 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variant of Earley Parsing
Paper and Code
Aug 31, 1998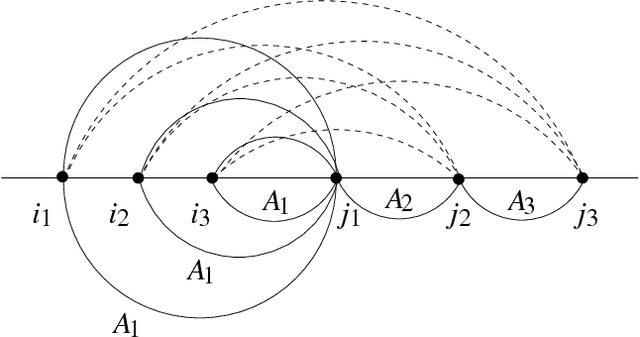
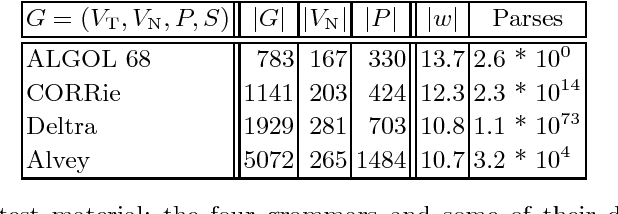
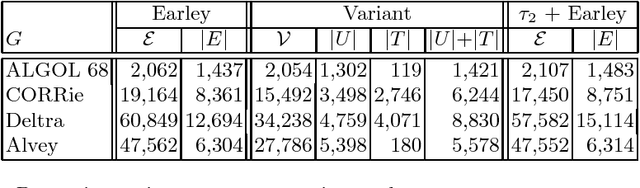
The Earley algorithm is a widely used parsing method in natural language processing applications. We introduce a variant of Earley parsing that is based on a ``delayed'' recognition of constituents. This allows us to start the recognition of a constituent only in cases in which all of its subconstituents have been found within the input string. This is particularly advantageous in several cases in which partial analysis of a constituent cannot be completed and in general in all cases of productions sharing some suffix of their right-hand sides (even for different left-hand side nonterminals). Although the two algorithms result in the same asymptotic time and space complexity, from a practical perspective our algorithm improves the time and space requirements of the original method, as shown by reported experimental results.