 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards stable AI systems for Evaluating Arabic Pronunciations
Aug 27, 2025Modern Arabic ASR systems such as wav2vec 2.0 excel at word- and sentence-level transcription, yet struggle to classify isolated letters. In this study, we show that this phoneme-level task, crucial for language learning, speech therapy, and phonetic research, is challenging because isolated letters lack co-articulatory cues, provide no lexical context, and last only a few hundred milliseconds. Recogniser systems must therefore rely solely on variable acoustic cues, a difficulty heightened by Arabic's emphatic (pharyngealized) consonants and other sounds with no close analogues in many languages. This study introduces a diverse, diacritised corpus of isolated Arabic letters and demonstrates that state-of-the-art wav2vec 2.0 models achieve only 35% accuracy on it. Training a lightweight neural network on wav2vec embeddings raises performance to 65%. However, adding a small amplitude perturbation (epsilon = 0.05) cuts accuracy to 32%. To restore robustness, we apply adversarial training, limiting the noisy-speech drop to 9% while preserving clean-speech accuracy. We detail the corpus, training pipeline, and evaluation protocol, and release, on demand, data and code for reproducibility. Finally, we outline future work extending these methods to word- and sentence-level frameworks, where precise letter pronunciation remains critical.
Geomstats: A Python Package for Riemannian Geometry in Machine Learning
Apr 07, 2020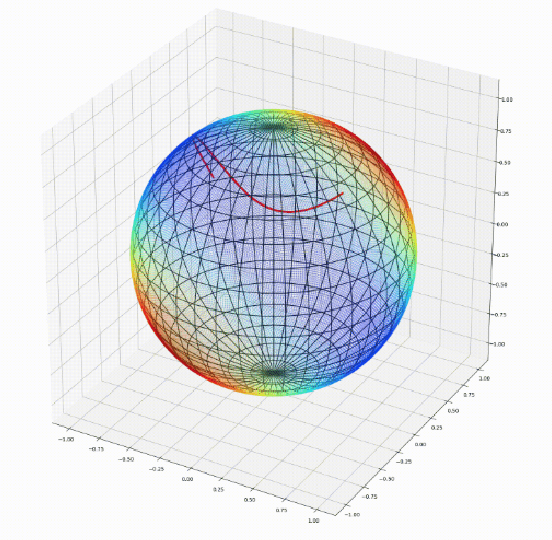
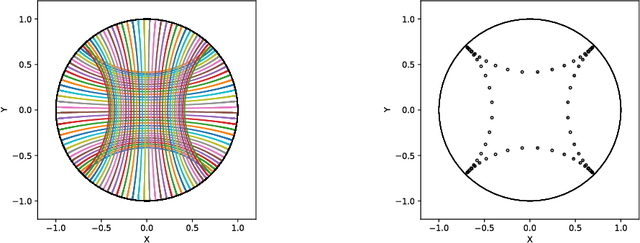

We introduce Geomstats, an open-source Python toolbox for computations and statistics on nonlinear manifolds, such as hyperbolic spaces, spaces of symmetric positive definite matrices, Lie groups of transformations, and many more. We provide object-oriented and extensively unit-tested implementations. Among others, manifolds come equipped with families of Riemannian metrics, with associated exponential and logarithmic maps, geodesics and parallel transport. Statistics and learning algorithms provide methods for estimation, clustering and dimension reduction on manifolds. All associated operations are vectorized for batch computation and provide support for different execution backends, namely NumPy, PyTorch and TensorFlow, enabling GPU acceleration. This paper presents the package, compares it with related libraries and provides relevant code examples. We show that Geomstats provides reliable building blocks to foster research in differential geometry and statistics, and to democratize the use of Riemannian geometry in machine learning applications. The source code is freely available under the MIT license at \url{geomstats.ai}.
