 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Persian Word Segmentation Correction and Zero-Width Non-Joiner Recognition Using BERT
Oct 28, 2020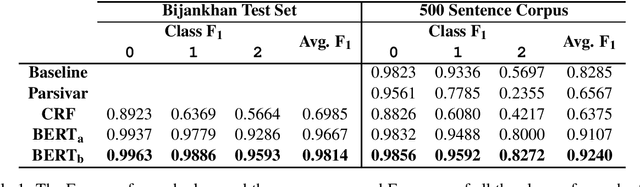
Words are properly segmented in the Persian writing system; in practice, however, these writing rules are often neglected, resulting in single words being written disjointedly and multiple words written without any white spaces between them. This paper addresses the problems of word segmentation and zero-width non-joiner (ZWNJ) recognition in Persian, which we approach jointly as a sequence labeling problem. We achieved a macro-averaged F1-score of 92.40% on a carefully collected corpus of 500 sentences with a high level of difficulty.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020
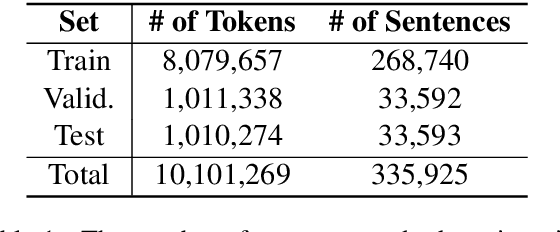
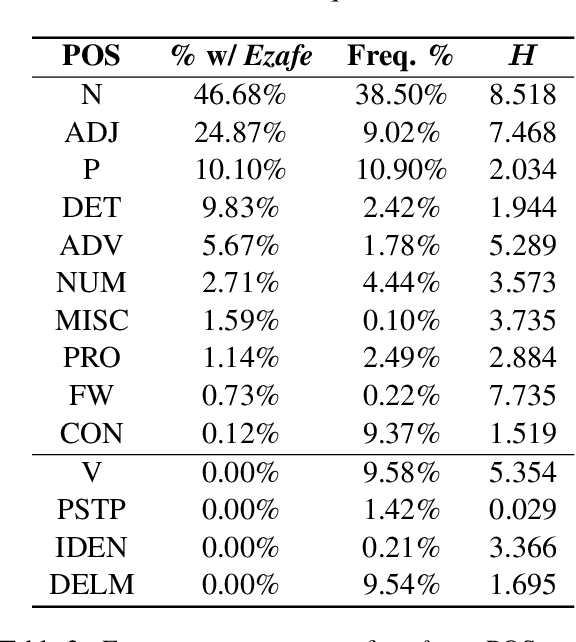
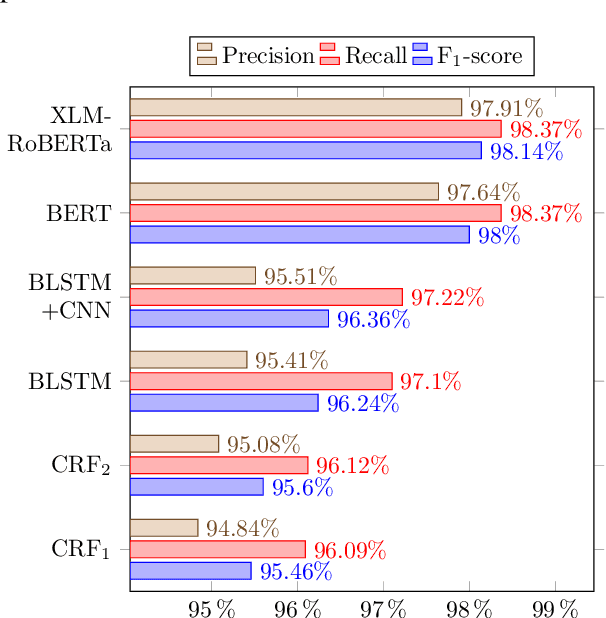
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.
