 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Paper and Code
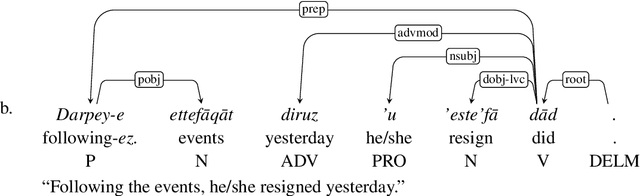
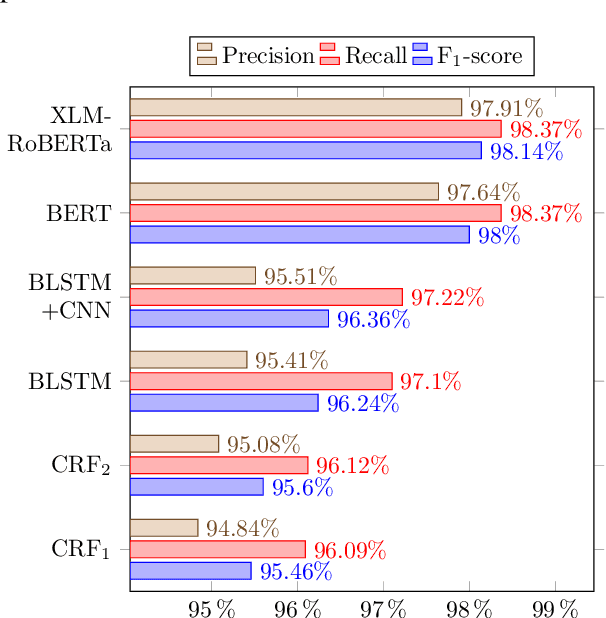
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.