 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateful Person or Hateful Model? Investigating the Role of Personas in Hate Speech Detection by Large Language Models
Jun 10, 2025Hate speech detection is a socially sensitive and inherently subjective task, with judgments often varying based on personal traits. While prior work has examined how socio-demographic factors influence annotation, the impact of personality traits on Large Language Models (LLMs) remains largely unexplored. In this paper, we present the first comprehensive study on the role of persona prompts in hate speech classification, focusing on MBTI-based traits. A human annotation survey confirms that MBTI dimensions significantly affect labeling behavior. Extending this to LLMs, we prompt four open-source models with MBTI personas and evaluate their outputs across three hate speech datasets. Our analysis uncovers substantial persona-driven variation, including inconsistencies with ground truth, inter-persona disagreement, and logit-level biases. These findings highlight the need to carefully define persona prompts in LLM-based annotation workflows, with implications for fairness and alignment with human values.
EXECUTE: A Multilingual Benchmark for LLM Token Understanding
May 23, 2025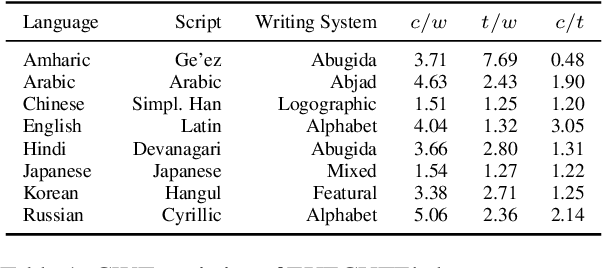
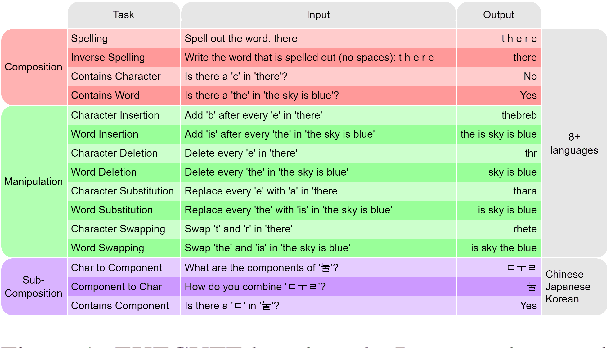
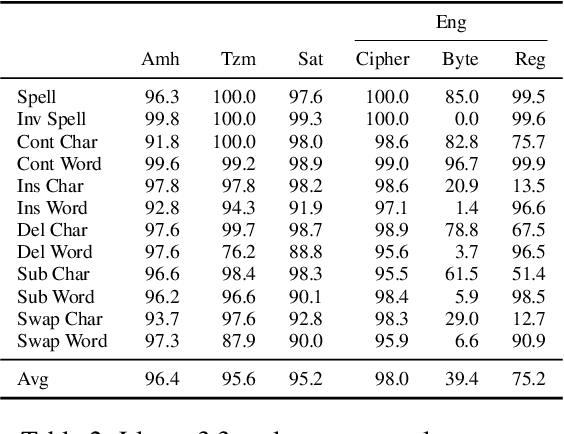
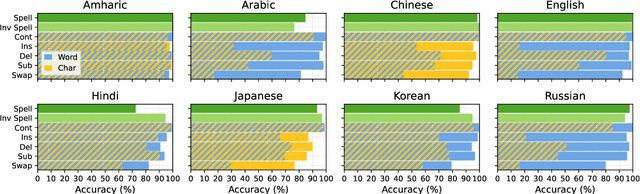
The CUTE benchmark showed that LLMs struggle with character understanding in English. We extend it to more languages with diverse scripts and writing systems, introducing EXECUTE. Our simplified framework allows easy expansion to any language. Tests across multiple LLMs reveal that challenges in other languages are not always on the character level as in English. Some languages show word-level processing issues, some show no issues at all. We also examine sub-character tasks in Chinese, Japanese, and Korean to assess LLMs' understanding of character components.
Mechanistic Understanding and Mitigation of Language Confusion in English-Centric Large Language Models
May 22, 2025Language confusion -- where large language models (LLMs) generate unintended languages against the user's need -- remains a critical challenge, especially for English-centric models. We present the first mechanistic interpretability (MI) study of language confusion, combining behavioral benchmarking with neuron-level analysis. Using the Language Confusion Benchmark (LCB), we show that confusion points (CPs) -- specific positions where language switches occur -- are central to this phenomenon. Through layer-wise analysis with TunedLens and targeted neuron attribution, we reveal that transition failures in the final layers drive confusion. We further demonstrate that editing a small set of critical neurons, identified via comparative analysis with multilingual-tuned models, substantially mitigates confusion without harming general competence or fluency. Our approach matches multilingual alignment in confusion reduction for most languages and yields cleaner, higher-quality outputs. These findings provide new insights into the internal dynamics of LLMs and highlight neuron-level interventions as a promising direction for robust, interpretable multilingual language modeling.
