 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting the effectiveness of saliency-based explainability in NLP using randomized survey-based experiments
Nov 25, 2022
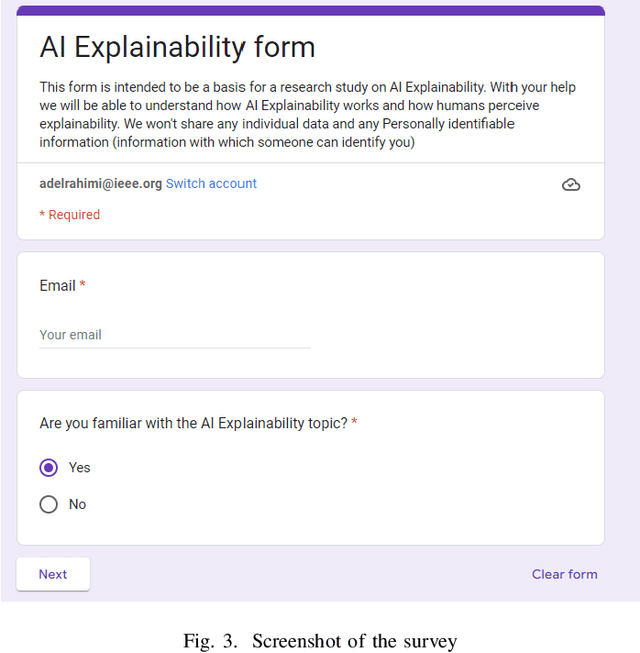


As the applications of Natural Language Processing (NLP) in sensitive areas like Political Profiling, Review of Essays in Education, etc. proliferate, there is a great need for increasing transparency in NLP models to build trust with stakeholders and identify biases. A lot of work in Explainable AI has aimed to devise explanation methods that give humans insights into the workings and predictions of NLP models. While these methods distill predictions from complex models like Neural Networks into consumable explanations, how humans understand these explanations is still widely unexplored. Innate human tendencies and biases can handicap the understanding of these explanations in humans, and can also lead to them misjudging models and predictions as a result. We designed a randomized survey-based experiment to understand the effectiveness of saliency-based Post-hoc explainability methods in Natural Language Processing. The result of the experiment showed that humans have a tendency to accept explanations with a less critical view.
Joint Persian Word Segmentation Correction and Zero-Width Non-Joiner Recognition Using BERT
Oct 28, 2020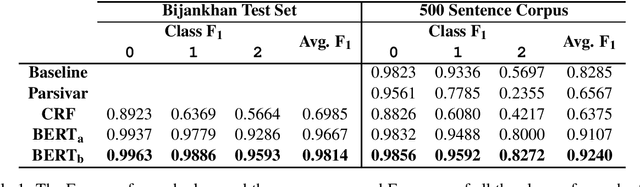
Words are properly segmented in the Persian writing system; in practice, however, these writing rules are often neglected, resulting in single words being written disjointedly and multiple words written without any white spaces between them. This paper addresses the problems of word segmentation and zero-width non-joiner (ZWNJ) recognition in Persian, which we approach jointly as a sequence labeling problem. We achieved a macro-averaged F1-score of 92.40% on a carefully collected corpus of 500 sentences with a high level of difficulty.
The Need for Standardized Explainability
Oct 23, 2020



