 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-symbolic Syntactic Parsing: Shaping a Neural Network with the CYK Algorithm
May 29, 2026In this paper, we show the possibility of a direct injection of algorithms into neural network architecture. We focus on a complex algorithm, that is, Cocke-Youger-Kasami (CYK) for parsing context-free grammars in Chomsky Normal Form and we propose CYKNN, a simple recurrent neural network architecture for encoding the CYK algorithm in trainable matrix-vector multiplications.We experimented with a very simple grammar with 4 variations showing that our approach outperforms existing LLMs with more than 20B parameters with an in-context learning setting and smaller LLMs of the Qwen family fine-tuned with LoRA. Our attempt paves the way to a different approach to neuro-symbolic methodologies.
Detecting Winning Arguments with Large Language Models and Persuasion Strategies
Jan 15, 2026Detecting persuasion in argumentative text is a challenging task with important implications for understanding human communication. This work investigates the role of persuasion strategies - such as Attack on reputation, Distraction, and Manipulative wording - in determining the persuasiveness of a text. We conduct experiments on three annotated argument datasets: Winning Arguments (built from the Change My View subreddit), Anthropic/Persuasion, and Persuasion for Good. Our approach leverages large language models (LLMs) with a Multi-Strategy Persuasion Scoring approach that guides reasoning over six persuasion strategies. Results show that strategy-guided reasoning improves the prediction of persuasiveness. To better understand the influence of content, we organize the Winning Argument dataset into broad discussion topics and analyze performance across them. We publicly release this topic-annotated version of the dataset to facilitate future research. Overall, our methodology demonstrates the value of structured, strategy-aware prompting for enhancing interpretability and robustness in argument quality assessment.
On the Complexity of CCG Parsing
May 04, 2018We study the parsing complexity of Combinatory Categorial Grammar (CCG) in the formalism of Vijay-Shanker and Weir (1994). As our main result, we prove that any parsing algorithm for this formalism will take in the worst case exponential time when the size of the grammar, and not only the length of the input sentence, is included in the analysis. This sets the formalism of Vijay-Shanker and Weir (1994) apart from weakly equivalent formalisms such as Tree-Adjoining Grammar (TAG), for which parsing can be performed in time polynomial in the combined size of grammar and input sentence. Our results contribute to a refined understanding of the class of mildly context-sensitive grammars, and inform the search for new, mildly context-sensitive versions of CCG.
An Incremental Parser for Abstract Meaning Representation
Apr 10, 2017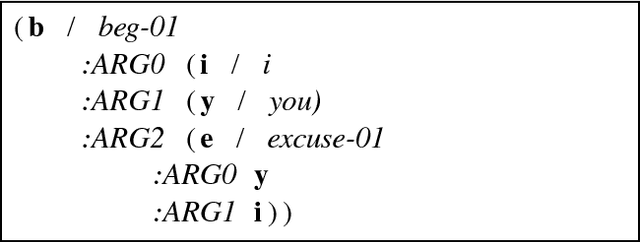


Meaning Representation (AMR) is a semantic representation for natural language that embeds annotations related to traditional tasks such as named entity recognition, semantic role labeling, word sense disambiguation and co-reference resolution. We describe a transition-based parser for AMR that parses sentences left-to-right, in linear time. We further propose a test-suite that assesses specific subtasks that are helpful in comparing AMR parsers, and show that our parser is competitive with the state of the art on the LDC2015E86 dataset and that it outperforms state-of-the-art parsers for recovering named entities and handling polarity.
Synchronous Context-Free Grammars and Optimal Linear Parsing Strategies
Nov 25, 2013