XCOMPS: A Multilingual Benchmark of Conceptual Minimal Pairs
Feb 27, 2025



We introduce XCOMPS in this work, a multilingual conceptual minimal pair dataset covering 17 languages. Using this dataset, we evaluate LLMs' multilingual conceptual understanding through metalinguistic prompting, direct probability measurement, and neurolinguistic probing. By comparing base, instruction-tuned, and knowledge-distilled models, we find that: 1) LLMs exhibit weaker conceptual understanding for low-resource languages, and accuracy varies across languages despite being tested on the same concept sets. 2) LLMs excel at distinguishing concept-property pairs that are visibly different but exhibit a marked performance drop when negative pairs share subtle semantic similarities. 3) Instruction tuning improves performance in concept understanding but does not enhance internal competence; knowledge distillation can enhance internal competence in conceptual understanding for low-resource languages with limited gains in explicit task performance. 4) More morphologically complex languages yield lower concept understanding scores and require deeper layers for conceptual reasoning.
Language Model Re-rankers are Steered by Lexical Similarities
Feb 24, 2025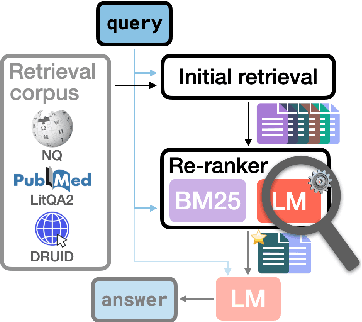
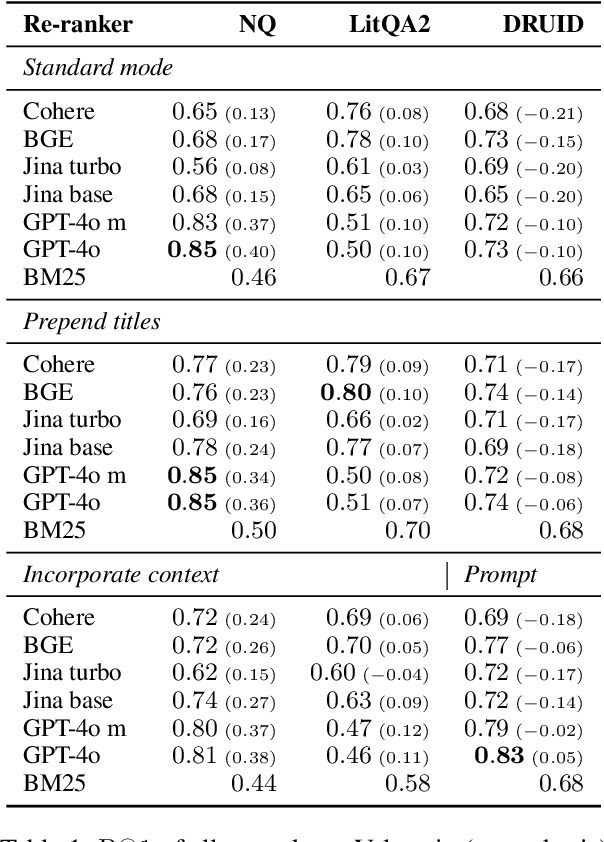
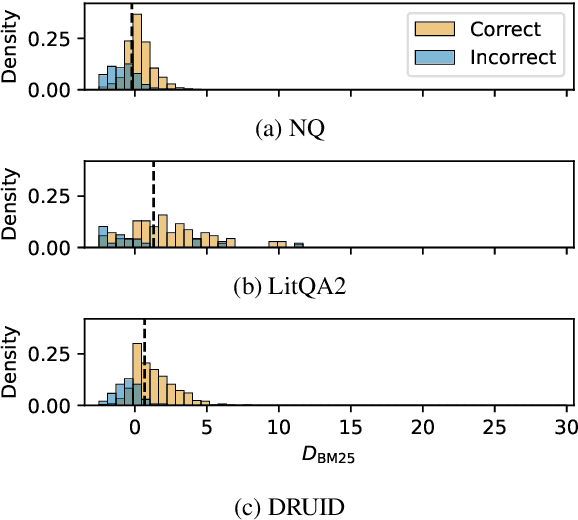
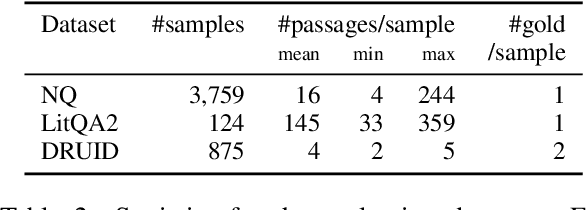
Language model (LM) re-rankers are used to refine retrieval results for retrieval-augmented generation (RAG). They are more expensive than lexical matching methods like BM25 but assumed to better process semantic information. To understand whether LM re-rankers always live up to this assumption, we evaluate 6 different LM re-rankers on the NQ, LitQA2 and DRUID datasets. Our results show that LM re-rankers