 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation Framework for Attributed Information Retrieval using Large Language Models
Sep 12, 2024With the growing success of Large Language models (LLMs) in information-seeking scenarios, search engines are now adopting generative approaches to provide answers along with in-line citations as attribution. While existing work focuses mainly on attributed question answering, in this paper, we target information-seeking scenarios which are often more challenging due to the open-ended nature of the queries and the size of the label space in terms of the diversity of candidate-attributed answers per query. We propose a reproducible framework to evaluate and benchmark attributed information seeking, using any backbone LLM, and different architectural designs: (1) Generate (2) Retrieve then Generate, and (3) Generate then Retrieve. Experiments using HAGRID, an attributed information-seeking dataset, show the impact of different scenarios on both the correctness and attributability of answers.
Does Structure Matter? Leveraging Data-to-Text Generation for Answering Complex Information Needs
Dec 08, 2021

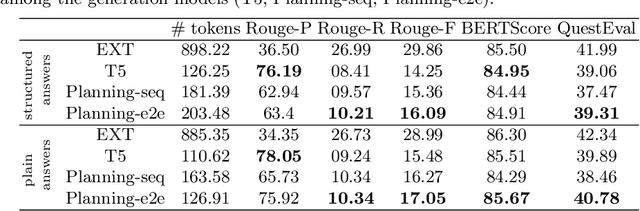

In this work, our aim is to provide a structured answer in natural language to a complex information need. Particularly, we envision using generative models from the perspective of data-to-text generation. We propose the use of a content selection and planning pipeline which aims at structuring the answer by generating intermediate plans. The experimental evaluation is performed using the TREC Complex Answer Retrieval (CAR) dataset. We evaluate both the generated answer and its corresponding structure and show the effectiveness of planning-based models in comparison to a text-to-text model.