Learning graph-structured data using Poincaré embeddings and Riemannian K-means algorithms
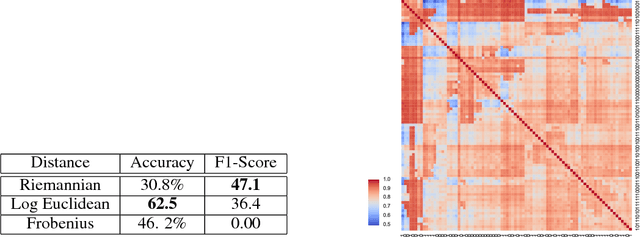
Jul 02, 2019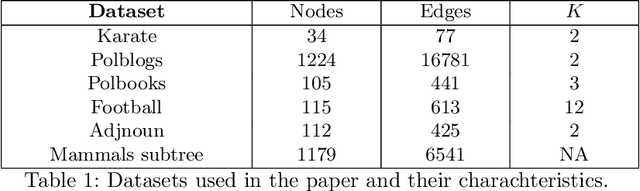
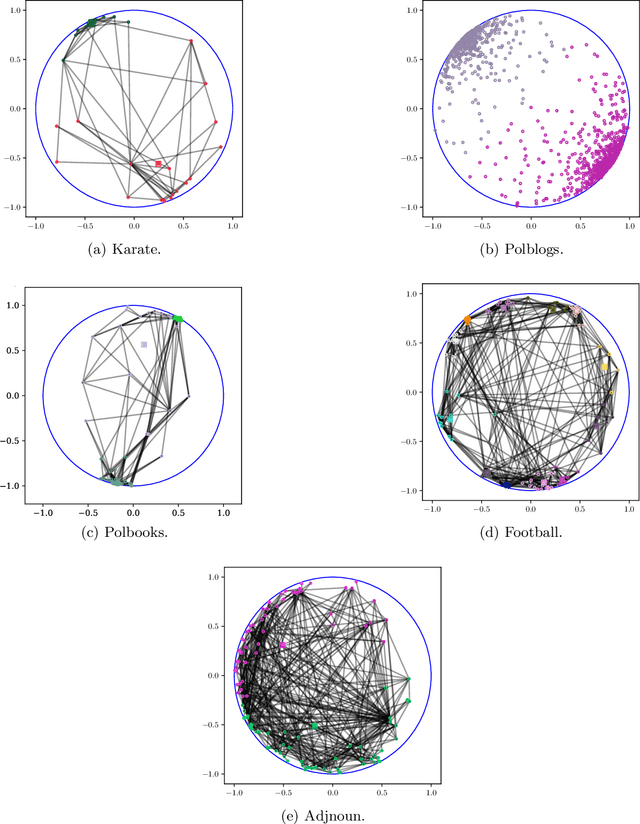

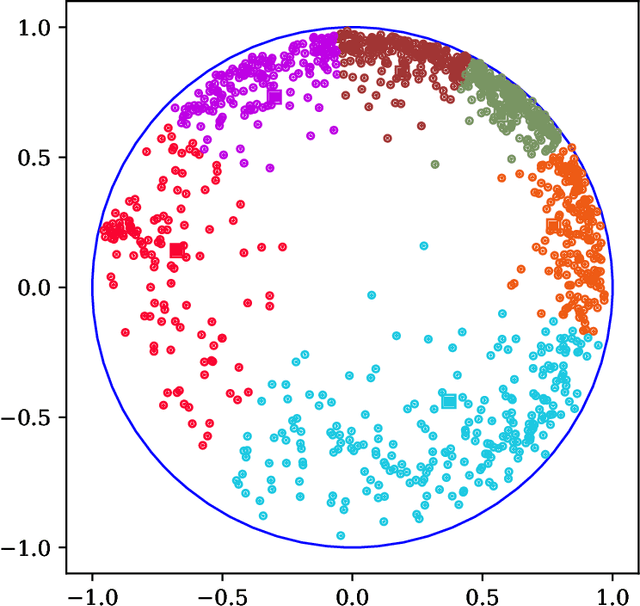
Recent literature has shown several benefits of hyperbolic embedding of graph-structured data (GSD) in representing their structures and latent relations. While several studies have explored the ability of hyperbolic embedding to represent data (for example, by quantifying their mean average precision) and their ability to produce better visualisations of clusters, only few works exploited the effectiveness of hyperbolic embedding to perform learning on the initial GSD. Motivated by innovative ideas from the fields of Brain computer interfaces and Radar processing, this paper presents a new scheme for learning GSD based on hyperbolic embedding, Riemannian barycentre (i.e. Fr\'echet or geometric mean) and $K$-means algorithms as a significant tool that derives from it. The main idea is as follows. Relying on the Riemannian barycentre, we define a notion of minimal variance which allows us to choose an embedding between different ones. This embedding is used thereafter together with $K$-means algorithms to perform unsupervised clustering and in combination with the nearest neighbour rule to perform supervised learning. We demonstrate the performance of the proposed framework through several experiments on real-world social networks and hierarchical GSD. The obtained results outperform their counterparts in high-dimensional Euclidean spaces and recent proposed geometric approaches.