 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented LLM Agents: Learning to Learn from Experience
Mar 18, 2026While large language models (LLMs) have advanced the development of general-purpose agents, achieving robust generalization to unseen tasks remains a significant challenge. Current approaches typically rely on either fine-tuning or training-free memory-augmented generation using retrieved experience; yet both have limitations: fine-tuning often fails to extrapolate to new tasks, while experience retrieval often underperforms compared to supervised baselines. In this work, we propose to combine these approaches and systematically study how to train retrieval-augmented LLM agents to effectively leverage retrieved trajectories in-context. First, we establish a robust supervised fine-tuning (SFT) recipe using LoRA that outperforms several state-of-the-art agent training pipelines. Second, we provide a detailed analysis of key design choices for experience retrieval, identifying optimal strategies for storage, querying, and trajectory selection. Finally, we propose a pipeline that integrates experience retrieval into the fine-tuning process. Our results demonstrate that this combined approach significantly improves generalization to unseen tasks, providing a scalable and effective framework for building agents that learn to learn from experience.
DiffLoRA: Differential Low-Rank Adapters for Large Language Models
Jul 31, 2025Differential Transformer has recently been proposed to improve performance in Transformer models by canceling out noise through a denoiser attention mechanism. In this work, we introduce DiffLoRA, a parameter-efficient adaptation of the differential attention mechanism, with low-rank adapters on both positive and negative attention terms. This approach retains the efficiency of LoRA while aiming to benefit from the performance gains of differential attention. We evaluate DiffLoRA across a broad range of NLP tasks, including general benchmarks, many-shot in-context learning, RAG, and long-context tests. We observe that, although DiffLoRA falls short of other parameter-efficient fine-tuning methods in most evaluation tasks, it shows interesting results in certain domains (+11 pts on LoRA for HumanEval). We analyze the attention patterns post-finetuning to identify the reasons for this behavior.
Adapting Large Language Models for Multi-Domain Retrieval-Augmented-Generation
Apr 03, 2025
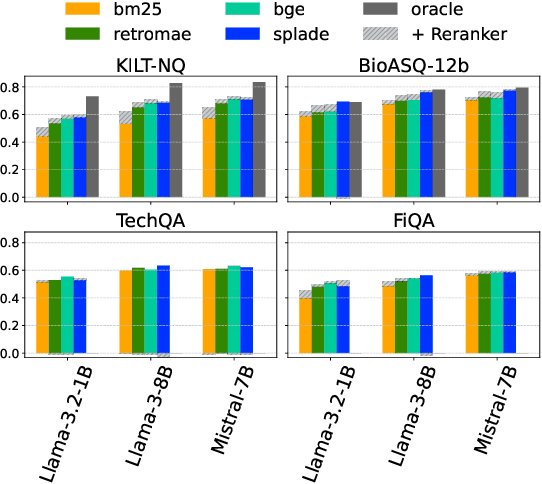
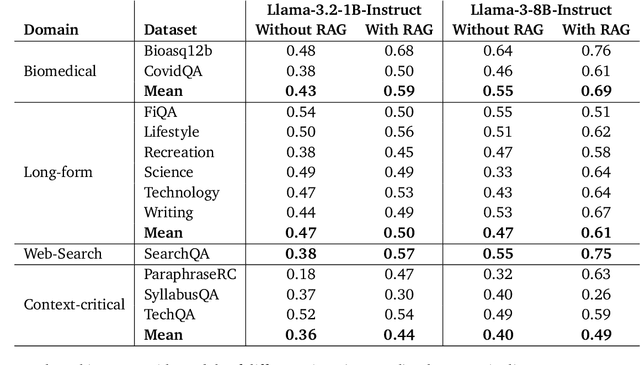
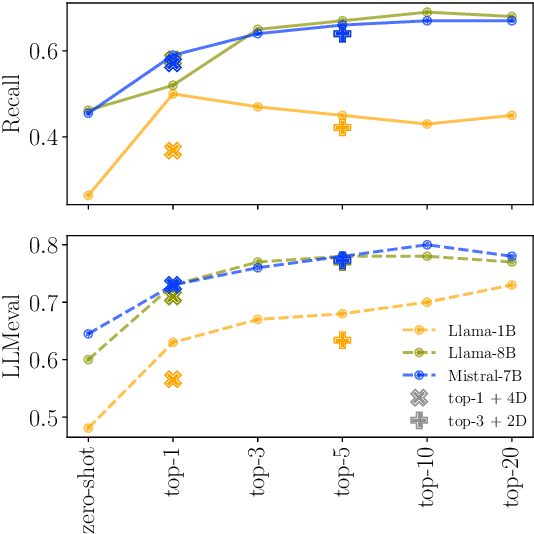
Retrieval-Augmented Generation (RAG) enhances LLM factuality, but multi-domain applications face challenges like lack of diverse benchmarks and poor out-of-domain generalization. The first contribution of this work is to introduce a diverse benchmark comprising a variety of question-answering tasks from 8 sources and covering 13 domains. Our second contribution consists in systematically testing out-of-domain generalization for typical RAG tuning strategies. While our findings reveal that standard fine-tuning fails to generalize effectively, we show that sequence-level distillation with teacher-generated labels improves out-of-domain performance by providing more coherent supervision. Our findings highlight key strategies for improving multi-domain RAG robustness.
Provence: efficient and robust context pruning for retrieval-augmented generation
Jan 27, 2025



