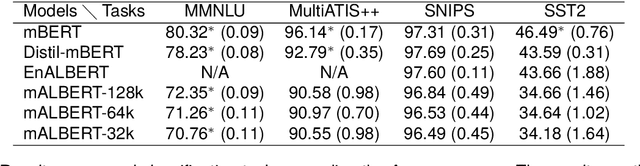

Within the current trend of Pretained Language Models (PLM), emerge more and more criticisms about the ethical andecological impact of such models. In this article, considering these critical remarks, we propose to focus on smallermodels, such as compact models like ALBERT, which are more ecologically virtuous than these PLM. However,PLMs enable huge breakthroughs in Natural Language Processing tasks, such as Spoken and Natural LanguageUnderstanding, classification, Question--Answering tasks. PLMs also have the advantage of being multilingual, and,as far as we know, a multilingual version of compact ALBERT models does not exist. Considering these facts, wepropose the free release of the first version of a multilingual compact ALBERT model, pre-trained using Wikipediadata, which complies with the ethical aspect of such a language model. We also evaluate the model against classicalmultilingual PLMs in classical NLP tasks. Finally, this paper proposes a rare study on the subword tokenizationimpact on language performances.
On the cross-lingual transferability of multilingual prototypical models across NLU tasks
Jul 19, 2022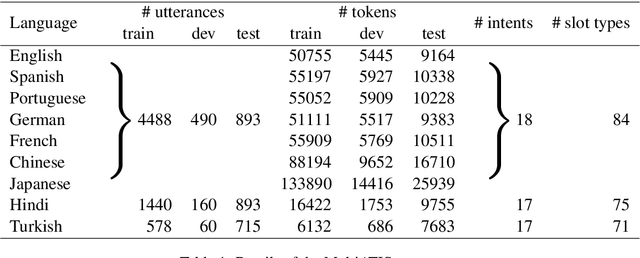
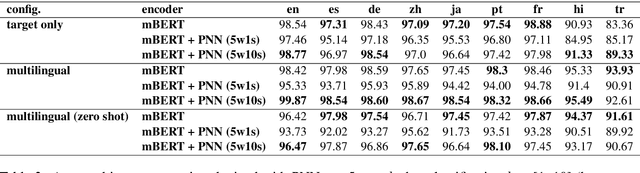

Supervised deep learning-based approaches have been applied to task-oriented dialog and have proven to be effective for limited domain and language applications when a sufficient number of training examples are available. In practice, these approaches suffer from the drawbacks of domain-driven design and under-resourced languages. Domain and language models are supposed to grow and change as the problem space evolves. On one hand, research on transfer learning has demonstrated the cross-lingual ability of multilingual Transformers-based models to learn semantically rich representations. On the other, in addition to the above approaches, meta-learning have enabled the development of task and language learning algorithms capable of far generalization. Through this context, this article proposes to investigate the cross-lingual transferability of using synergistically few-shot learning with prototypical neural networks and multilingual Transformers-based models. Experiments in natural language understanding tasks on MultiATIS++ corpus shows that our approach substantially improves the observed transfer learning performances between the low and the high resource languages. More generally our approach confirms that the meaningful latent space learned in a given language can be can be generalized to unseen and under-resourced ones using meta-learning.