struggle to outperform a simple BM25 re-ranker on DRUID. Leveraging a novel separation metric based on BM25 scores, we explain and identify re-ranker errors stemming from lexical dissimilarities. We also investigate different methods to improve LM re-ranker performance and find these methods mainly useful for NQ. Taken together, our work identifies and explains weaknesses of LM re-rankers and points to the need for more adversarial and realistic datasets for their evaluation.
Large Language Models as Neurolinguistic Subjects: Identifying Internal Representations for Form and Meaning
Nov 12, 2024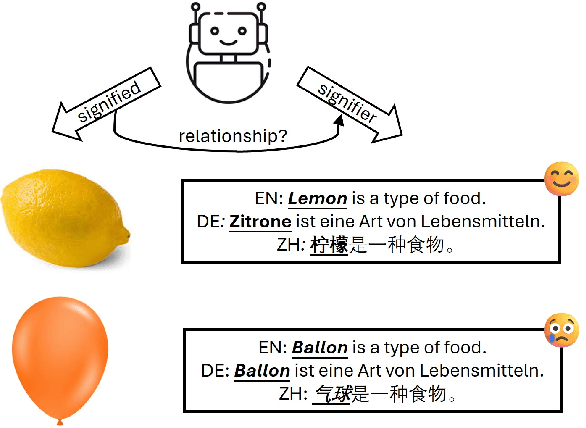
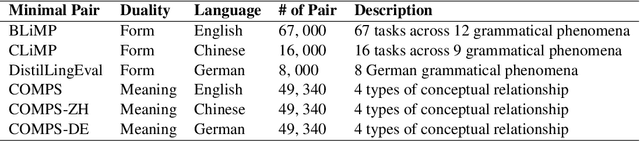
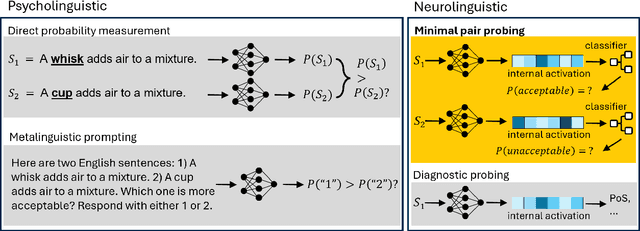
This study investigates the linguistic understanding of Large Language Models (LLMs) regarding signifier (form) and signified (meaning) by distinguishing two LLM evaluation paradigms: psycholinguistic and neurolinguistic. Traditional psycholinguistic evaluations often reflect statistical biases that may misrepresent LLMs' true linguistic capabilities. We introduce a neurolinguistic approach, utilizing a novel method that combines minimal pair and diagnostic probing to analyze activation patterns across model layers. This method allows for a detailed examination of how LLMs represent form and meaning, and whether these representations are consistent across languages. Our contributions are three-fold: (1) We compare neurolinguistic and psycholinguistic methods, revealing distinct patterns in LLM assessment; (2) We demonstrate that LLMs exhibit higher competence in form compared to meaning, with the latter largely correlated to the former; (3) We present new conceptual minimal pair datasets for Chinese (COMPS-ZH) and German (COMPS-DE), complementing existing English datasets.
