 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow Up and Merge: Scaling Strategies for Efficient Language Adaptation
Dec 11, 2025Achieving high-performing language models which include medium- and lower-resource languages remains a challenge. Massively multilingual models still underperform compared to language-specific adaptations, especially at smaller model scales. In this work, we investigate scaling as an efficient strategy for adapting pretrained models to new target languages. Through comprehensive scaling ablations with approximately FLOP-matched models, we test whether upscaling an English base model enables more effective and resource-efficient adaptation than standard continued pretraining. We find that, once exposed to sufficient target-language data, larger upscaled models can match or surpass the performance of smaller models continually pretrained on much more data, demonstrating the benefits of scaling for data efficiency. Scaling also helps preserve the base model's capabilities in English, thus reducing catastrophic forgetting. Finally, we explore whether such scaled, language-specific models can be merged to construct modular and flexible multilingual systems. We find that while merging remains less effective than joint multilingual training, upscaled merges perform better than smaller ones. We observe large performance differences across merging methods, suggesting potential for improvement through merging approaches specialized for language-level integration.
Studying the Role of Input-Neighbor Overlap in Retrieval-Augmented Language Models Training Efficiency
May 20, 2025Retrieval-augmented language models have demonstrated performance comparable to much larger models while requiring fewer computational resources. The effectiveness of these models crucially depends on the overlap between query and retrieved context, but the optimal degree of this overlap remains unexplored. In this paper, we systematically investigate how varying levels of query--context overlap affect model performance during both training and inference. Our experiments reveal that increased overlap initially has minimal effect, but substantially improves test-time perplexity and accelerates model learning above a critical threshold. Building on these findings, we demonstrate that deliberately increasing overlap through synthetic context can enhance data efficiency and reduce training time by approximately 40\% without compromising performance. We specifically generate synthetic context through paraphrasing queries. We validate our perplexity-based findings on question-answering tasks, confirming that the benefits of retrieval-augmented language modeling extend to practical applications. Our results provide empirical evidence of significant optimization potential for retrieval mechanisms in language model pretraining.
Fact Recall, Heuristics or Pure Guesswork? Precise Interpretations of Language Models for Fact Completion
Oct 18, 2024Previous interpretations of language models (LMs) miss important distinctions in how these models process factual information. For example, given the query "Astrid Lindgren was born in" with the corresponding completion "Sweden", no difference is made between whether the prediction was based on having the exact knowledge of the birthplace of the Swedish author or assuming that a person with a Swedish-sounding name was born in Sweden. In this paper, we investigate four different prediction scenarios for which the LM can be expected to show distinct behaviors. These scenarios correspond to different levels of model reliability and types of information being processed - some being less desirable for factual predictions. To facilitate precise interpretations of LMs for fact completion, we propose a model-specific recipe called PrISM for constructing datasets with examples of each scenario based on a set of diagnostic criteria. We apply a popular interpretability method, causal tracing (CT), to the four prediction scenarios and find that while CT produces different results for each scenario, aggregations over a set of mixed examples may only represent the results from the scenario with the strongest measured signal. In summary, we contribute tools for a more granular study of fact completion in language models and analyses that provide a more nuanced understanding of how LMs process fact-related queries.
NL2Plan: Robust LLM-Driven Planning from Minimal Text Descriptions
May 07, 2024Today's classical planners are powerful, but modeling input tasks in formats such as PDDL is tedious and error-prone. In contrast, planning with Large Language Models (LLMs) allows for almost any input text, but offers no guarantees on plan quality or even soundness. In an attempt to merge the best of these two approaches, some work has begun to use LLMs to automate parts of the PDDL creation process. However, these methods still require various degrees of expert input. We present NL2Plan, the first domain-agnostic offline LLM-driven planning system. NL2Plan uses an LLM to incrementally extract the necessary information from a short text prompt before creating a complete PDDL description of both the domain and the problem, which is finally solved by a classical planner. We evaluate NL2Plan on four planning domains and find that it solves 10 out of 15 tasks - a clear improvement over a plain chain-of-thought reasoning LLM approach, which only solves 2 tasks. Moreover, in two out of the five failure cases, instead of returning an invalid plan, NL2Plan reports that it failed to solve the task. In addition to using NL2Plan in end-to-end mode, users can inspect and correct all of its intermediate results, such as the PDDL representation, increasing explainability and making it an assistive tool for PDDL creation.