Benchmarking Transformers-based models on French Spoken Language Understanding tasks
Jul 19, 2022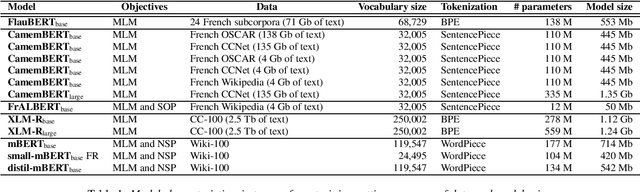
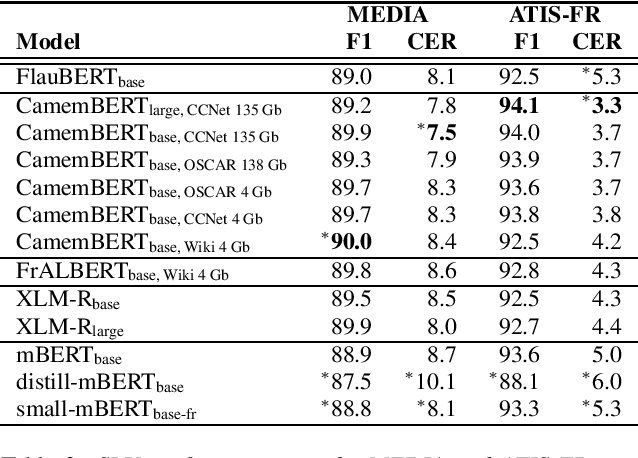
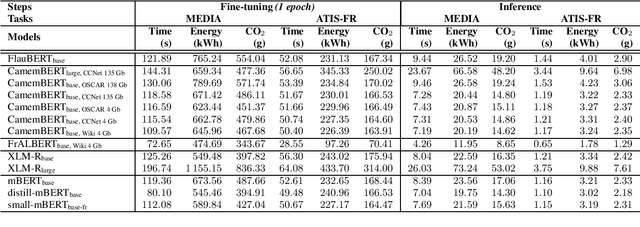
In the last five years, the rise of the self-attentional Transformer-based architectures led to state-of-the-art performances over many natural language tasks. Although these approaches are increasingly popular, they require large amounts of data and computational resources. There is still a substantial need for benchmarking methodologies ever upwards on under-resourced languages in data-scarce application conditions. Most pre-trained language models were massively studied using the English language and only a few of them were evaluated on French. In this paper, we propose a unified benchmark, focused on evaluating models quality and their ecological impact on two well-known French spoken language understanding tasks. Especially we benchmark thirteen well-established Transformer-based models on the two available spoken language understanding tasks for French: MEDIA and ATIS-FR. Within this framework, we show that compact models can reach comparable results to bigger ones while their ecological impact is considerably lower. However, this assumption is nuanced and depends on the considered compression method.
On the Usability of Transformers-based models for a French Question-Answering task
Jul 19, 2022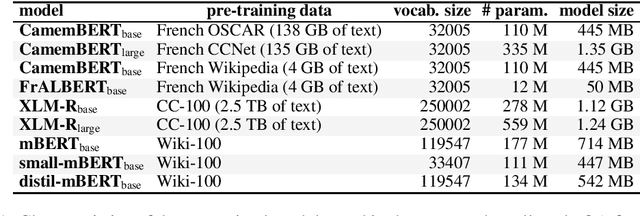
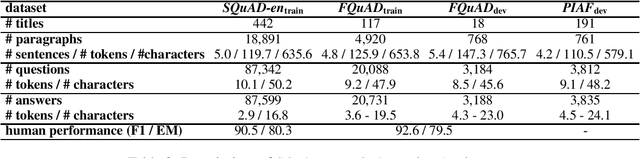
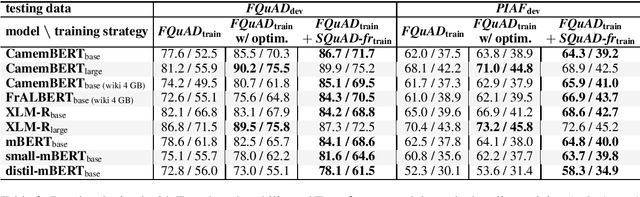
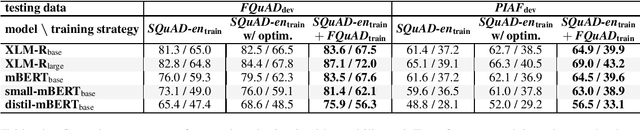
For many tasks, state-of-the-art results have been achieved with Transformer-based architectures, resulting in a paradigmatic shift in practices from the use of task-specific architectures to the fine-tuning of pre-trained language models. The ongoing trend consists in training models with an ever-increasing amount of data and parameters, which requires considerable resources. It leads to a strong search to improve resource efficiency based on algorithmic and hardware improvements evaluated only for English. This raises questions about their usability when applied to small-scale learning problems, for which a limited amount of training data is available, especially for under-resourced languages tasks. The lack of appropriately sized corpora is a hindrance to applying data-driven and transfer learning-based approaches with strong instability cases. In this paper, we establish a state-of-the-art of the efforts dedicated to the usability of Transformer-based models and propose to evaluate these improvements on the question-answering performances of French language which have few resources. We address the instability relating to data scarcity by investigating various training strategies with data augmentation, hyperparameters optimization and cross-lingual transfer. We also introduce a new compact model for French FrALBERT which proves to be competitive in low-resource settings.
Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation
Sep 14, 2021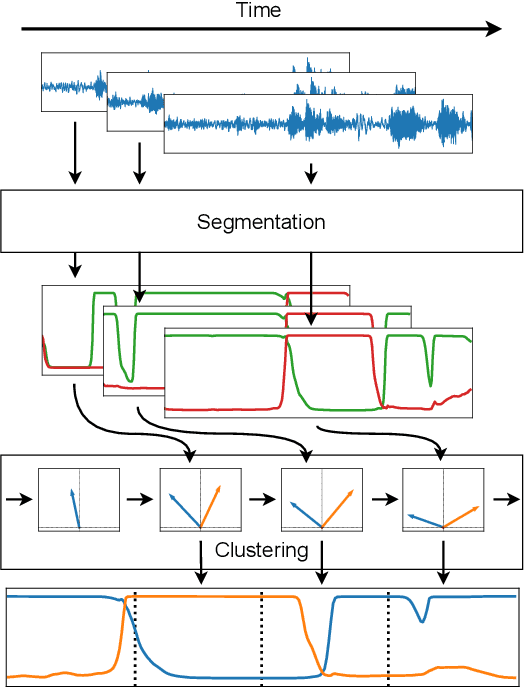

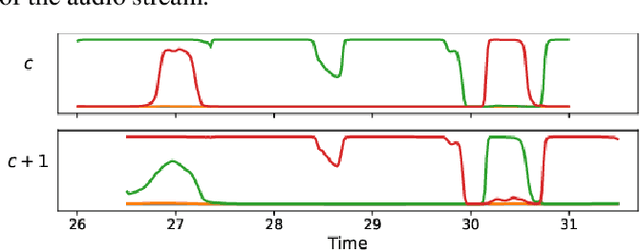
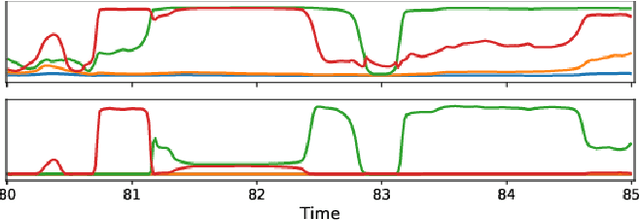
We propose to address online speaker diarization as a combination of incremental clustering and local diarization applied to a rolling buffer updated every 500ms. Every single step of the proposed pipeline is designed to take full advantage of the strong ability of a recently proposed end-to-end overlap-aware segmentation to detect and separate overlapping speakers. In particular, we propose a modified version of the statistics pooling layer (initially introduced in the x-vector architecture) to give less weight to frames where the segmentation model predicts simultaneous speakers. Furthermore, we derive cannot-link constraints from the initial segmentation step to prevent two local speakers from being wrongfully merged during the incremental clustering step. Finally, we show how the latency of the proposed approach can be adjusted between 500ms and 5s to match the requirements of a particular use case, and we provide a systematic analysis of the influence of latency on the overall performance (on AMI, DIHARD and VoxConverse).
Evaluate On-the-job Learning Dialogue Systems and a Case Study for Natural Language Understanding
Feb 26, 2021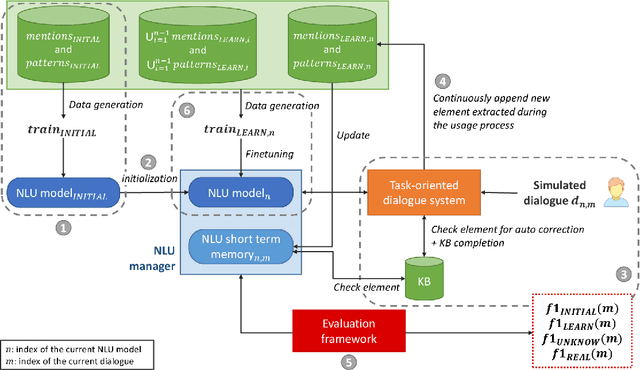

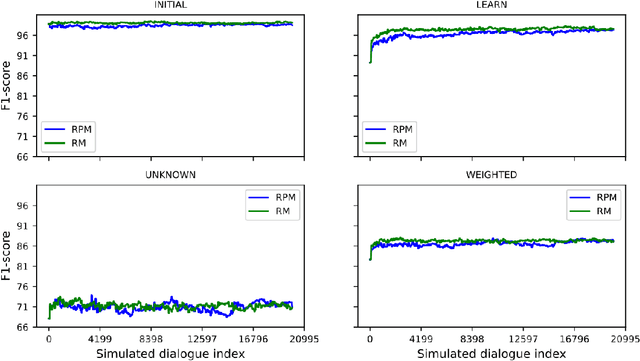
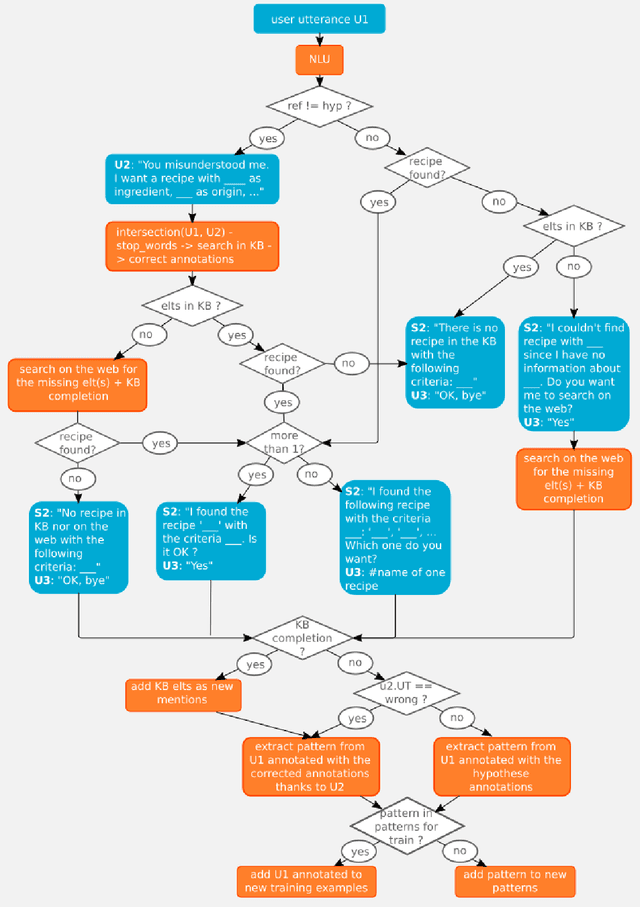
