 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Classification of Human Translation and Machine Translation: A Study from the Perspective of Lexical Diversity
May 10, 2021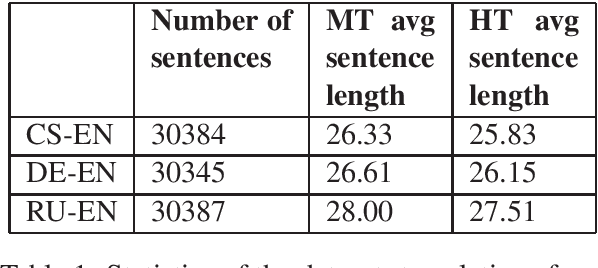
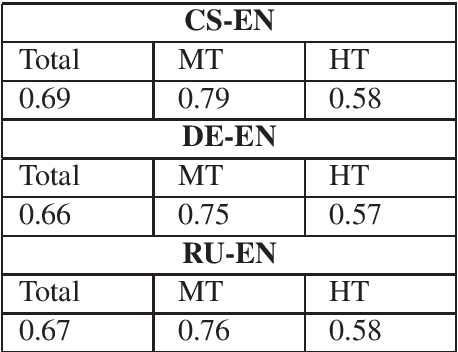
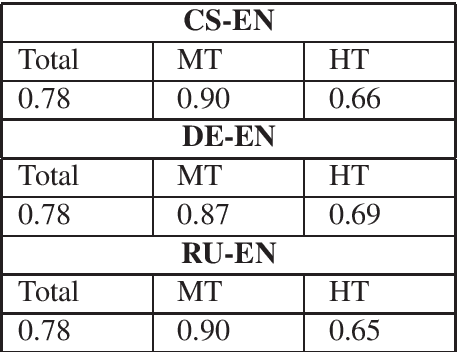
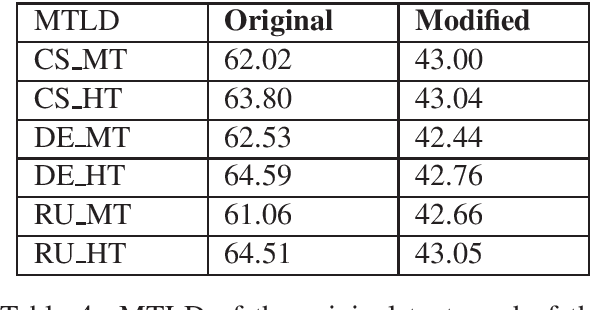
By using a trigram model and fine-tuning a pretrained BERT model for sequence classification, we show that machine translation and human translation can be classified with an accuracy above chance level, which suggests that machine translation and human translation are different in a systematic way. The classification accuracy of machine translation is much higher than of human translation. We show that this may be explained by the difference in lexical diversity between machine translation and human translation. If machine translation has independent patterns from human translation, automatic metrics which measure the deviation of machine translation from human translation may conflate difference with quality. Our experiment with two different types of automatic metrics shows correlation with the result of the classification task. Therefore, we suggest the difference in lexical diversity between machine translation and human translation be given more attention in machine translation evaluation.
A short proof that $O_2$ is an MCFL
Mar 11, 2016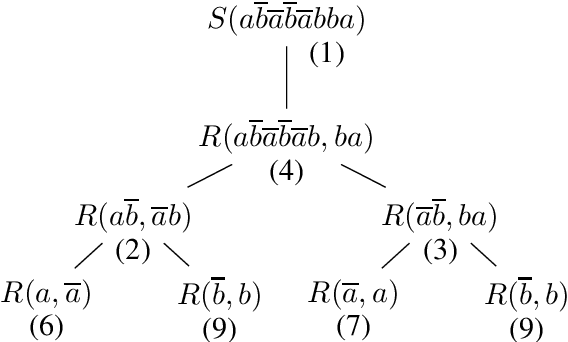
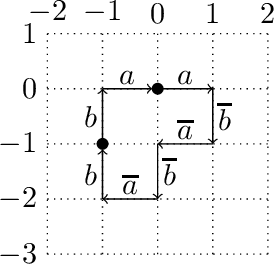
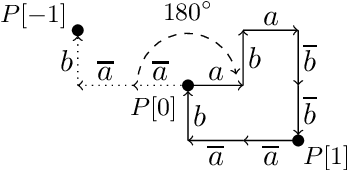
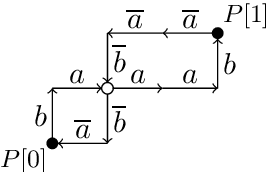
We present a new proof that $O_2$ is a multiple context-free language. It contrasts with a recent proof by Salvati (2015) in its avoidance of concepts that seem specific to two-dimensional geometry, such as the complex exponential function. Our simple proof creates realistic prospects of widening the results to higher dimensions. This finding is of central importance to the relation between extreme free word order and classes of grammars used to describe the syntax of natural language.