Retrieval-augmented generation improves various aspects of large language models (LLMs) generation, but suffers from computational overhead caused by long contexts as well as the propagation of irrelevant retrieved information into generated responses. Context pruning deals with both aspects, by removing irrelevant parts of retrieved contexts before LLM generation. Existing context pruning approaches are however limited, and do not provide a universal model that would be both efficient and robust in a wide range of scenarios, e.g., when contexts contain a variable amount of relevant information or vary in length, or when evaluated on various domains. In this work, we close this gap and introduce Provence (Pruning and Reranking Of retrieVEd relevaNt ContExts), an efficient and robust context pruner for Question Answering, which dynamically detects the needed amount of pruning for a given context and can be used out-of-the-box for various domains. The three key ingredients of Provence are formulating the context pruning task as sequence labeling, unifying context pruning capabilities with context reranking, and training on diverse data. Our experimental results show that Provence enables context pruning with negligible to no drop in performance, in various domains and settings, at almost no cost in a standard RAG pipeline. We also conduct a deeper analysis alongside various ablations to provide insights into training context pruners for future work.
BERGEN: A Benchmarking Library for Retrieval-Augmented Generation
Jul 01, 2024



Retrieval-Augmented Generation allows to enhance Large Language Models with external knowledge. In response to the recent popularity of generative LLMs, many RAG approaches have been proposed, which involve an intricate number of different configurations such as evaluation datasets, collections, metrics, retrievers, and LLMs. Inconsistent benchmarking poses a major challenge in comparing approaches and understanding the impact of each component in the pipeline. In this work, we study best practices that lay the groundwork for a systematic evaluation of RAG and present BERGEN, an end-to-end library for reproducible research standardizing RAG experiments. In an extensive study focusing on QA, we benchmark different state-of-the-art retrievers, rerankers, and LLMs. Additionally, we analyze existing RAG metrics and datasets. Our open-source library BERGEN is available under \url{https://github.com/naver/bergen}.
Investigating the potential of Sparse Mixtures-of-Experts for multi-domain neural machine translation
Jul 01, 2024