Synchronous Context-Free Grammars (SCFGs), also known as syntax-directed translation schemata, are unlike context-free grammars in that they do not have a binary normal form. In general, parsing with SCFGs takes space and time polynomial in the length of the input strings, but with the degree of the polynomial depending on the permutations of the SCFG rules. We consider linear parsing strategies, which add one nonterminal at a time. We show that for a given input permutation, the problems of finding the linear parsing strategy with the minimum space and time complexity are both NP-hard.
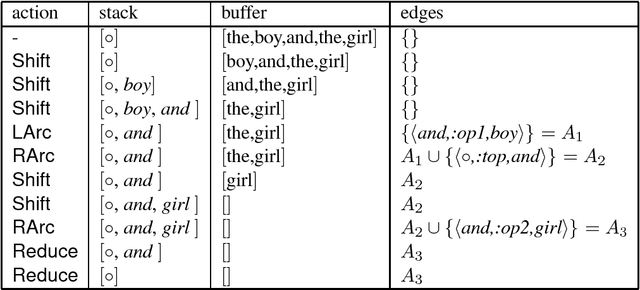
Elimination of Spurious Ambiguity in Transition-Based Dependency Parsing
Jun 28, 2012
We present a novel technique to remove spurious ambiguity from transition systems for dependency parsing. Our technique chooses a canonical sequence of transition operations (computation) for a given dependency tree. Our technique can be applied to a large class of bottom-up transition systems, including for instance Nivre (2004) and Attardi (2006).
Tabular Parsing
Apr 05, 2004
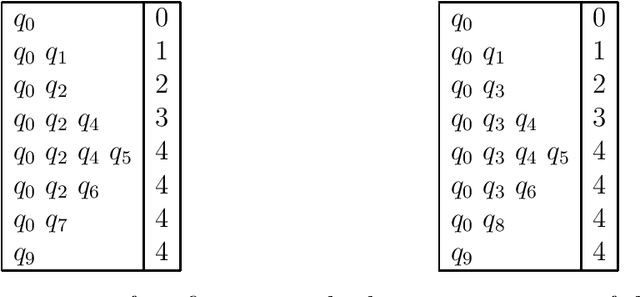
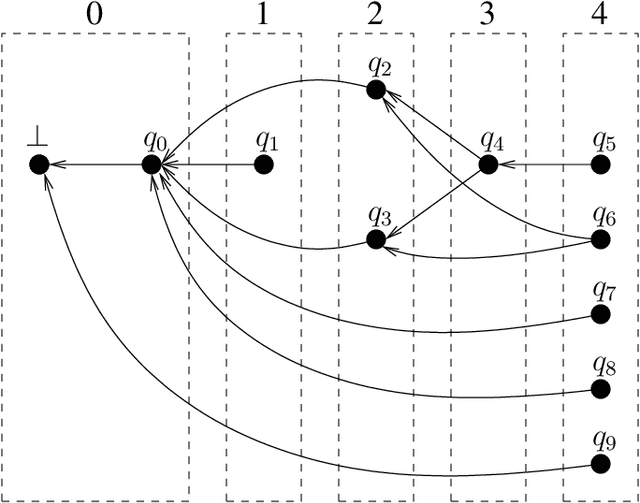
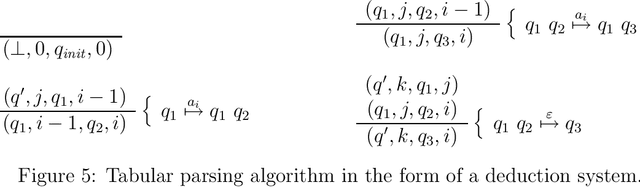
This is a tutorial on tabular parsing, on the basis of tabulation of nondeterministic push-down automata. Discussed are Earley's algorithm, the Cocke-Kasami-Younger algorithm, tabular LR parsing, the construction of parse trees, and further issues.
* 21 pages, 14 figures
Probabilistic Parsing Strategies
Nov 14, 2002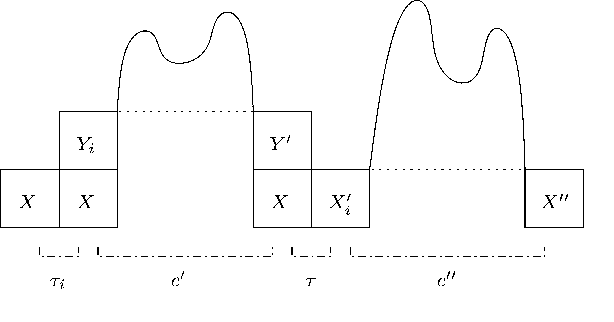