Properties and Challenges of LLM-Generated Explanations
Feb 16, 2024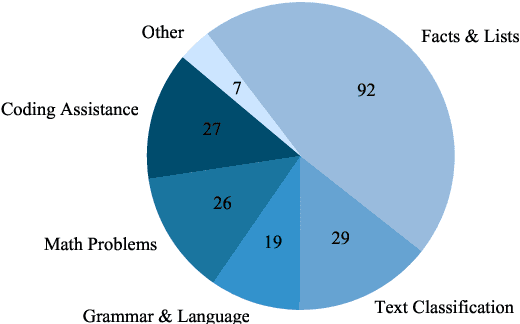
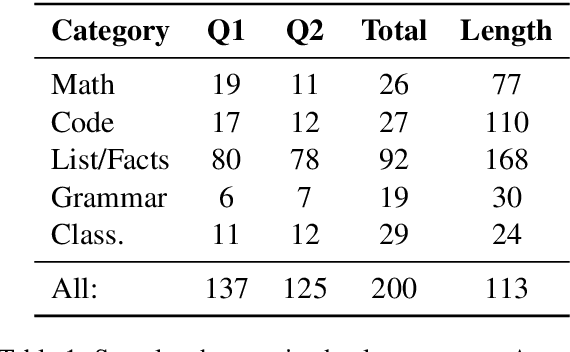
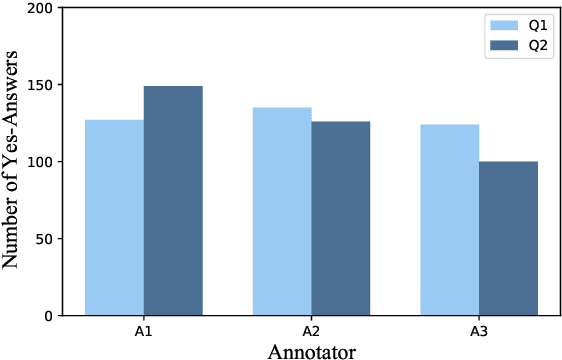
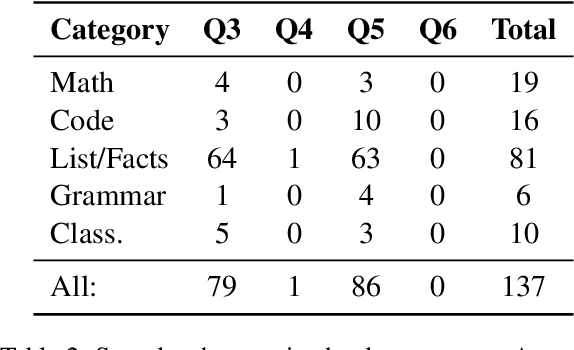
The self-rationalising capabilities of large language models (LLMs) have been explored in restricted settings, using task/specific data sets. However, current LLMs do not (only) rely on specifically annotated data; nonetheless, they frequently explain their outputs. The properties of the generated explanations are influenced by the pre-training corpus and by the target data used for instruction fine-tuning. As the pre-training corpus includes a large amount of human-written explanations "in the wild", we hypothesise that LLMs adopt common properties of human explanations. By analysing the outputs for a multi-domain instruction fine-tuning data set, we find that generated explanations show selectivity and contain illustrative elements, but less frequently are subjective or misleading. We discuss reasons and consequences of the properties' presence or absence. In particular, we outline positive and negative implications depending on the goals and user groups of the self-rationalising system.
How Reliable Are Automatic Evaluation Methods for Instruction-Tuned LLMs?
Feb 16, 2024Work on instruction-tuned Large Language Models (LLMs) has used automatic methods based on text overlap and LLM judgments as cost-effective alternatives to human evaluation. In this paper, we study the reliability of such methods across a broad range of tasks and in a cross-lingual setting. In contrast to previous findings, we observe considerable variability in correlations between automatic methods and human evaluators when scores are differentiated by task type. Specifically, the widely-used ROUGE-L metric strongly correlates with human judgments for short-answer English tasks but is unreliable in free-form generation tasks and cross-lingual transfer. The effectiveness of GPT-4 as an evaluator depends on including reference answers when prompting for assessments, which can lead to overly strict evaluations in free-form generation tasks. In summary, we find that, while automatic evaluation methods can approximate human judgements under specific conditions, their reliability is highly context-dependent. Our findings enhance the understanding of how automatic methods should be applied and interpreted when developing and evaluating instruction-tuned LLMs.
