 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Factual Recall Mechanisms Carry over from Text to Speech in Multimodal Language Models?
May 21, 2026In recent years, several Speech Language Models (SLMs) that represent speech and written text jointly have been presented. The question then emerges about how model-internal mechanisms are similar and different when operating in the two modalities. We focus on how these systems encode, store, and retrieve factual knowledge, which has previously been investigated for text-only models. To investigate mechanisms behind the storage and recall of factual association in SLMs, we leverage Causal Mediation Analysis, a technique previously applied to text-based models. Initial results using SpiritLM, a multimodal model integrating discrete speech tokens reveal discrepancies between text-to-text and speech-to-text results, suggesting that the emergent mechanisms for factual recall are only partially carried over from the text to the speech modality. These results advance our understanding of how internal mechanisms encode factual associations in SLMs while contributing insights for improving speech-enabled AI systems.
To Copy or Not to Copy: Copying Is Easier to Induce Than Recall
Jan 17, 2026Language models used in retrieval-augmented settings must arbitrate between parametric knowledge stored in their weights and contextual information in the prompt. This work presents a mechanistic study of that choice by extracting an \emph{arbitration vector} from model activations on a curated dataset designed to disentangle (i) irrelevant contexts that elicit parametric recall and (ii) relevant but false contexts that elicit copying. The vector is computed as the residual-stream centroid difference between these regimes across 27 relations, and is injected as an additive intervention at selected layers and token spans to steer behavior in two directions: Copy$\rightarrow$Recall (suppressing context use) and Recall$\rightarrow$Copy (inducing the model to copy any token from the context). Experiments on two architectures (decoder-only and encoder/decoder) and two open-domain QA benchmarks show consistent behavior shifts under moderate scaling while monitoring accuracy and fluency. Mechanistic analyses of attention routing, MLP contributions, and layer-wise probability trajectories reveal an asymmetry: inducing copying is an easy ``reactivation'' process that can be triggered at different locations in the input, while restoring recall is a ``suppression'' process that is more fragile and strongly tied to object-token interventions.
Detecting and Mitigating Treatment Leakage in Text-Based Causal Inference: Distillation and Sensitivity Analysis
Dec 30, 2025Text-based causal inference increasingly employs textual data as proxies for unobserved confounders, yet this approach introduces a previously undertheorized source of bias: treatment leakage. Treatment leakage occurs when text intended to capture confounding information also contains signals predictive of treatment status, thereby inducing post-treatment bias in causal estimates. Critically, this problem can arise even when documents precede treatment assignment, as authors may employ future-referencing language that anticipates subsequent interventions. Despite growing recognition of this issue, no systematic methods exist for identifying and mitigating treatment leakage in text-as-confounder applications. This paper addresses this gap through three contributions. First, we provide formal statistical and set-theoretic definitions of treatment leakage that clarify when and why bias occurs. Second, we propose four text distillation methods -- similarity-based passage removal, distant supervision classification, salient feature removal, and iterative nullspace projection -- designed to eliminate treatment-predictive content while preserving confounder information. Third, we validate these methods through simulations using synthetic text and an empirical application examining International Monetary Fund structural adjustment programs and child mortality. Our findings indicate that moderate distillation optimally balances bias reduction against confounder retention, whereas overly stringent approaches degrade estimate precision.
Benchmarking Debiasing Methods for LLM-based Parameter Estimates
Jun 11, 2025Large language models (LLMs) offer an inexpensive yet powerful way to annotate text, but are often inconsistent when compared with experts. These errors can bias downstream estimates of population parameters such as regression coefficients and causal effects. To mitigate this bias, researchers have developed debiasing methods such as Design-based Supervised Learning (DSL) and Prediction-Powered Inference (PPI), which promise valid estimation by combining LLM annotations with a limited number of expensive expert annotations. Although these methods produce consistent estimates under theoretical assumptions, it is unknown how they compare in finite samples of sizes encountered in applied research. We make two contributions: First, we study how each method's performance scales with the number of expert annotations, highlighting regimes where LLM bias or limited expert labels significantly affect results. Second, we compare DSL and PPI across a range of tasks, finding that although both achieve low bias with large datasets, DSL often outperforms PPI on bias reduction and empirical efficiency, but its performance is less consistent across datasets. Our findings indicate that there is a bias-variance tradeoff at the level of debiasing methods, calling for more research on developing metrics for quantifying their efficiency in finite samples.