We present new results on the relation between purely symbolic context-free parsing strategies and their probabilistic counter-parts. Such parsing strategies are seen as constructions of push-down devices from grammars. We show that preservation of probability distribution is possible under two conditions, viz. the correct-prefix property and the property of strong predictiveness. These results generalize existing results in the literature that were obtained by considering parsing strategies in isolation. From our general results we also derive negative results on so-called generalized LR parsing.
Restrictions on Tree Adjoining Languages
Oct 13, 1998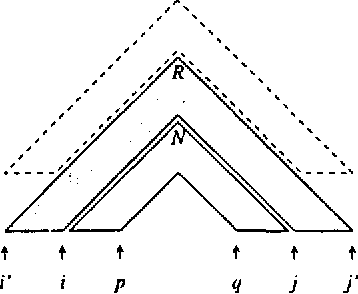
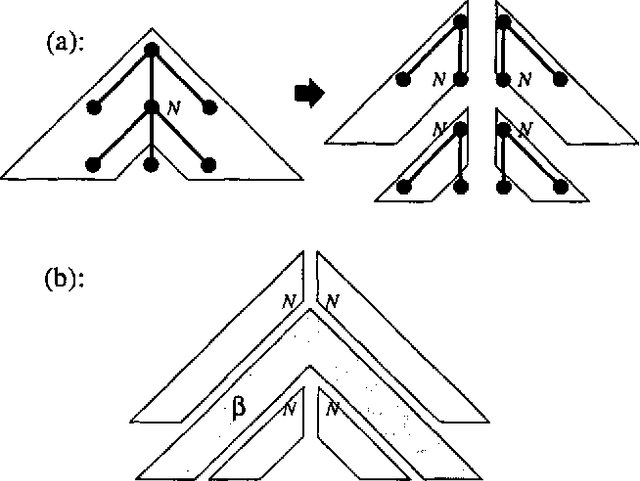
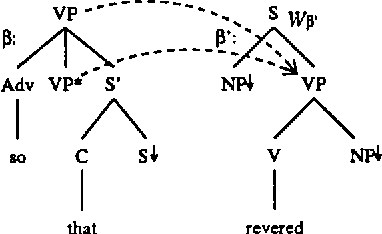

Several methods are known for parsing languages generated by Tree Adjoining Grammars (TAGs) in O(n^6) worst case running time. In this paper we investigate which restrictions on TAGs and TAG derivations are needed in order to lower this O(n^6) time complexity, without introducing large runtime constants, and without losing any of the generative power needed to capture the syntactic constructions in natural language that can be handled by unrestricted TAGs. In particular, we describe an algorithm for parsing a strict subclass of TAG in O(n^5), and attempt to show that this subclass retains enough generative power to make it useful in the general case.
* 7 pages LaTeX + 5 eps figures
Prefix Probabilities from Stochastic Tree Adjoining Grammars
Sep 18, 1998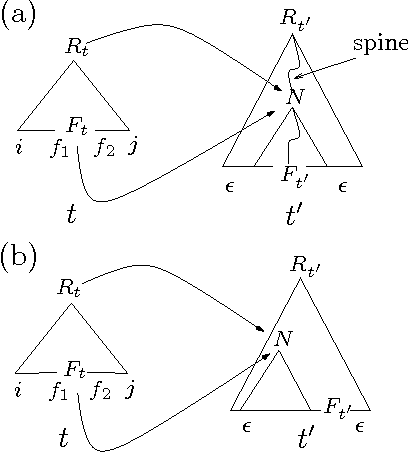

Language models for speech recognition typically use a probability model of the form Pr(a_n | a_1, a_2, ..., a_{n-1}). Stochastic grammars, on the other hand, are typically used to assign structure to utterances. A language model of the above form is constructed from such grammars by computing the prefix probability Sum_{w in Sigma*} Pr(a_1 ... a_n w), where w represents all possible terminations of the prefix a_1 ... a_n. The main result in this paper is an algorithm to compute such prefix probabilities given a stochastic Tree Adjoining Grammar (TAG). The algorithm achieves the required computation in O(n^6) time. The probability of subderivations that do not derive any words in the prefix, but contribute structurally to its derivation, are precomputed to achieve termination. This algorithm enables existing corpus-based estimation techniques for stochastic TAGs to be used for language modelling.
* 7 pages, 2 Postscript figures, uses colacl.sty, graphicx.sty, psfrag.sty