 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudying the Role of Input-Neighbor Overlap in Retrieval-Augmented Language Models Training Efficiency
May 20, 2025Retrieval-augmented language models have demonstrated performance comparable to much larger models while requiring fewer computational resources. The effectiveness of these models crucially depends on the overlap between query and retrieved context, but the optimal degree of this overlap remains unexplored. In this paper, we systematically investigate how varying levels of query--context overlap affect model performance during both training and inference. Our experiments reveal that increased overlap initially has minimal effect, but substantially improves test-time perplexity and accelerates model learning above a critical threshold. Building on these findings, we demonstrate that deliberately increasing overlap through synthetic context can enhance data efficiency and reduce training time by approximately 40\% without compromising performance. We specifically generate synthetic context through paraphrasing queries. We validate our perplexity-based findings on question-answering tasks, confirming that the benefits of retrieval-augmented language modeling extend to practical applications. Our results provide empirical evidence of significant optimization potential for retrieval mechanisms in language model pretraining.
How Reliable Are Automatic Evaluation Methods for Instruction-Tuned LLMs?
Feb 16, 2024Work on instruction-tuned Large Language Models (LLMs) has used automatic methods based on text overlap and LLM judgments as cost-effective alternatives to human evaluation. In this paper, we study the reliability of such methods across a broad range of tasks and in a cross-lingual setting. In contrast to previous findings, we observe considerable variability in correlations between automatic methods and human evaluators when scores are differentiated by task type. Specifically, the widely-used ROUGE-L metric strongly correlates with human judgments for short-answer English tasks but is unreliable in free-form generation tasks and cross-lingual transfer. The effectiveness of GPT-4 as an evaluator depends on including reference answers when prompting for assessments, which can lead to overly strict evaluations in free-form generation tasks. In summary, we find that, while automatic evaluation methods can approximate human judgements under specific conditions, their reliability is highly context-dependent. Our findings enhance the understanding of how automatic methods should be applied and interpreted when developing and evaluating instruction-tuned LLMs.
Surface-Based Retrieval Reduces Perplexity of Retrieval-Augmented Language Models
May 25, 2023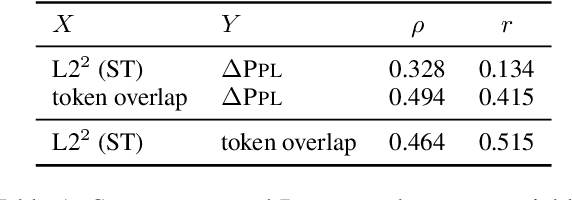

Augmenting language models with a retrieval mechanism has been shown to significantly improve their performance while keeping the number of parameters low. Retrieval-augmented models commonly rely on a semantic retrieval mechanism based on the similarity between dense representations of the query chunk and potential neighbors. In this paper, we study the state-of-the-art Retro model and observe that its performance gain is better explained by surface-level similarities, such as token overlap. Inspired by this, we replace the semantic retrieval in Retro with a surface-level method based on BM25, obtaining a significant reduction in perplexity. As full BM25 retrieval can be computationally costly for large datasets, we also apply it in a re-ranking scenario, gaining part of the perplexity reduction with minimal computational overhead.