Investigating Machine Learning Methods for Language and Dialect Identification of Cuneiform Texts
Sep 22, 2020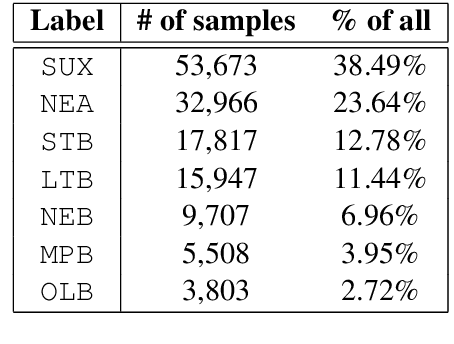
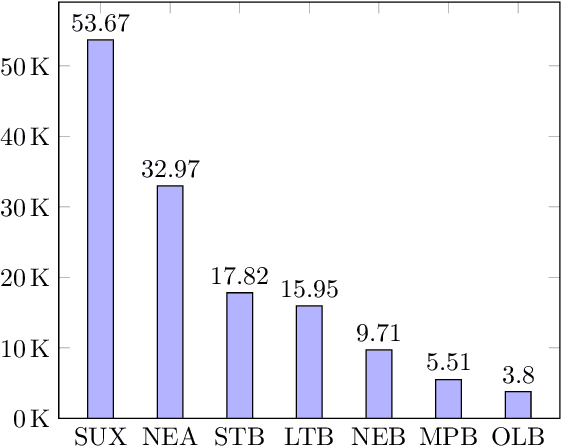
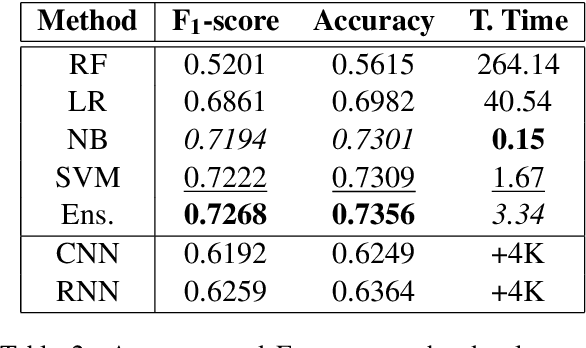
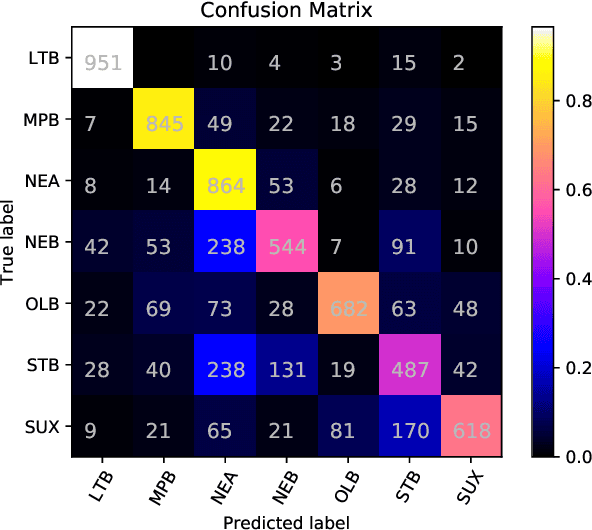
Identification of the languages written using cuneiform symbols is a difficult task due to the lack of resources and the problem of tokenization. The Cuneiform Language Identification task in VarDial 2019 addresses the problem of identifying seven languages and dialects written in cuneiform; Sumerian and six dialects of Akkadian language: Old Babylonian, Middle Babylonian Peripheral, Standard Babylonian, Neo-Babylonian, Late Babylonian, and Neo-Assyrian. This paper describes the approaches taken by SharifCL team to this problem in VarDial 2019. The best result belongs to an ensemble of Support Vector Machines and a naive Bayes classifier, both working on character-level features, with macro-averaged F1-score of 72.10%.