CUB: Benchmarking Context Utilisation Techniques for Language Models
May 22, 2025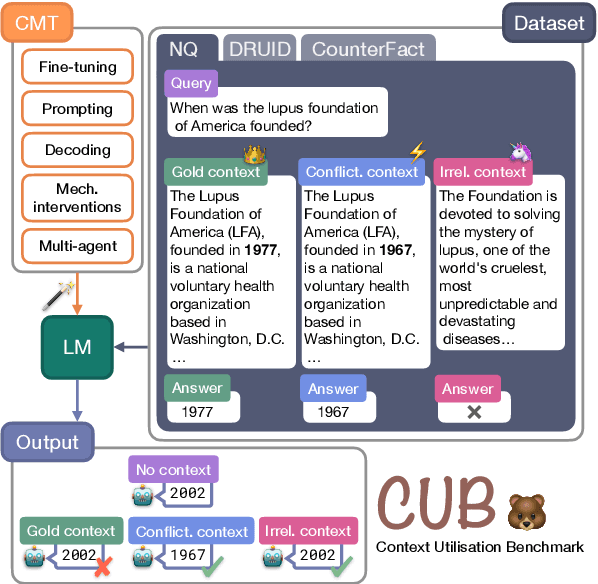



Incorporating external knowledge is crucial for knowledge-intensive tasks, such as question answering and fact checking. However, language models (LMs) may ignore relevant information that contradicts outdated parametric memory or be distracted by irrelevant contexts. While many context utilisation manipulation techniques (CMTs) that encourage or suppress context utilisation have recently been proposed to alleviate these issues, few have seen systematic comparison. In this paper, we develop CUB (Context Utilisation Benchmark) to help practitioners within retrieval-augmented generation (RAG) identify the best CMT for their needs. CUB allows for rigorous testing on three distinct context types, observed to capture key challenges in realistic context utilisation scenarios. With this benchmark, we evaluate seven state-of-the-art methods, representative of the main categories of CMTs, across three diverse datasets and tasks, applied to nine LMs. Our results show that most of the existing CMTs struggle to handle the full set of types of contexts that may be encountered in real-world retrieval-augmented scenarios. Moreover, we find that many CMTs display an inflated performance on simple synthesised datasets, compared to more realistic datasets with naturally occurring samples. Altogether, our results show the need for holistic tests of CMTs and the development of CMTs that can handle multiple context types.
Language Model Re-rankers are Steered by Lexical Similarities
Feb 24, 2025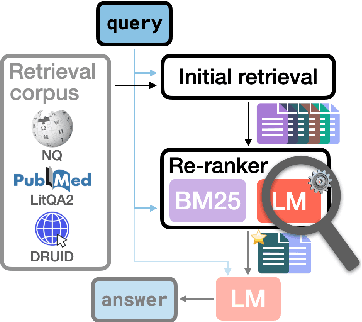
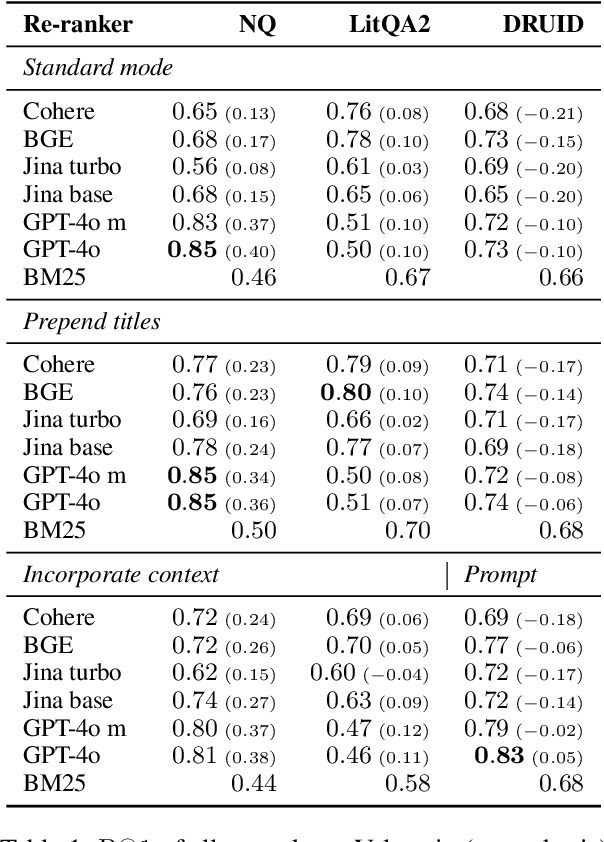
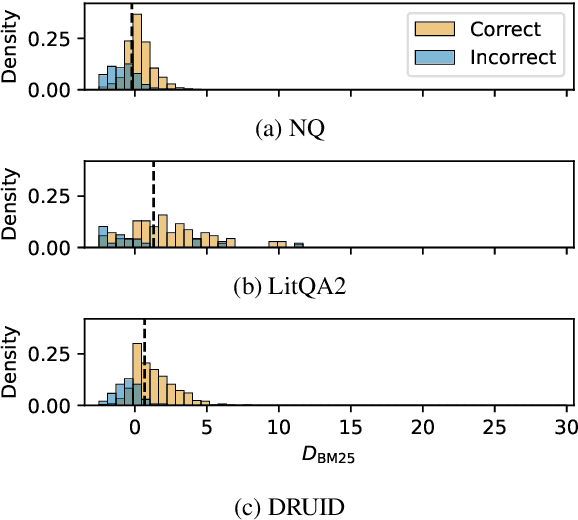
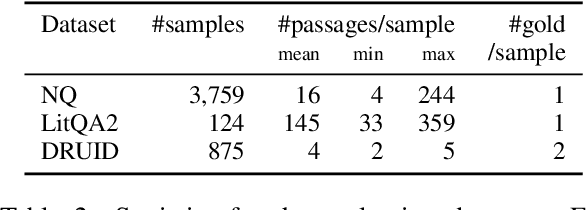
Language model (LM) re-rankers are used to refine retrieval results for retrieval-augmented generation (RAG). They are more expensive than lexical matching methods like BM25 but assumed to better process semantic information. To understand whether LM re-rankers always live up to this assumption, we evaluate 6 different LM re-rankers on the NQ, LitQA2 and DRUID datasets. Our results show that LM re-rankers struggle to outperform a simple BM25 re-ranker on DRUID. Leveraging a novel separation metric based on BM25 scores, we explain and identify re-ranker errors stemming from lexical dissimilarities. We also investigate different methods to improve LM re-ranker performance and find these methods mainly useful for NQ. Taken together, our work identifies and explains weaknesses of LM re-rankers and points to the need for more adversarial and realistic datasets for their evaluation.
