 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the cross-lingual transferability of multilingual prototypical models across NLU tasks
Jul 19, 2022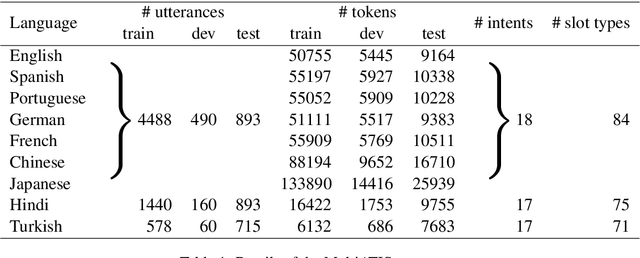

Supervised deep learning-based approaches have been applied to task-oriented dialog and have proven to be effective for limited domain and language applications when a sufficient number of training examples are available. In practice, these approaches suffer from the drawbacks of domain-driven design and under-resourced languages. Domain and language models are supposed to grow and change as the problem space evolves. On one hand, research on transfer learning has demonstrated the cross-lingual ability of multilingual Transformers-based models to learn semantically rich representations. On the other, in addition to the above approaches, meta-learning have enabled the development of task and language learning algorithms capable of far generalization. Through this context, this article proposes to investigate the cross-lingual transferability of using synergistically few-shot learning with prototypical neural networks and multilingual Transformers-based models. Experiments in natural language understanding tasks on MultiATIS++ corpus shows that our approach substantially improves the observed transfer learning performances between the low and the high resource languages. More generally our approach confirms that the meaningful latent space learned in a given language can be can be generalized to unseen and under-resourced ones using meta-learning.
Benchmarking Transformers-based models on French Spoken Language Understanding tasks
Jul 19, 2022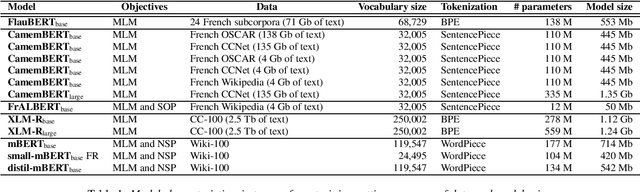
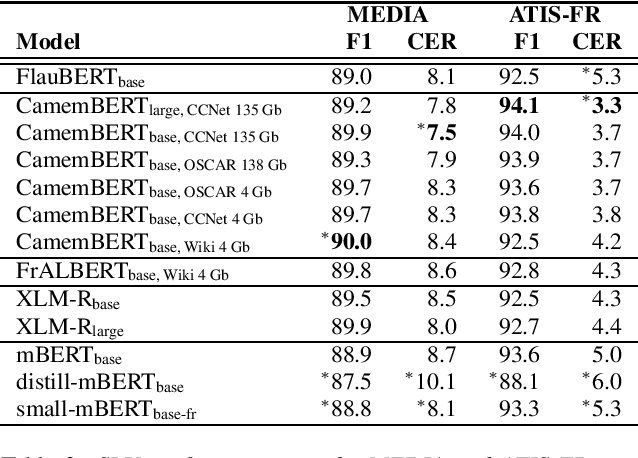
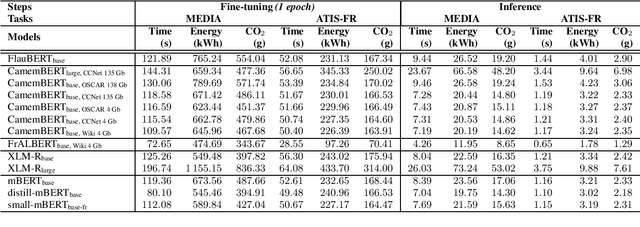
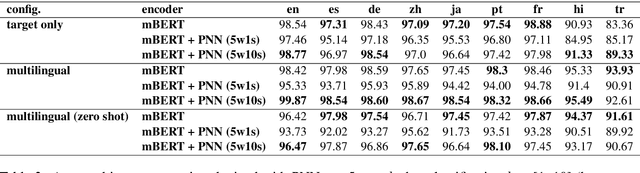
In the last five years, the rise of the self-attentional Transformer-based architectures led to state-of-the-art performances over many natural language tasks. Although these approaches are increasingly popular, they require large amounts of data and computational resources. There is still a substantial need for benchmarking methodologies ever upwards on under-resourced languages in data-scarce application conditions. Most pre-trained language models were massively studied using the English language and only a few of them were evaluated on French. In this paper, we propose a unified benchmark, focused on evaluating models quality and their ecological impact on two well-known French spoken language understanding tasks. Especially we benchmark thirteen well-established Transformer-based models on the two available spoken language understanding tasks for French: MEDIA and ATIS-FR. Within this framework, we show that compact models can reach comparable results to bigger ones while their ecological impact is considerably lower. However, this assumption is nuanced and depends on the considered compression method.