Tabular Parsing
Apr 05, 2004
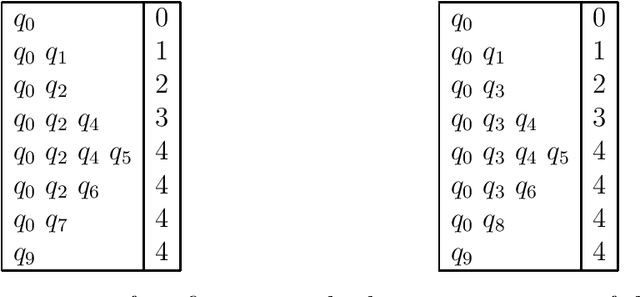
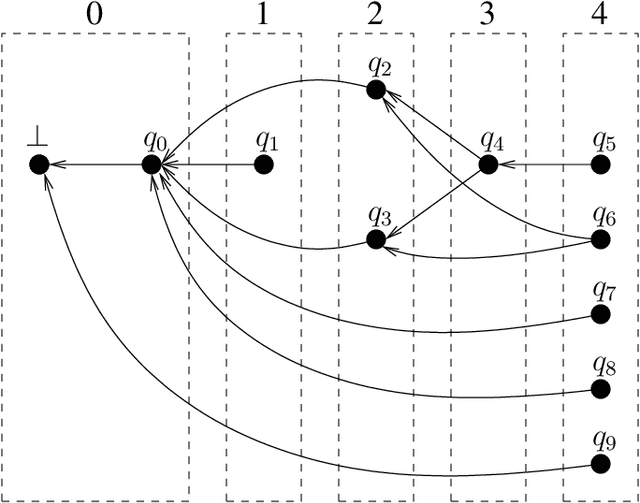
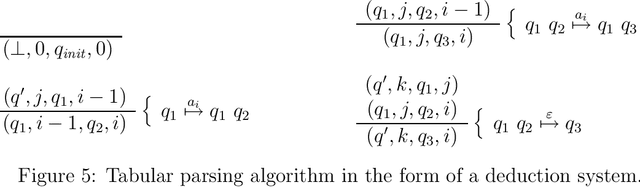
This is a tutorial on tabular parsing, on the basis of tabulation of nondeterministic push-down automata. Discussed are Earley's algorithm, the Cocke-Kasami-Younger algorithm, tabular LR parsing, the construction of parse trees, and further issues.
* 21 pages, 14 figures
Probabilistic Parsing Strategies
Nov 14, 2002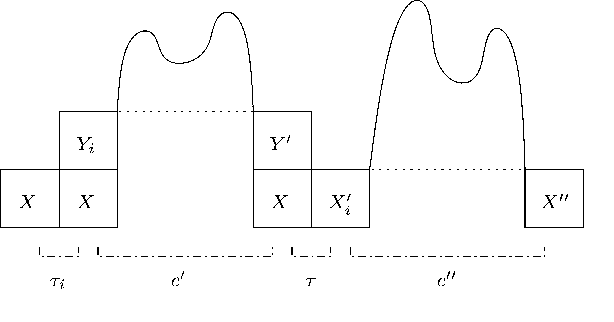


We present new results on the relation between purely symbolic context-free parsing strategies and their probabilistic counter-parts. Such parsing strategies are seen as constructions of push-down devices from grammars. We show that preservation of probability distribution is possible under two conditions, viz. the correct-prefix property and the property of strong predictiveness. These results generalize existing results in the literature that were obtained by considering parsing strategies in isolation. From our general results we also derive negative results on so-called generalized LR parsing.
Practical experiments with regular approximation of context-free languages
Oct 25, 1999Several methods are discussed that construct a finite automaton given a context-free grammar, including both methods that lead to subsets and those that lead to supersets of the original context-free language. Some of these methods of regular approximation are new, and some others are presented here in a more refined form with respect to existing literature. Practical experiments with the different methods of regular approximation are performed for spoken-language input: hypotheses from a speech recognizer are filtered through a finite automaton.
