 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverlap-aware low-latency online speaker diarization based on end-to-end local segmentation
Sep 14, 2021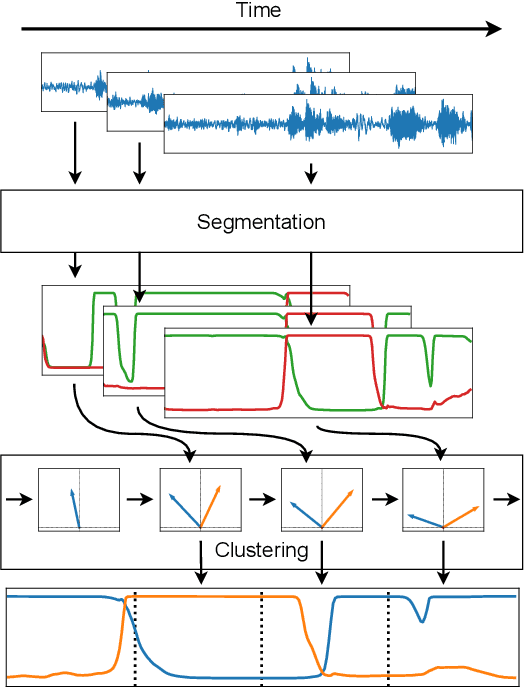

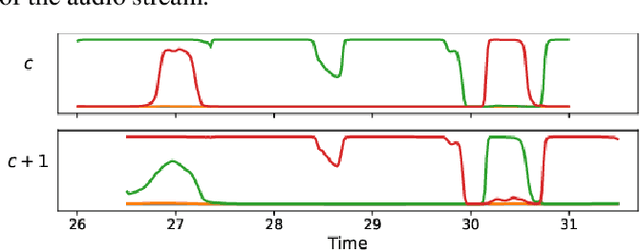
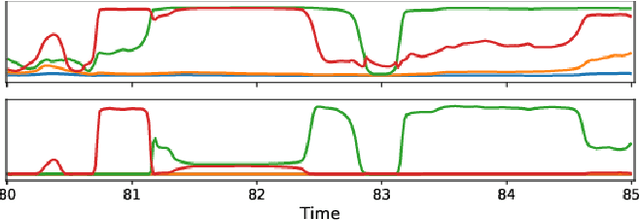
We propose to address online speaker diarization as a combination of incremental clustering and local diarization applied to a rolling buffer updated every 500ms. Every single step of the proposed pipeline is designed to take full advantage of the strong ability of a recently proposed end-to-end overlap-aware segmentation to detect and separate overlapping speakers. In particular, we propose a modified version of the statistics pooling layer (initially introduced in the x-vector architecture) to give less weight to frames where the segmentation model predicts simultaneous speakers. Furthermore, we derive cannot-link constraints from the initial segmentation step to prevent two local speakers from being wrongfully merged during the incremental clustering step. Finally, we show how the latency of the proposed approach can be adjusted between 500ms and 5s to match the requirements of a particular use case, and we provide a systematic analysis of the influence of latency on the overall performance (on AMI, DIHARD and VoxConverse).
A Comparison of Metric Learning Loss Functions for End-To-End Speaker Verification
Mar 31, 2020


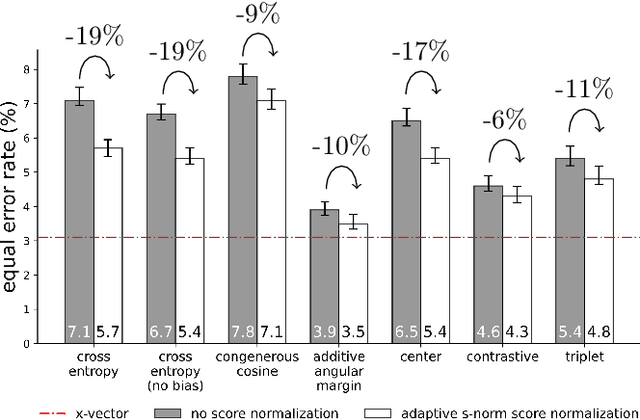
Despite the growing popularity of metric learning approaches, very little work has attempted to perform a fair comparison of these techniques for speaker verification. We try to fill this gap and compare several metric learning loss functions in a systematic manner on the VoxCeleb dataset. The first family of loss functions is derived from the cross entropy loss (usually used for supervised classification) and includes the congenerous cosine loss, the additive angular margin loss, and the center loss. The second family of loss functions focuses on the similarity between training samples and includes the contrastive loss and the triplet loss. We show that the additive angular margin loss function outperforms all other loss functions in the study, while learning more robust representations. Based on a combination of SincNet trainable features and the x-vector architecture, the network used in this paper brings us a step closer to a really-end-to-end speaker verification system, when combined with the additive angular margin loss, while still being competitive with the x-vector baseline. In the spirit of reproducible research, we also release open source Python code for reproducing our results, and share pretrained PyTorch models on torch.hub that can be used either directly or after fine-tuning.