How Well Do Large Language Models Disambiguate Swedish Words?
Oct 30, 2024



We evaluate a battery of recent large language models on two benchmarks for word sense disambiguation in Swedish. At present, all current models are less accurate than the best supervised disambiguators in cases where a training set is available, but most models outperform graph-based unsupervised systems. Different prompting approaches are compared, with a focus on how to express the set of possible senses in a given context. The best accuracies are achieved when human-written definitions of the senses are included in the prompts.
Fact Recall, Heuristics or Pure Guesswork? Precise Interpretations of Language Models for Fact Completion
Oct 18, 2024Previous interpretations of language models (LMs) miss important distinctions in how these models process factual information. For example, given the query "Astrid Lindgren was born in" with the corresponding completion "Sweden", no difference is made between whether the prediction was based on having the exact knowledge of the birthplace of the Swedish author or assuming that a person with a Swedish-sounding name was born in Sweden. In this paper, we investigate four different prediction scenarios for which the LM can be expected to show distinct behaviors. These scenarios correspond to different levels of model reliability and types of information being processed - some being less desirable for factual predictions. To facilitate precise interpretations of LMs for fact completion, we propose a model-specific recipe called PrISM for constructing datasets with examples of each scenario based on a set of diagnostic criteria. We apply a popular interpretability method, causal tracing (CT), to the four prediction scenarios and find that while CT produces different results for each scenario, aggregations over a set of mixed examples may only represent the results from the scenario with the strongest measured signal. In summary, we contribute tools for a more granular study of fact completion in language models and analyses that provide a more nuanced understanding of how LMs process fact-related queries.
Deciphering the Interplay of Parametric and Non-parametric Memory in Retrieval-augmented Language Models
Oct 07, 2024Generative language models often struggle with specialized or less-discussed knowledge. A potential solution is found in Retrieval-Augmented Generation (RAG) models which act like retrieving information before generating responses. In this study, we explore how the \textsc{Atlas} approach, a RAG model, decides between what it already knows (parametric) and what it retrieves (non-parametric). We use causal mediation analysis and controlled experiments to examine how internal representations influence information processing. Our findings disentangle the effects of parametric knowledge and the retrieved context. They indicate that in cases where the model can choose between both types of information (parametric and non-parametric), it relies more on the context than the parametric knowledge. Furthermore, the analysis investigates the computations involved in \emph{how} the model uses the information from the context. We find that multiple mechanisms are active within the model and can be detected with mediation analysis: first, the decision of \emph{whether the context is relevant}, and second, how the encoder computes output representations to support copying when relevant.
Can Large Language Models (or Humans) Distill Text?
Mar 25, 2024We investigate the potential of large language models (LLMs) to distill text: to remove the textual traces of an undesired forbidden variable. We employ a range of LLMs with varying architectures and training approaches to distill text by identifying and removing information about the target variable while preserving other relevant signals. Our findings shed light on the strengths and limitations of LLMs in addressing the distillation and provide insights into the strategies for leveraging these models in computational social science investigations involving text data. In particular, we show that in the strong test of removing sentiment, the statistical association between the processed text and sentiment is still clearly detectable to machine learning classifiers post-LLM-distillation. Furthermore, we find that human annotators also struggle to distill sentiment while preserving other semantic content. This suggests there may be limited separability between concept variables in some text contexts, highlighting limitations of methods relying on text-level transformations and also raising questions about the robustness of distillation methods that achieve statistical independence in representation space if this is difficult for human coders operating on raw text to attain.