Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Machine Learning Methods for Language and Dialect Identification of Cuneiform Texts
Paper and Code
Sep 22, 2020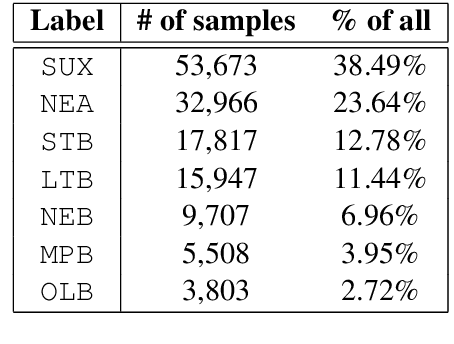
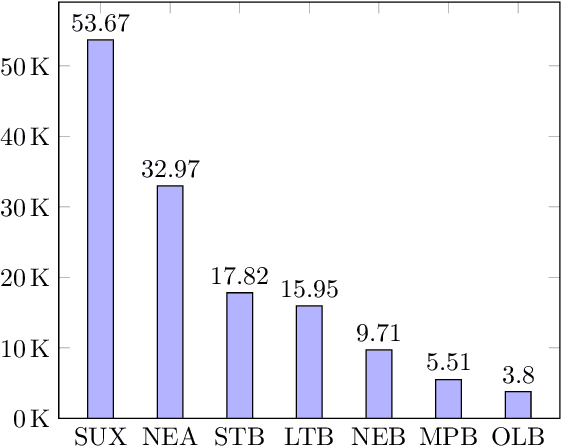
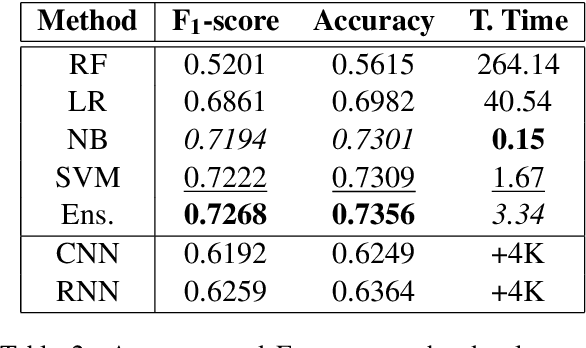
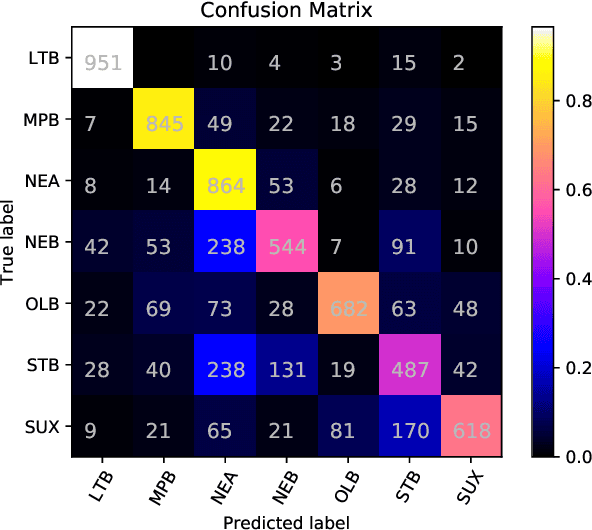
Identification of the languages written using cuneiform symbols is a difficult task due to the lack of resources and the problem of tokenization. The Cuneiform Language Identification task in VarDial 2019 addresses the problem of identifying seven languages and dialects written in cuneiform; Sumerian and six dialects of Akkadian language: Old Babylonian, Middle Babylonian Peripheral, Standard Babylonian, Neo-Babylonian, Late Babylonian, and Neo-Assyrian. This paper describes the approaches taken by SharifCL team to this problem in VarDial 2019. The best result belongs to an ensemble of Support Vector Machines and a naive Bayes classifier, both working on character-level features, with macro-averaged F1-score of 72.10%.
View paper on