BMIKE-53: Investigating Cross-Lingual Knowledge Editing with In-Context Learning
Jun 25, 2024
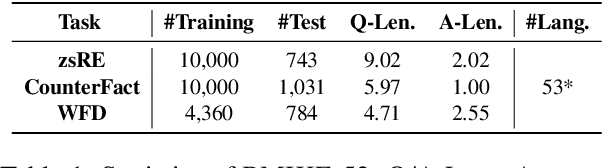
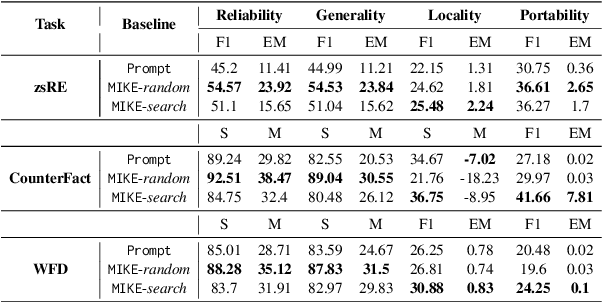
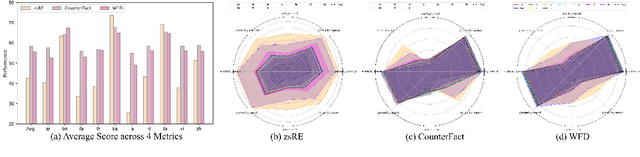
Large language models (LLMs) possess extensive parametric knowledge, but this knowledge is difficult to update with new information because retraining is very expensive and infeasible for closed-source models. Knowledge editing (KE) has emerged as a viable solution for updating the knowledge of LLMs without compromising their overall performance. On-the-fly KE methods, inspired by in-context learning (ICL), have shown great promise and allow LLMs to be treated as black boxes. In the past, KE was primarily employed in English contexts, whereas the potential for cross-lingual KE in current English-centric LLMs has not been fully explored. To foster more research in this direction, we introduce the BMIKE-53 benchmark for evaluating cross-lingual KE on 53 diverse languages across three KE task types. We also propose a gradient-free KE method called Multilingual In-context Knowledge Editing (MIKE) and evaluate it on BMIKE-53. Our evaluation focuses on cross-lingual knowledge transfer in terms of reliability, generality, locality, and portability, offering valuable insights and a framework for future research in cross-lingual KE. Our code and data are publicly accessible via the anonymous repository at https://anonymous.4open.science/r/MIKE.
Decomposed Prompting: Unveiling Multilingual Linguistic Structure Knowledge in English-Centric Large Language Models
Feb 28, 2024



Despite the predominance of English in their training data, English-centric Large Language Models (LLMs) like GPT-3 and LLaMA display a remarkable ability to perform multilingual tasks, raising questions about the depth and nature of their cross-lingual capabilities. This paper introduces the decomposed prompting approach to probe the linguistic structure understanding of these LLMs in sequence labeling tasks. Diverging from the single text-to-text prompt, our method generates for each token of the input sentence an individual prompt which asks for its linguistic label. We assess our method on the Universal Dependencies part-of-speech tagging dataset for 38 languages, utilizing both English-centric and multilingual LLMs. Our findings show that decomposed prompting surpasses the iterative prompting baseline in efficacy and efficiency under zero- and few-shot settings. Further analysis reveals the influence of evaluation methods and the use of instructions in prompts. Our multilingual investigation shows that English-centric language models perform better on average than multilingual models. Our study offers insights into the multilingual transferability of English-centric LLMs, contributing to the understanding of their multilingual linguistic knowledge.
GNNavi: Navigating the Information Flow in Large Language Models by Graph Neural Network
Feb 18, 2024Large Language Models (LLMs) exhibit strong In-Context Learning (ICL) capabilities when prompts with demonstrations are applied to them. However, fine-tuning still remains crucial to further enhance their adaptability. Prompt-based fine-tuning proves to be an effective fine-tuning method in low-data scenarios, but high demands on computing resources limit its practicality. We address this issue by introducing a prompt-based parameter-efficient fine-tuning (PEFT) approach. GNNavi leverages insights into ICL's information flow dynamics, which indicates that label words act in prompts as anchors for information propagation. GNNavi employs a Graph Neural Network (GNN) layer to precisely guide the aggregation and distribution of information flow during the processing of prompts by hardwiring the desired information flow into the GNN. Our experiments on text classification tasks with GPT-2 and Llama2 shows GNNavi surpasses standard prompt-based fine-tuning methods in few-shot settings by updating just 0.2% to 0.5% of parameters. We compare GNNavi with prevalent PEFT approaches, such as prefix tuning, LoRA and Adapter in terms of performance and efficiency. Our analysis reveals that GNNavi enhances information flow and ensures a clear aggregation process.
