 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective and Efficient Schema-aware Information Extraction Using On-Device Large Language Models
May 21, 2025Information extraction (IE) plays a crucial role in natural language processing (NLP) by converting unstructured text into structured knowledge. Deploying computationally intensive large language models (LLMs) on resource-constrained devices for information extraction is challenging, particularly due to issues like hallucinations, limited context length, and high latency-especially when handling diverse extraction schemas. To address these challenges, we propose a two-stage information extraction approach adapted for on-device LLMs, called Dual-LoRA with Incremental Schema Caching (DLISC), which enhances both schema identification and schema-aware extraction in terms of effectiveness and efficiency. In particular, DLISC adopts an Identification LoRA module for retrieving the most relevant schemas to a given query, and an Extraction LoRA module for performing information extraction based on the previously selected schemas. To accelerate extraction inference, Incremental Schema Caching is incorporated to reduce redundant computation, substantially improving efficiency. Extensive experiments across multiple information extraction datasets demonstrate notable improvements in both effectiveness and efficiency.
Adaptive Schema-aware Event Extraction with Retrieval-Augmented Generation
May 13, 2025Event extraction (EE) is a fundamental task in natural language processing (NLP) that involves identifying and extracting event information from unstructured text. Effective EE in real-world scenarios requires two key steps: selecting appropriate schemas from hundreds of candidates and executing the extraction process. Existing research exhibits two critical gaps: (1) the rigid schema fixation in existing pipeline systems, and (2) the absence of benchmarks for evaluating joint schema matching and extraction. Although large language models (LLMs) offer potential solutions, their schema hallucination tendencies and context window limitations pose challenges for practical deployment. In response, we propose Adaptive Schema-aware Event Extraction (ASEE), a novel paradigm combining schema paraphrasing with schema retrieval-augmented generation. ASEE adeptly retrieves paraphrased schemas and accurately generates targeted structures. To facilitate rigorous evaluation, we construct the Multi-Dimensional Schema-aware Event Extraction (MD-SEE) benchmark, which systematically consolidates 12 datasets across diverse domains, complexity levels, and language settings. Extensive evaluations on MD-SEE show that our proposed ASEE demonstrates strong adaptability across various scenarios, significantly improving the accuracy of event extraction.
From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs
Apr 22, 2025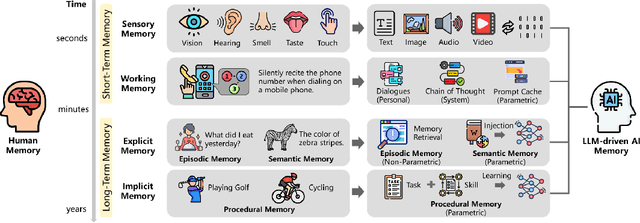
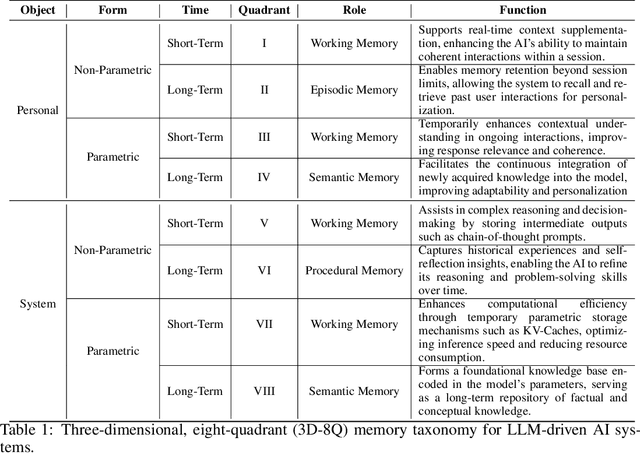
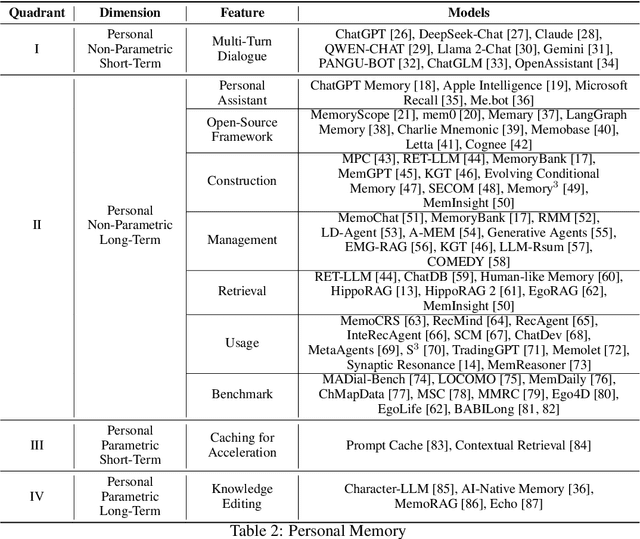
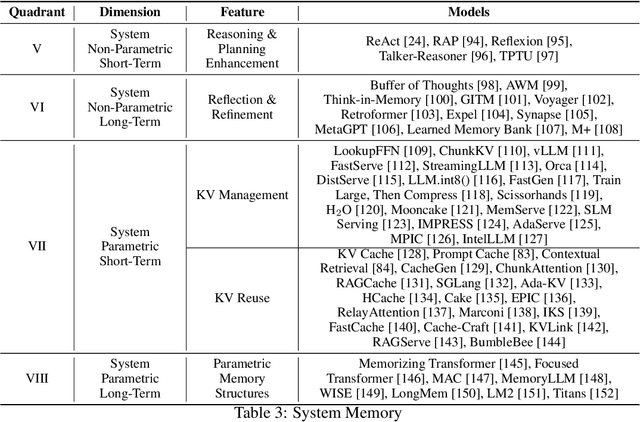