Explainable AI (XAI) is paramount in industry-grade AI; however existing methods fail to address this necessity, in part due to a lack of standardisation of explainability methods. The purpose of this paper is to offer a perspective on the current state of the area of explainability, and to provide novel definitions for Explainability and Interpretability to begin standardising this area of research. To do so, we provide an overview of the literature on explainability, and of the existing methods that are already implemented. Finally, we offer a tentative taxonomy of the different explainability methods, opening the door to future research.
Persian Ezafe Recognition Using Transformers and Its Role in Part-Of-Speech Tagging
Oct 04, 2020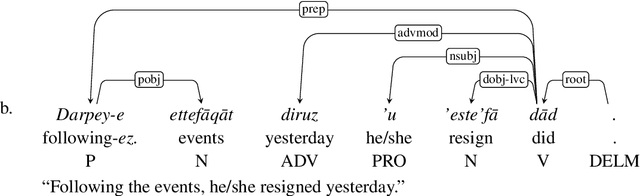
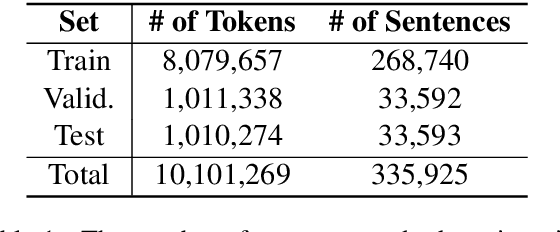
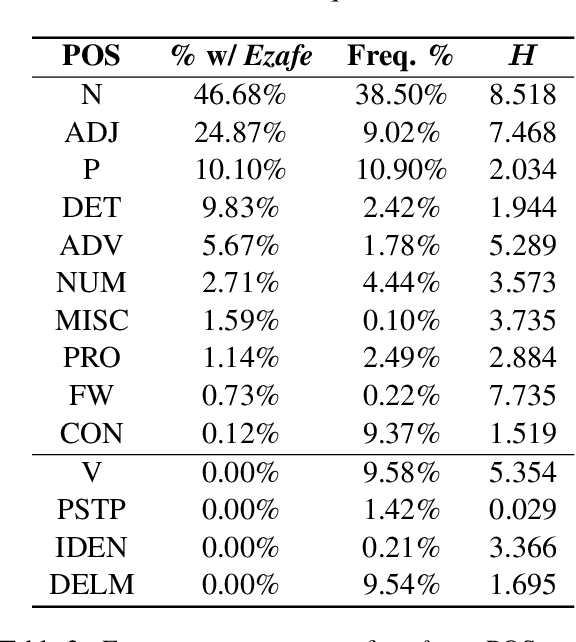
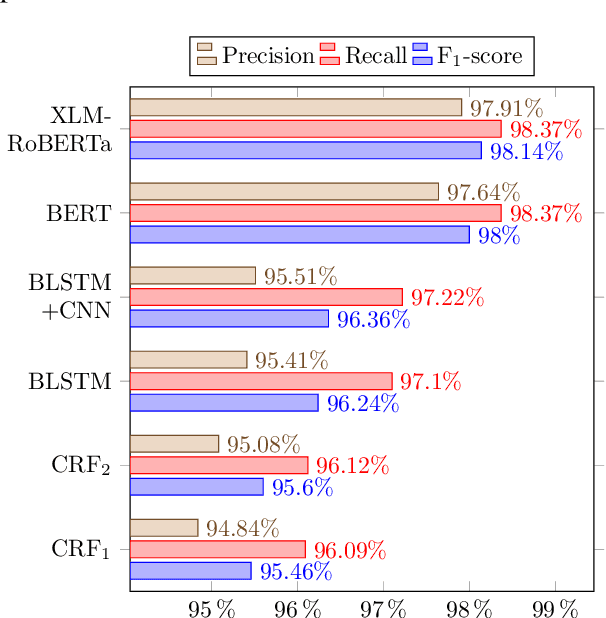
Ezafe is a grammatical particle in some Iranian languages that links two words together. Regardless of the important information it conveys, it is almost always not indicated in Persian script, resulting in mistakes in reading complex sentences and errors in natural language processing tasks. In this paper, we experiment with different machine learning methods to achieve state-of-the-art results in the task of ezafe recognition. Transformer-based methods, BERT and XLMRoBERTa, achieve the best results, the latter achieving 2.68% F1-score more than the previous state-of-the-art. We, moreover, use ezafe information to improve Persian part-of-speech tagging results and show that such information will not be useful to transformer-based methods and explain why that might be the case.
Improving Information Retrieval Results for Persian Documents using FarsNet
Nov 01, 2018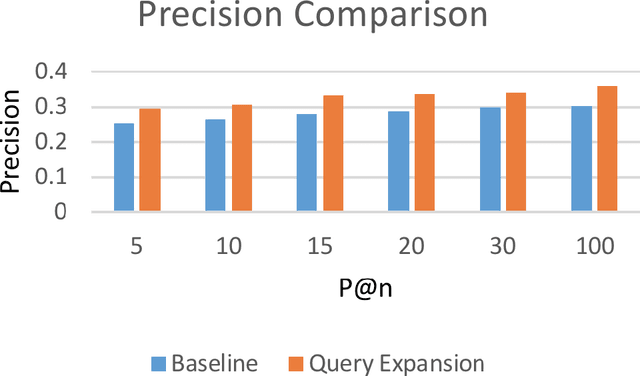
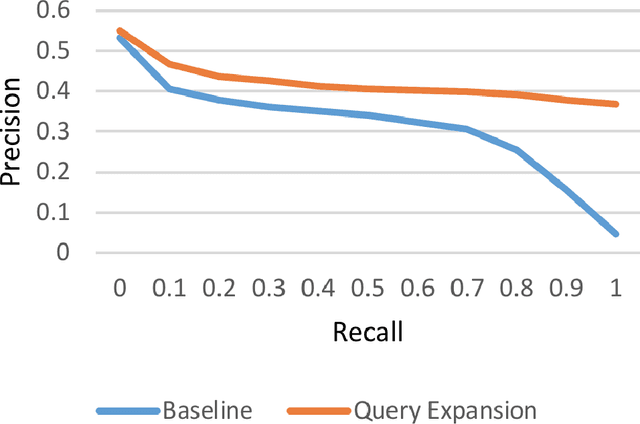
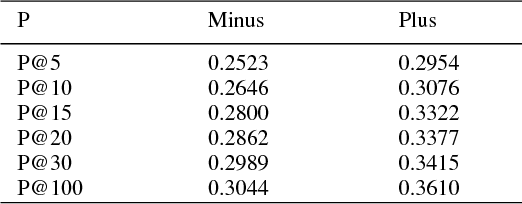
In this paper, we propose a new method for query expansion, which uses FarsNet (Persian WordNet) to find similar tokens related to the query and expand the semantic meaning of the query. For this purpose, we use synonymy relations in FarsNet and extract the related synonyms to query words. This algorithm is used to enhance information retrieval systems and improve search results. The overall evaluation of this system in comparison to the baseline method (without using query expansion) shows an improvement of about 9 percent in Mean Average Precision (MAP).
A rule based algorithm for detecting negative words in Persian
Aug 19, 2017In this paper, we present a novel method for detecting negative words in Persian. We first used an algorithm to an exceptions list which was later modified by hand. We then used the mentioned lists and a Persian polarity corpus in our rule based algorithm to detect negative words.
Lexical bundles in computational linguistics academic literature
Mar 10, 2016