ToPro: Token-Level Prompt Decomposition for Cross-Lingual Sequence Labeling Tasks
Jan 29, 2024
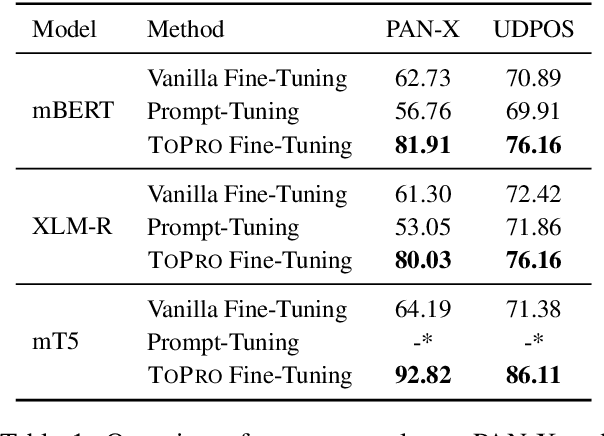
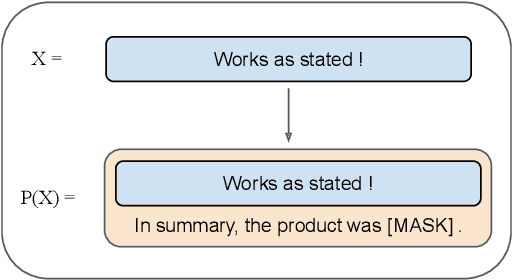
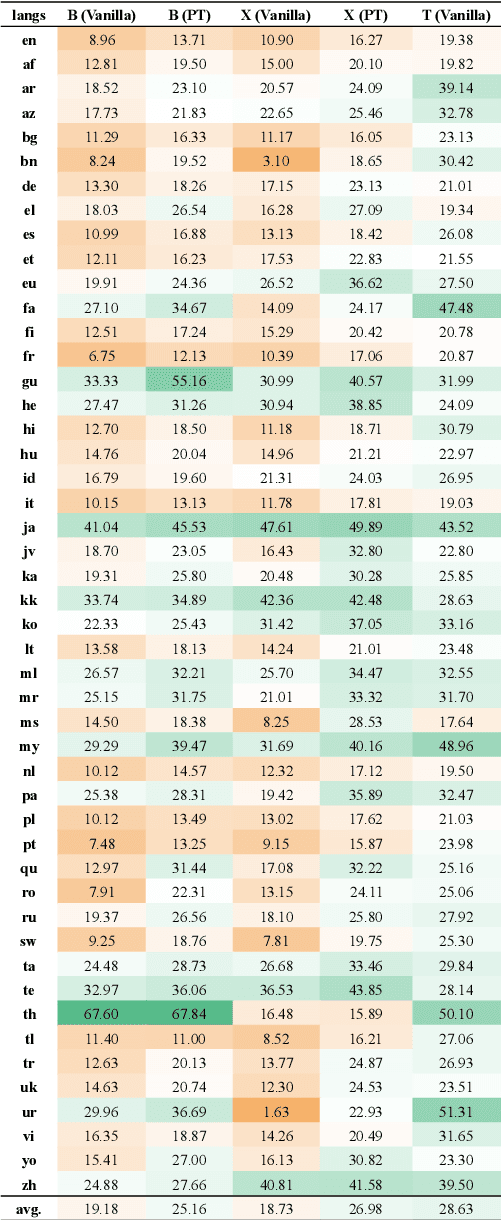
Prompt-based methods have been successfully applied to multilingual pretrained language models for zero-shot cross-lingual understanding. However, most previous studies primarily focused on sentence-level classification tasks, and only a few considered token-level labeling tasks such as Named Entity Recognition (NER) and Part-of-Speech (POS) tagging. In this paper, we propose Token-Level Prompt Decomposition (ToPro), which facilitates the prompt-based method for token-level sequence labeling tasks. The ToPro method decomposes an input sentence into single tokens and applies one prompt template to each token. Our experiments on multilingual NER and POS tagging datasets demonstrate that ToPro-based fine-tuning outperforms Vanilla fine-tuning and Prompt-Tuning in zero-shot cross-lingual transfer, especially for languages that are typologically different from the source language English. Our method also attains state-of-the-art performance when employed with the mT5 model. Besides, our exploratory study in multilingual large language models shows that ToPro performs much better than the current in-context learning method. Overall, the performance improvements show that ToPro could potentially serve as a novel and simple benchmarking method for sequence labeling tasks.