We focus on multi-domain Neural Machine Translation, with the goal of developing efficient models which can handle data from various domains seen during training and are robust to domains unseen during training. We hypothesize that Sparse Mixture-of-Experts (SMoE) models are a good fit for this task, as they enable efficient model scaling, which helps to accommodate a variety of multi-domain data, and allow flexible sharing of parameters between domains, potentially enabling knowledge transfer between similar domains and limiting negative transfer. We conduct a series of experiments aimed at validating the utility of SMoE for the multi-domain scenario, and find that a straightforward width scaling of Transformer is a simpler and surprisingly more efficient approach in practice, and reaches the same performance level as SMoE. We also search for a better recipe for robustness of multi-domain systems, highlighting the importance of mixing-in a generic domain, i.e. Paracrawl, and introducing a simple technique, domain randomization.
Retrieval-augmented generation in multilingual settings
Jul 01, 2024



Retrieval-augmented generation (RAG) has recently emerged as a promising solution for incorporating up-to-date or domain-specific knowledge into large language models (LLMs) and improving LLM factuality, but is predominantly studied in English-only settings. In this work, we consider RAG in the multilingual setting (mRAG), i.e. with user queries and the datastore in 13 languages, and investigate which components and with which adjustments are needed to build a well-performing mRAG pipeline, that can be used as a strong baseline in future works. Our findings highlight that despite the availability of high-quality off-the-shelf multilingual retrievers and generators, task-specific prompt engineering is needed to enable generation in user languages. Moreover, current evaluation metrics need adjustments for multilingual setting, to account for variations in spelling named entities. The main limitations to be addressed in future works include frequent code-switching in non-Latin alphabet languages, occasional fluency errors, wrong reading of the provided documents, or irrelevant retrieval. We release the code for the resulting mRAG baseline pipeline at https://github.com/naver/bergen.
FrenchToxicityPrompts: a Large Benchmark for Evaluating and Mitigating Toxicity in French Texts
Jun 25, 2024



Large language models (LLMs) are increasingly popular but are also prone to generating bias, toxic or harmful language, which can have detrimental effects on individuals and communities. Although most efforts is put to assess and mitigate toxicity in generated content, it is primarily concentrated on English, while it's essential to consider other languages as well. For addressing this issue, we create and release FrenchToxicityPrompts, a dataset of 50K naturally occurring French prompts and their continuations, annotated with toxicity scores from a widely used toxicity classifier. We evaluate 14 different models from four prevalent open-sourced families of LLMs against our dataset to assess their potential toxicity across various dimensions. We hope that our contribution will foster future research on toxicity detection and mitigation beyond Englis
Zero-shot cross-lingual transfer in instruction tuning of large language model
Feb 22, 2024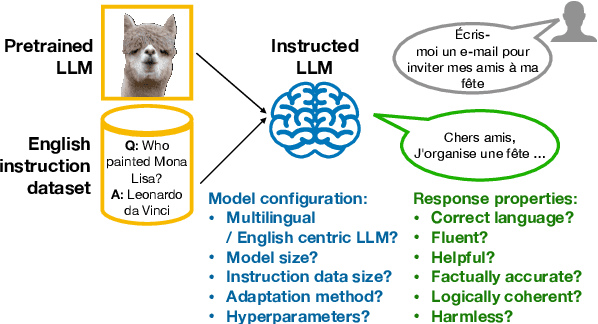
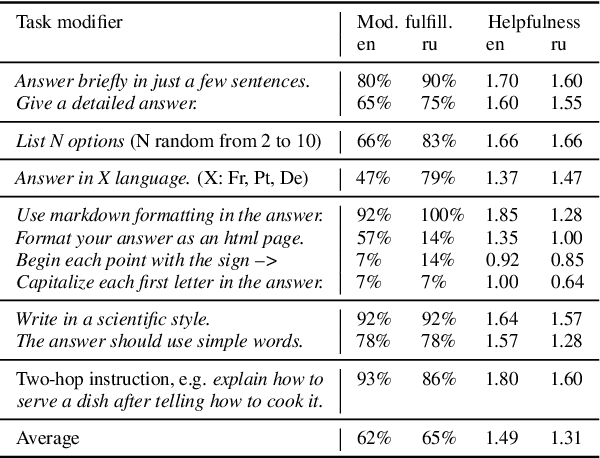
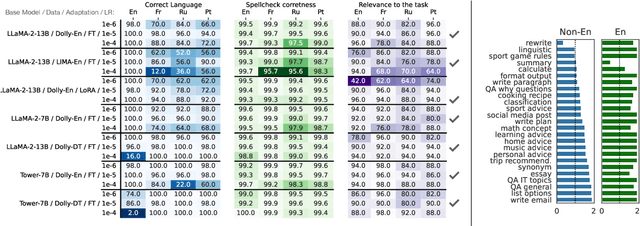

Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We investigate the influence of model configuration choices and devise a multi-facet evaluation strategy for multilingual instruction following. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in the other languages, but suffer from low factuality and may occasionally have fluency errors.
Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
Feb 19, 2024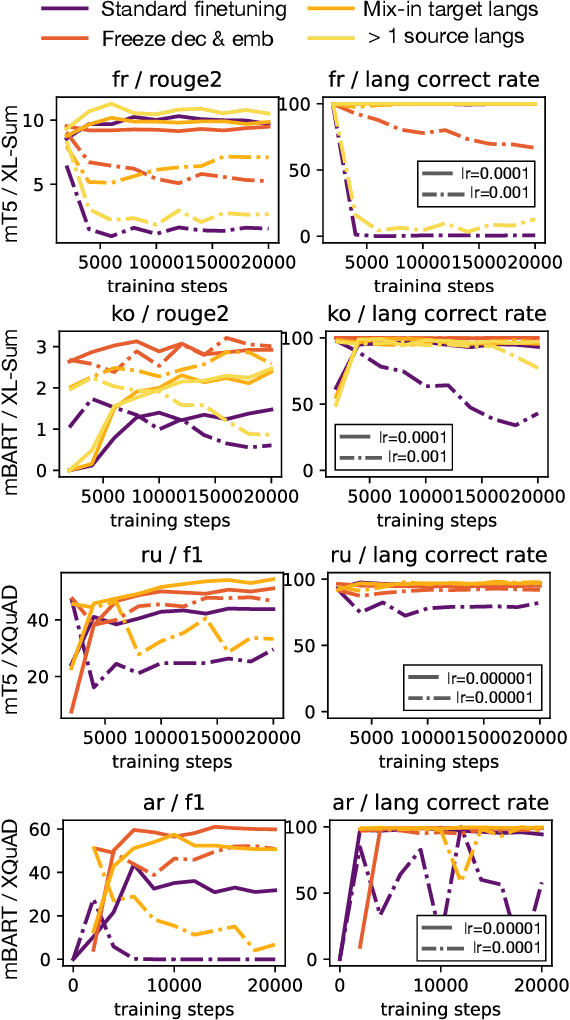
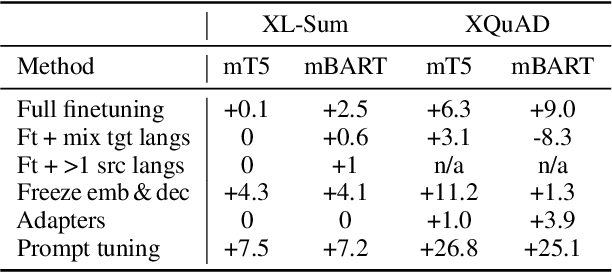

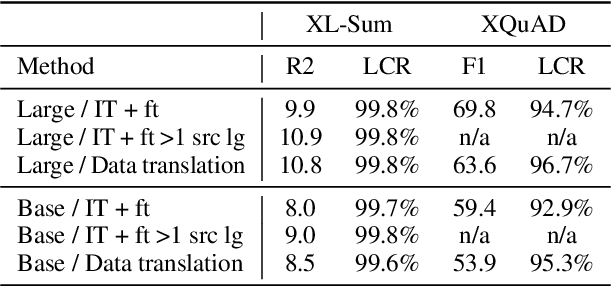
Zero-shot cross-lingual generation implies finetuning of the multilingual pretrained language model on a generation task in one language and then using it to make predictions for this task in other languages. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual generation.