 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Language Models are Good Too: An Empirical Study of Zero-Shot Classification
Apr 17, 2024
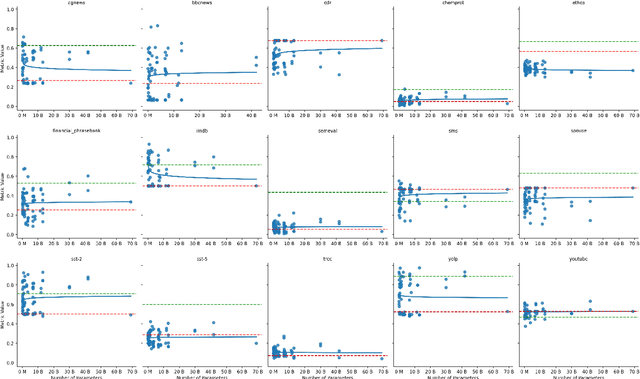
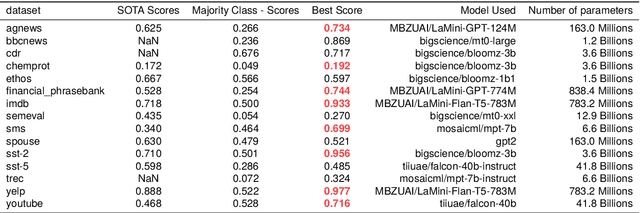
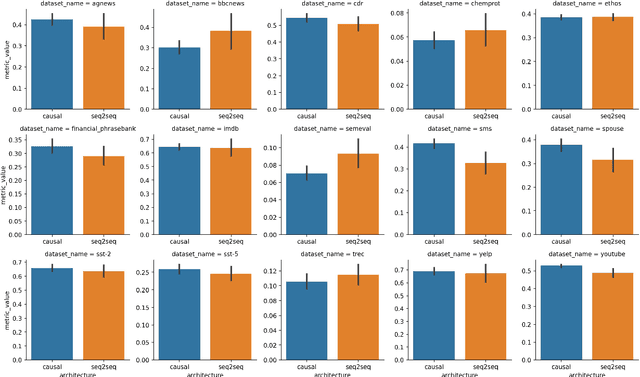
This study is part of the debate on the efficiency of large versus small language models for text classification by prompting.We assess the performance of small language models in zero-shot text classification, challenging the prevailing dominance of large models.Across 15 datasets, our investigation benchmarks language models from 77M to 40B parameters using different architectures and scoring functions. Our findings reveal that small models can effectively classify texts, getting on par with or surpassing their larger counterparts.We developed and shared a comprehensive open-source repository that encapsulates our methodologies. This research underscores the notion that bigger isn't always better, suggesting that resource-efficient small models may offer viable solutions for specific data classification challenges.