On the Usability of Transformers-based models for a French Question-Answering task
Jul 19, 2022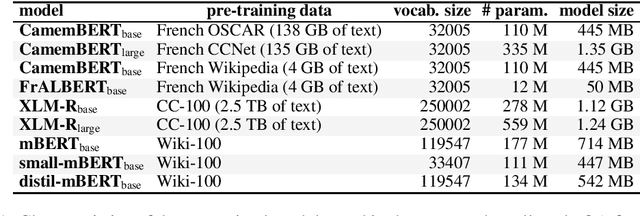
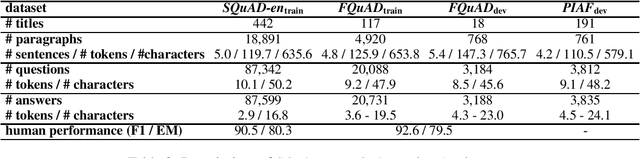
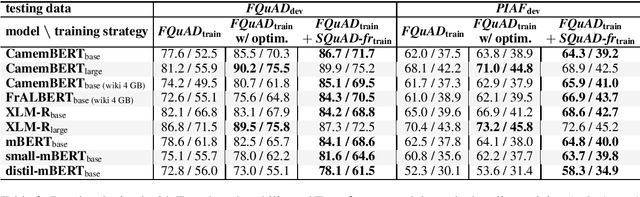
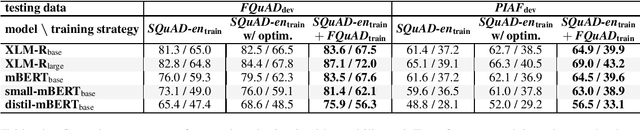
For many tasks, state-of-the-art results have been achieved with Transformer-based architectures, resulting in a paradigmatic shift in practices from the use of task-specific architectures to the fine-tuning of pre-trained language models. The ongoing trend consists in training models with an ever-increasing amount of data and parameters, which requires considerable resources. It leads to a strong search to improve resource efficiency based on algorithmic and hardware improvements evaluated only for English. This raises questions about their usability when applied to small-scale learning problems, for which a limited amount of training data is available, especially for under-resourced languages tasks. The lack of appropriately sized corpora is a hindrance to applying data-driven and transfer learning-based approaches with strong instability cases. In this paper, we establish a state-of-the-art of the efforts dedicated to the usability of Transformer-based models and propose to evaluate these improvements on the question-answering performances of French language which have few resources. We address the instability relating to data scarcity by investigating various training strategies with data augmentation, hyperparameters optimization and cross-lingual transfer. We also introduce a new compact model for French FrALBERT which proves to be competitive in low-resource settings.
Qwant Research @DEFT 2019: Document matching and information retrieval using clinical cases
Jul 06, 2019
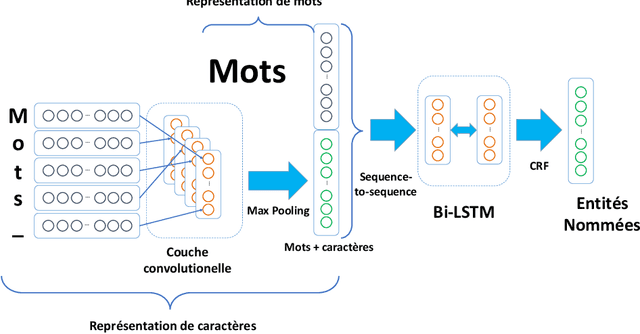


This paper reports on Qwant Research contribution to tasks 2 and 3 of the DEFT 2019's challenge, focusing on French clinical cases analysis. Task 2 is a task on semantic similarity between clinical cases and discussions. For this task, we propose an approach based on language models and evaluate the impact on the results of different preprocessings and matching techniques. For task 3, we have developed an information extraction system yielding very encouraging results accuracy-wise. We have experimented two different approaches, one based on the exclusive use of neural networks, the other based on a linguistic analysis.
* Article accepted at the workshop DEfi fouille de Texte (DEFT 2019). Article in French