Align, Distill, and Augment Everything All at Once for Imbalanced Semi-Supervised Learning
Jun 07, 2023



Addressing the class imbalance in long-tailed semi-supervised learning (SSL) poses a few significant challenges stemming from differences between the marginal distributions of unlabeled data and the labeled data, as the former is often unknown and potentially distinct from the latter. The first challenge is to avoid biasing the pseudo-labels towards an incorrect distribution, such as that of the labeled data or a balanced distribution, during training. However, we still wish to ensure a balanced unlabeled distribution during inference, which is the second challenge. To address both of these challenges, we propose a three-faceted solution: a flexible distribution alignment that progressively aligns the classifier from a dynamically estimated unlabeled prior towards a balanced distribution, a soft consistency regularization that exploits underconfident pseudo-labels discarded by threshold-based methods, and a schema for expanding the unlabeled set with input data from the labeled partition. This last facet comes in as a response to the commonly-overlooked fact that disjoint partitions of labeled and unlabeled data prevent the benefits of strong data augmentation on the labeled set. Our overall framework requires no additional training cycles, so it will align, distill, and augment everything all at once (ADALLO). Our extensive evaluations of ADALLO on imbalanced SSL benchmark datasets, including CIFAR10-LT, CIFAR100-LT, and STL10-LT with varying degrees of class imbalance, amount of labeled data, and distribution mismatch, demonstrate significant improvements in the performance of imbalanced SSL under large distribution mismatch, as well as competitiveness with state-of-the-art methods when the labeled and unlabeled data follow the same marginal distribution. Our code will be released upon paper acceptance.
Surface-Based Retrieval Reduces Perplexity of Retrieval-Augmented Language Models
May 25, 2023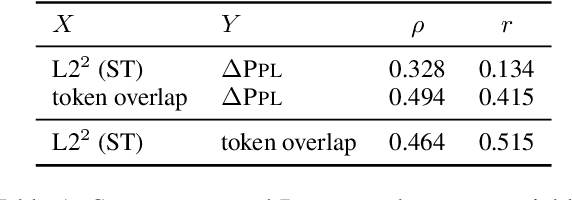

Augmenting language models with a retrieval mechanism has been shown to significantly improve their performance while keeping the number of parameters low. Retrieval-augmented models commonly rely on a semantic retrieval mechanism based on the similarity between dense representations of the query chunk and potential neighbors. In this paper, we study the state-of-the-art Retro model and observe that its performance gain is better explained by surface-level similarities, such as token overlap. Inspired by this, we replace the semantic retrieval in Retro with a surface-level method based on BM25, obtaining a significant reduction in perplexity. As full BM25 retrieval can be computationally costly for large datasets, we also apply it in a re-ranking scenario, gaining part of the perplexity reduction with minimal computational overhead.