On the Generalization Ability of Retrieval-Enhanced Transformers
Feb 23, 2023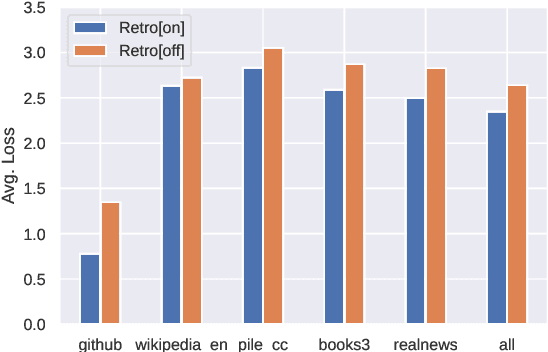
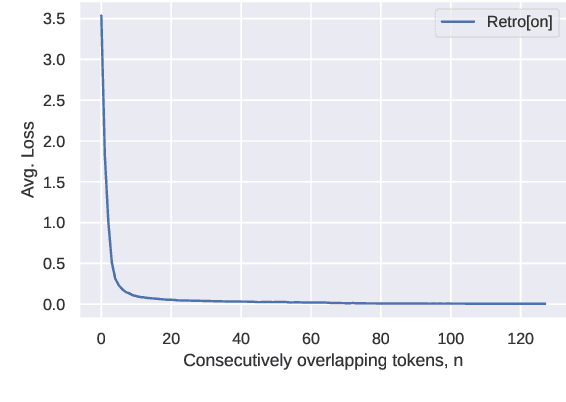
Recent work on the Retrieval-Enhanced Transformer (RETRO) model has shown that off-loading memory from trainable weights to a retrieval database can significantly improve language modeling and match the performance of non-retrieval models that are an order of magnitude larger in size. It has been suggested that at least some of this performance gain is due to non-trivial generalization based on both model weights and retrieval. In this paper, we try to better understand the relative contributions of these two components. We find that the performance gains from retrieval largely originate from overlapping tokens between the database and the test data, suggesting less non-trivial generalization than previously assumed. More generally, our results point to the challenges of evaluating the generalization of retrieval-augmented language models such as RETRO, as even limited token overlap may significantly decrease test-time loss. We release our code and model at https://github.com/TobiasNorlund/retro
SINA-BERT: A pre-trained Language Model for Analysis of Medical Texts in Persian
Apr 15, 2021
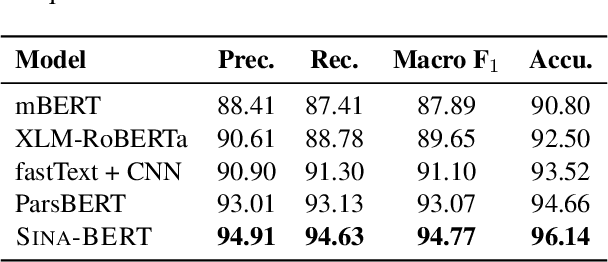
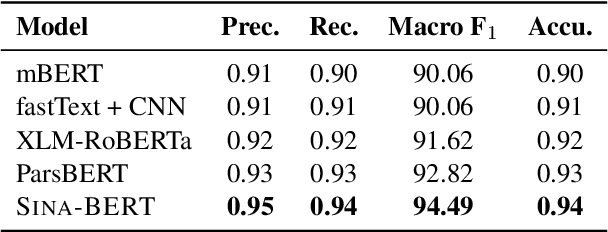
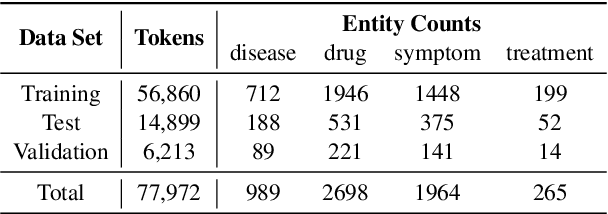
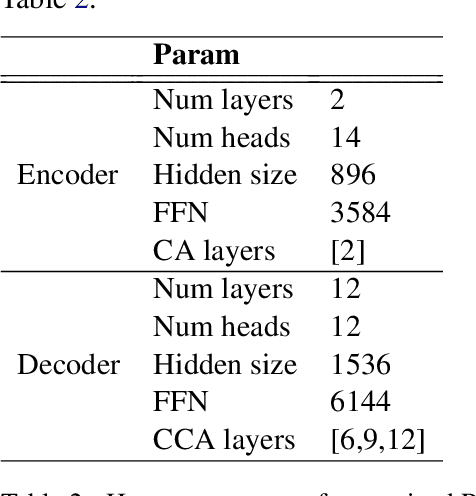
We have released Sina-BERT, a language model pre-trained on BERT (Devlin et al., 2018) to address the lack of a high-quality Persian language model in the medical domain. SINA-BERT utilizes pre-training on a large-scale corpus of medical contents including formal and informal texts collected from a variety of online resources in order to improve the performance on health-care related tasks. We employ SINA-BERT to complete following representative tasks: categorization of medical questions, medical sentiment analysis, and medical question retrieval. For each task, we have developed Persian annotated data sets for training and evaluation and learnt a representation for the data of each task especially complex and long medical questions. With the same architecture being used across tasks, SINA-BERT outperforms BERT-based models that were previously made available in the Persian language.