On-the-job learning consists in continuously learning while being used in production, in an open environment, meaning that the system has to deal on its own with situations and elements never seen before. The kind of systems that seem to be especially adapted to on-the-job learning are dialogue systems, since they can take advantage of their interactions with users to collect feedback to adapt and improve their components over time. Some dialogue systems performing on-the-job learning have been built and evaluated but no general methodology has yet been defined. Thus in this paper, we propose a first general methodology for evaluating on-the-job learning dialogue systems. We also describe a task-oriented dialogue system which improves on-the-job its natural language component through its user interactions. We finally evaluate our system with the described methodology.
LIMSI_UPV at SemEval-2020 Task 9: Recurrent Convolutional Neural Network for Code-mixed Sentiment Analysis
Aug 30, 2020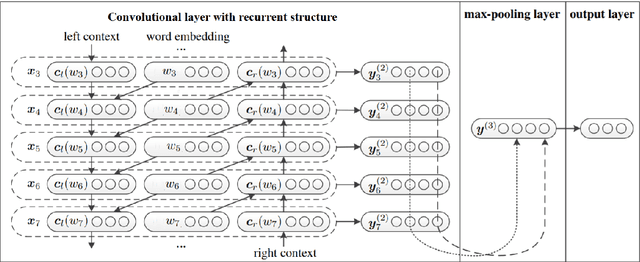
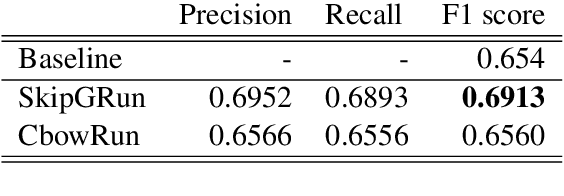

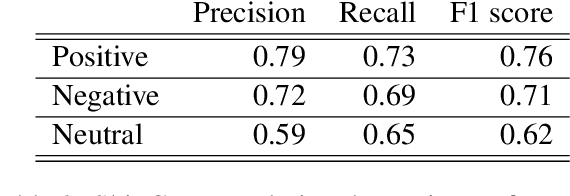
This paper describes the participation of LIMSI UPV team in SemEval-2020 Task 9: Sentiment Analysis for Code-Mixed Social Media Text. The proposed approach competed in SentiMix Hindi-English subtask, that addresses the problem of predicting the sentiment of a given Hindi-English code-mixed tweet. We propose Recurrent Convolutional Neural Network that combines both the recurrent neural network and the convolutional network to better capture the semantics of the text, for code-mixed sentiment analysis. The proposed system obtained 0.69 (best run) in terms of F1 score on the given test data and achieved the 9th place (Codalab username: somban) in the SentiMix Hindi-English subtask.