Memory is the process of encoding, storing, and retrieving information, allowing humans to retain experiences, knowledge, skills, and facts over time, and serving as the foundation for growth and effective interaction with the world. It plays a crucial role in shaping our identity, making decisions, learning from past experiences, building relationships, and adapting to changes. In the era of large language models (LLMs), memory refers to the ability of an AI system to retain, recall, and use information from past interactions to improve future responses and interactions. Although previous research and reviews have provided detailed descriptions of memory mechanisms, there is still a lack of a systematic review that summarizes and analyzes the relationship between the memory of LLM-driven AI systems and human memory, as well as how we can be inspired by human memory to construct more powerful memory systems. To achieve this, in this paper, we propose a comprehensive survey on the memory of LLM-driven AI systems. In particular, we first conduct a detailed analysis of the categories of human memory and relate them to the memory of AI systems. Second, we systematically organize existing memory-related work and propose a categorization method based on three dimensions (object, form, and time) and eight quadrants. Finally, we illustrate some open problems regarding the memory of current AI systems and outline possible future directions for memory in the era of large language models.
From Classification to Generation: Insights into Crosslingual Retrieval Augmented ICL
Nov 14, 2023



The remarkable ability of Large Language Models (LLMs) to understand and follow instructions has sometimes been limited by their in-context learning (ICL) performance in low-resource languages. To address this, we introduce a novel approach that leverages cross-lingual retrieval-augmented in-context learning (CREA-ICL). By extracting semantically similar prompts from high-resource languages, we aim to improve the zero-shot performance of multilingual pre-trained language models (MPLMs) across diverse tasks. Though our approach yields steady improvements in classification tasks, it faces challenges in generation tasks. Our evaluation offers insights into the performance dynamics of retrieval-augmented in-context learning across both classification and generation domains.
Crosslingual Retrieval Augmented In-context Learning for Bangla
Nov 01, 2023



The promise of Large Language Models (LLMs) in Natural Language Processing has often been overshadowed by their limited performance in low-resource languages such as Bangla. To address this, our paper presents a pioneering approach that utilizes cross-lingual retrieval augmented in-context learning. By strategically sourcing semantically similar prompts from high-resource language, we enable multilingual pretrained language models (MPLMs), especially the generative model BLOOMZ, to successfully boost performance on Bangla tasks. Our extensive evaluation highlights that the cross-lingual retrieval augmented prompts bring steady improvements to MPLMs over the zero-shot performance.