Joint Persian Word Segmentation Correction and Zero-Width Non-Joiner Recognition Using BERT
Oct 28, 2020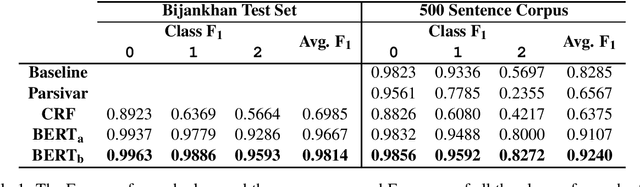
Words are properly segmented in the Persian writing system; in practice, however, these writing rules are often neglected, resulting in single words being written disjointedly and multiple words written without any white spaces between them. This paper addresses the problems of word segmentation and zero-width non-joiner (ZWNJ) recognition in Persian, which we approach jointly as a sequence labeling problem. We achieved a macro-averaged F1-score of 92.40% on a carefully collected corpus of 500 sentences with a high level of difficulty.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020
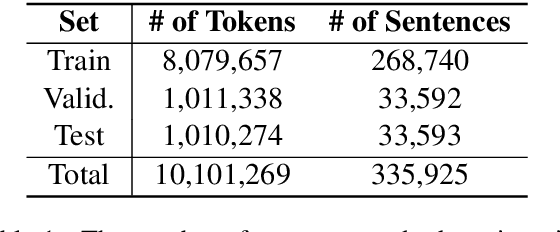
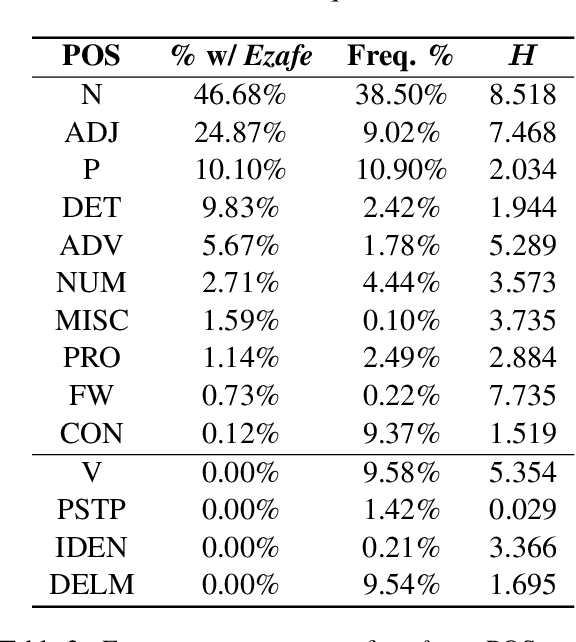
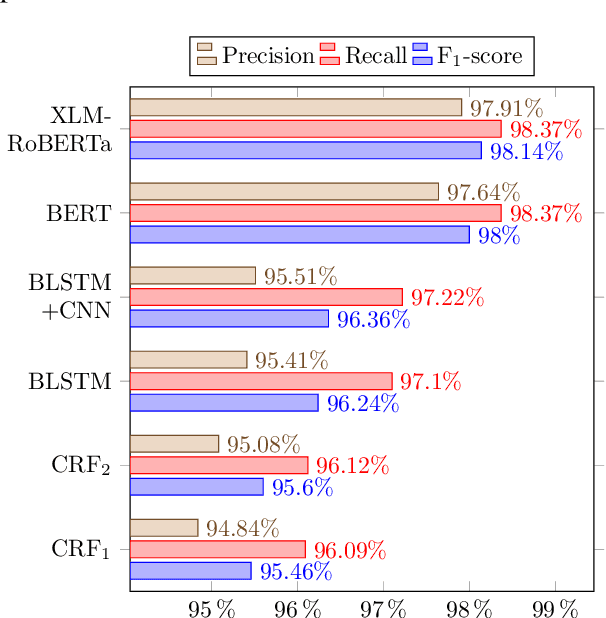
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.