On the Generalization Ability of Retrieval-Enhanced Transformers
Feb 23, 2023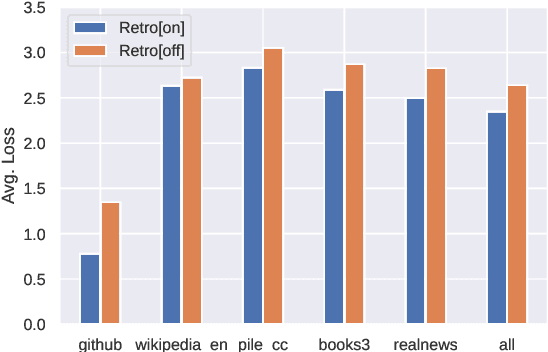
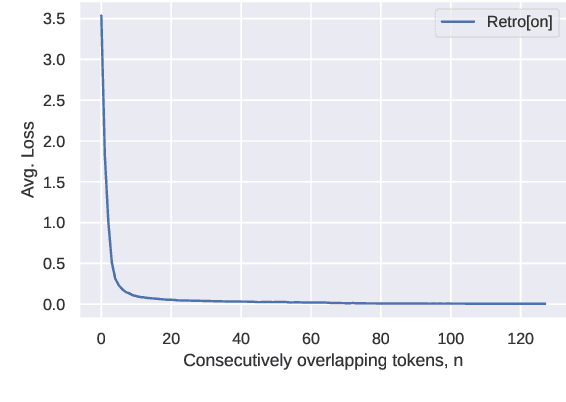
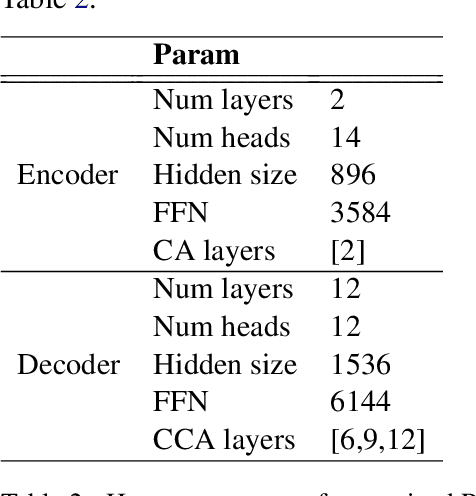
Recent work on the Retrieval-Enhanced Transformer (RETRO) model has shown that off-loading memory from trainable weights to a retrieval database can significantly improve language modeling and match the performance of non-retrieval models that are an order of magnitude larger in size. It has been suggested that at least some of this performance gain is due to non-trivial generalization based on both model weights and retrieval. In this paper, we try to better understand the relative contributions of these two components. We find that the performance gains from retrieval largely originate from overlapping tokens between the database and the test data, suggesting less non-trivial generalization than previously assumed. More generally, our results point to the challenges of evaluating the generalization of retrieval-augmented language models such as RETRO, as even limited token overlap may significantly decrease test-time loss. We release our code and model at https://github.com/TobiasNorlund/retro
Balanced Product of Experts for Long-Tailed Recognition
Jun 10, 2022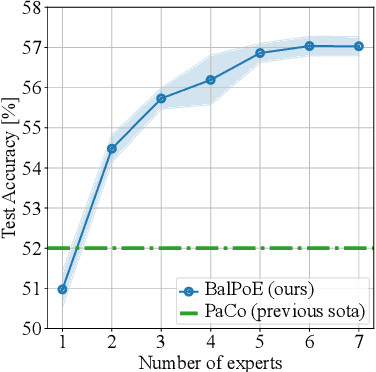
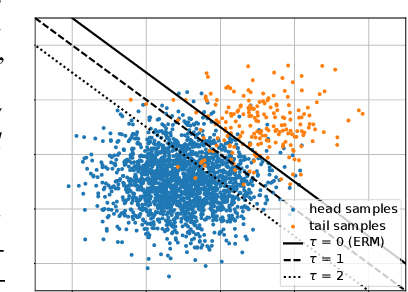
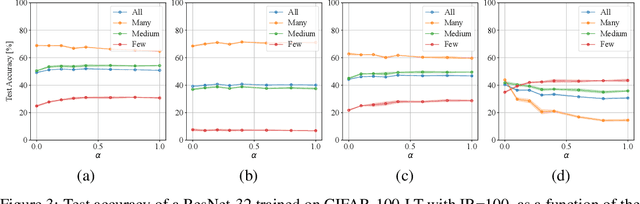
Many real-world recognition problems suffer from an imbalanced or long-tailed label distribution. Those distributions make representation learning more challenging due to limited generalization over the tail classes. If the test distribution differs from the training distribution, e.g. uniform versus long-tailed, the problem of the distribution shift needs to be addressed. To this aim, recent works have extended softmax cross-entropy using margin modifications, inspired by Bayes' theorem. In this paper, we generalize several approaches with a Balanced Product of Experts (BalPoE), which combines a family of models with different test-time target distributions to tackle the imbalance in the data. The proposed experts are trained in a single stage, either jointly or independently, and fused seamlessly into a BalPoE. We show that BalPoE is Fisher consistent for minimizing the balanced error and perform extensive experiments to validate the effectiveness of our approach. Finally, we investigate the effect of Mixup in this setting, discovering that regularization is a key ingredient for learning calibrated experts. Our experiments show that a regularized BalPoE can perform remarkably well in test accuracy and calibration metrics, leading to state-of-the-art results on CIFAR-100-LT, ImageNet-LT, and iNaturalist-2018 datasets. The code will be made publicly available upon paper acceptance.