Empirical study of pretrained multilingual language models for zero-shot cross-lingual generation
Oct 15, 2023Zero-shot cross-lingual generation assumes finetuning the multilingual pretrained language model (mPLM) on a generation task in one language and then using it to make predictions for this task in other languages. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work, we test alternative mPLMs, such as mBART and NLLB, considering full finetuning and parameter-efficient finetuning with adapters. We find that mBART with adapters performs similarly to mT5 of the same size, and NLLB can be competitive in some cases. We also underline the importance of tuning learning rate used for finetuning, which helps to alleviate the problem of generation in the wrong language.
Cross-Lingual Retrieval Augmented Prompt for Low-Resource Languages
Dec 19, 2022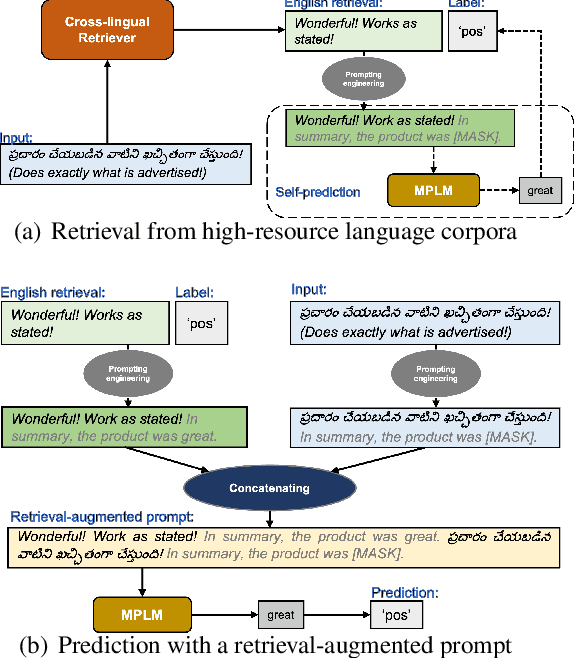



Multilingual Pretrained Language Models (MPLMs) have shown their strong multilinguality in recent empirical cross-lingual transfer studies. In this paper, we propose the Prompts Augmented by Retrieval Crosslingually (PARC) pipeline to improve the zero-shot performance on low-resource languages (LRLs) by augmenting the context with semantically similar sentences retrieved from a high-resource language (HRL) as prompts. PARC improves the zero-shot performance on three downstream tasks (binary sentiment classification, topic categorization and natural language inference) with multilingual parallel test sets across 10 LRLs covering 6 language families in both unlabeled settings (+5.1%) and labeled settings (+16.3%). PARC-labeled also outperforms the finetuning baseline by 3.7%. We find a significant positive correlation between cross-lingual transfer performance on one side, and the similarity between the high- and low-resource languages as well as the amount of low-resource pretraining data on the other side. A robustness analysis suggests that PARC has the potential to achieve even stronger performance with more powerful MPLMs.
Modular and Parameter-Efficient Multimodal Fusion with Prompting
Mar 15, 2022



Recent research has made impressive progress in large-scale multimodal pre-training. In the context of the rapid growth of model size, it is necessary to seek efficient and flexible methods other than finetuning. In this paper, we propose to use prompt vectors to align the modalities. Our method achieves comparable performance to several other multimodal fusion methods in low-resource settings. We further show that our method is modular and parameter-efficient for processing tasks involving two or more data modalities.