Persian Keyphrase Generation Using Sequence-to-Sequence Models
Sep 25, 2020Keyphrases are a very short summary of an input text and provide the main subjects discussed in the text. Keyphrase extraction is a useful upstream task and can be used in various natural language processing problems, for example, text summarization and information retrieval, to name a few. However, not all the keyphrases are explicitly mentioned in the body of the text. In real-world examples there are always some topics that are discussed implicitly. Extracting such keyphrases requires a generative approach, which is adopted here. In this paper, we try to tackle the problem of keyphrase generation and extraction from news articles using deep sequence-to-sequence models. These models significantly outperform the conventional methods such as Topic Rank, KPMiner, and KEA in the task of keyphrase extraction.
PerKey: A Persian News Corpus for Keyphrase Extraction and Generation
Sep 25, 2020
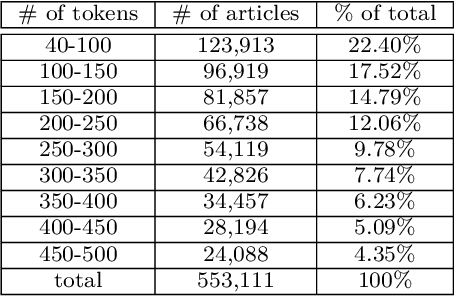
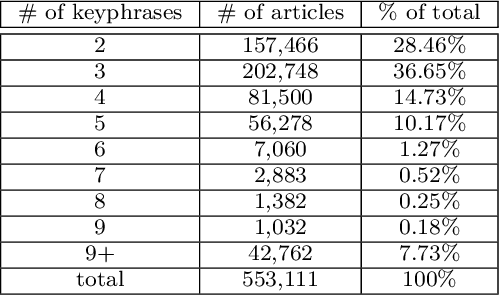
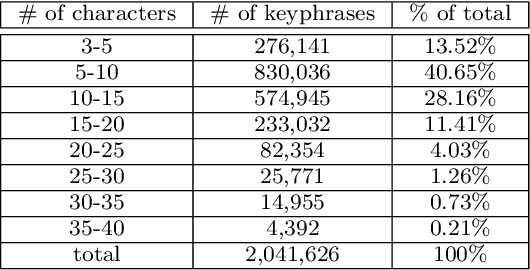
Keyphrases provide an extremely dense summary of a text. Such information can be used in many Natural Language Processing tasks, such as information retrieval and text summarization. Since previous studies on Persian keyword or keyphrase extraction have not published their data, the field suffers from the lack of a human extracted keyphrase dataset. In this paper, we introduce PerKey, a corpus of 553k news articles from six Persian news websites and agencies with relatively high quality author extracted keyphrases, which is then filtered and cleaned to achieve higher quality keyphrases. The resulted data was put into human assessment to ensure the quality of the keyphrases. We also measured the performance of different supervised and unsupervised techniques, e.g. TFIDF, MultipartiteRank, KEA, etc. on the dataset using precision, recall, and F1-score.