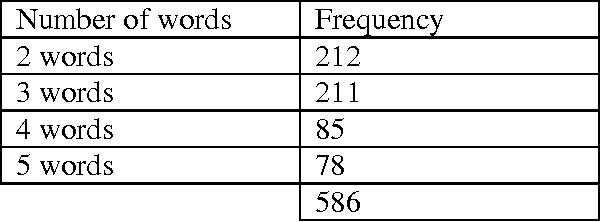

In this study we analyzed a corpus of 8 million words academic literature from Computational lingustics' academic literature. the lexical bundles from this corpus are categorized based on structures and functions.
A new hybrid stemming algorithm for Persian
Nov 24, 2015


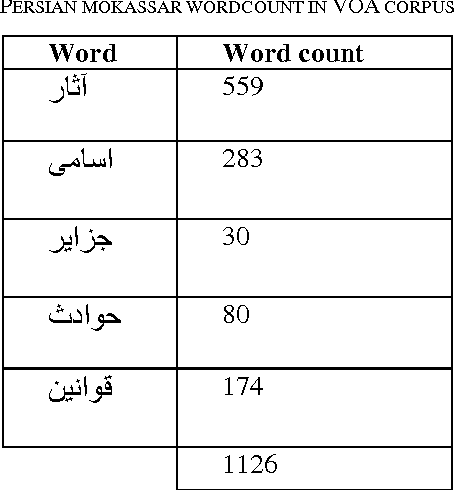
Stemming has been an influential part in Information retrieval and search engines. There have been tremendous endeavours in making stemmer that are both efficient and accurate. Stemmers can have three method in stemming, Dictionary based stemmer, statistical-based stemmers, and rule-based stemmers. This paper aims at building a hybrid stemmer that uses both Dictionary based method and rule-based method for stemming. This ultimately helps the efficacy and accurateness of the stemmer.