Locating Language-Specific Information in Contextualized Embeddings
Sep 16, 2021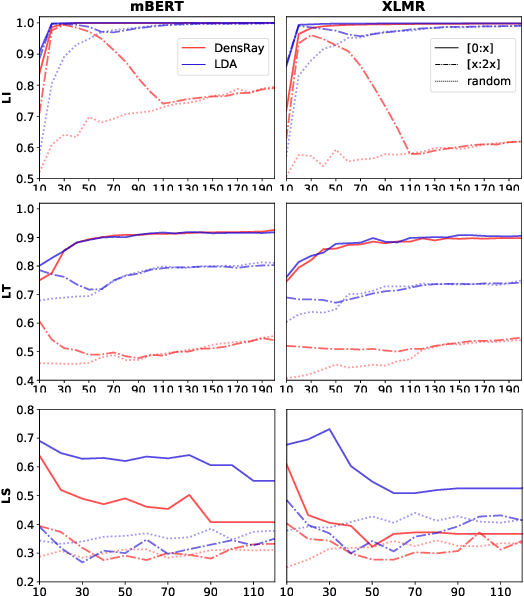
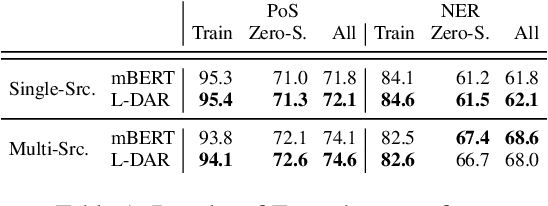
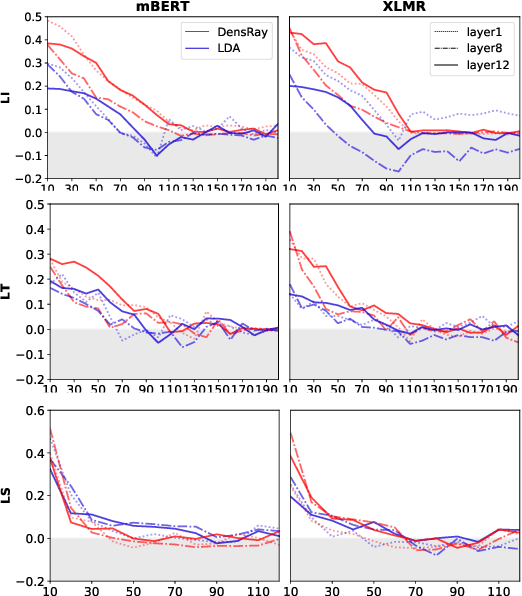
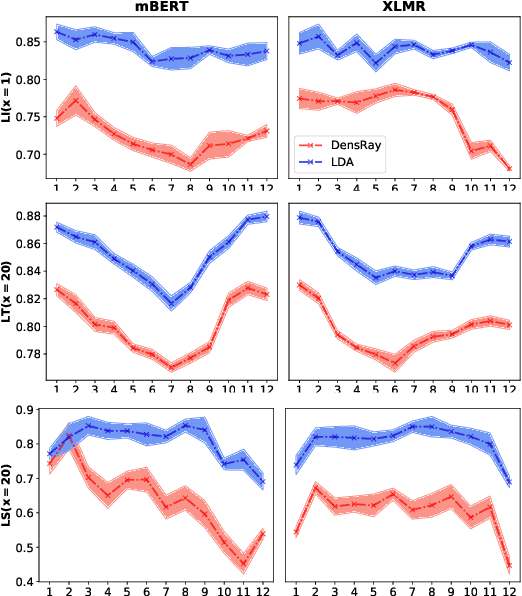
Multilingual pretrained language models (MPLMs) exhibit multilinguality and are well suited for transfer across languages. Most MPLMs are trained in an unsupervised fashion and the relationship between their objective and multilinguality is unclear. More specifically, the question whether MPLM representations are language-agnostic or they simply interleave well with learned task prediction heads arises. In this work, we locate language-specific information in MPLMs and identify its dimensionality and the layers where this information occurs. We show that language-specific information is scattered across many dimensions, which can be projected into a linear subspace. Our study contributes to a better understanding of MPLM representations, going beyond treating them as unanalyzable blobs of information.