Investigating Machine Learning Methods for Language and Dialect Identification of Cuneiform Texts
Sep 22, 2020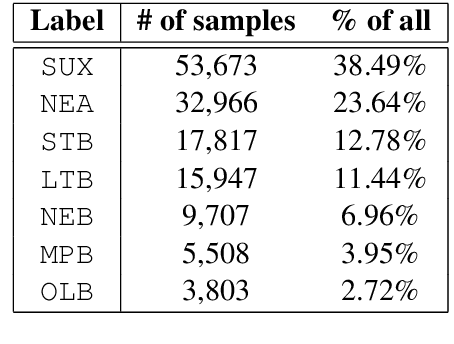
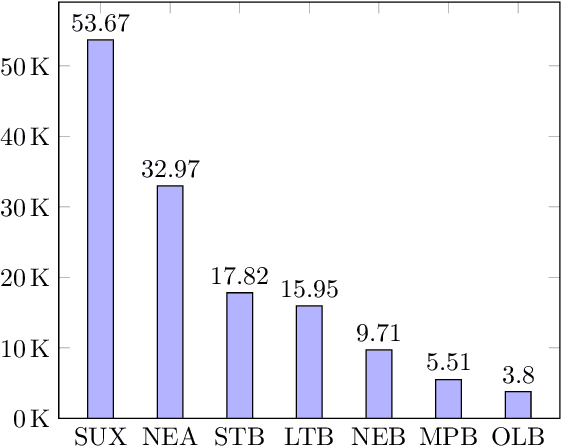
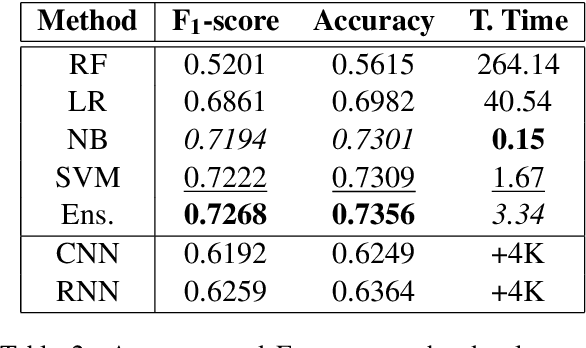
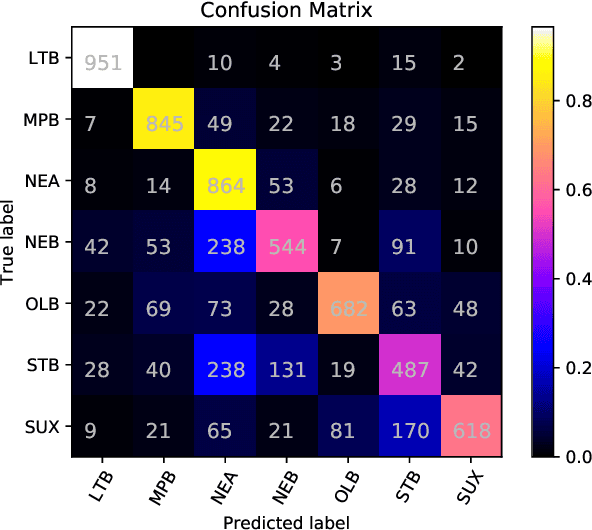
Identification of the languages written using cuneiform symbols is a difficult task due to the lack of resources and the problem of tokenization. The Cuneiform Language Identification task in VarDial 2019 addresses the problem of identifying seven languages and dialects written in cuneiform; Sumerian and six dialects of Akkadian language: Old Babylonian, Middle Babylonian Peripheral, Standard Babylonian, Neo-Babylonian, Late Babylonian, and Neo-Assyrian. This paper describes the approaches taken by SharifCL team to this problem in VarDial 2019. The best result belongs to an ensemble of Support Vector Machines and a naive Bayes classifier, both working on character-level features, with macro-averaged F1-score of 72.10%.