Robust Grammatical Analysis for Spoken Dialogue Systems
Jun 25, 1999
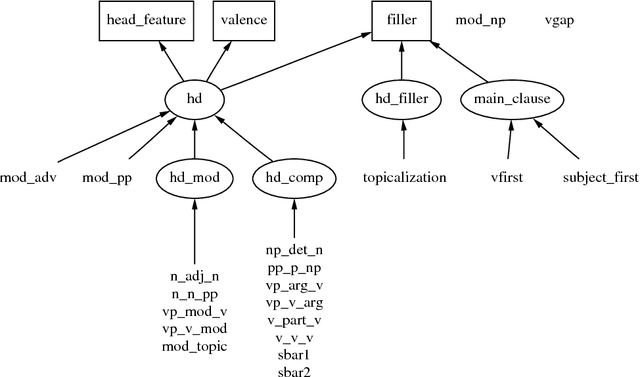
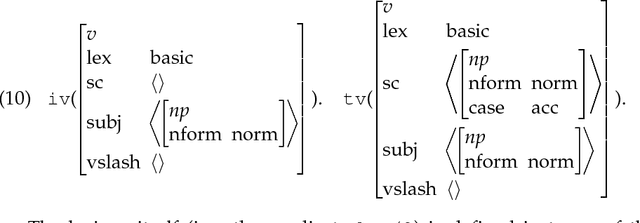
We argue that grammatical analysis is a viable alternative to concept spotting for processing spoken input in a practical spoken dialogue system. We discuss the structure of the grammar, and a model for robust parsing which combines linguistic sources of information and statistical sources of information. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
Prefix Probabilities from Stochastic Tree Adjoining Grammars
Sep 18, 1998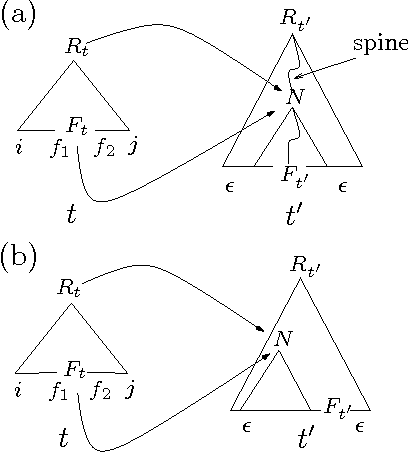

Language models for speech recognition typically use a probability model of the form Pr(a_n | a_1, a_2, ..., a_{n-1}). Stochastic grammars, on the other hand, are typically used to assign structure to utterances. A language model of the above form is constructed from such grammars by computing the prefix probability Sum_{w in Sigma*} Pr(a_1 ... a_n w), where w represents all possible terminations of the prefix a_1 ... a_n. The main result in this paper is an algorithm to compute such prefix probabilities given a stochastic Tree Adjoining Grammar (TAG). The algorithm achieves the required computation in O(n^6) time. The probability of subderivations that do not derive any words in the prefix, but contribute structurally to its derivation, are precomputed to achieve termination. This algorithm enables existing corpus-based estimation techniques for stochastic TAGs to be used for language modelling.
* 7 pages, 2 Postscript figures, uses colacl.sty, graphicx.sty, psfrag.sty
A Variant of Earley Parsing
Aug 31, 1998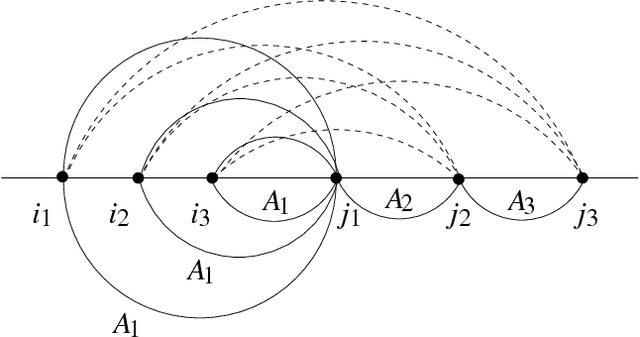
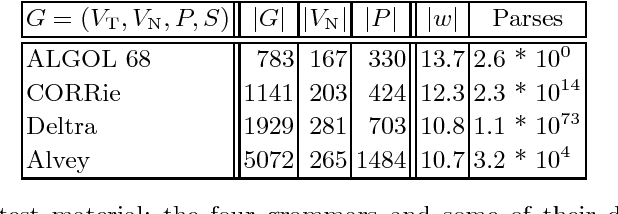
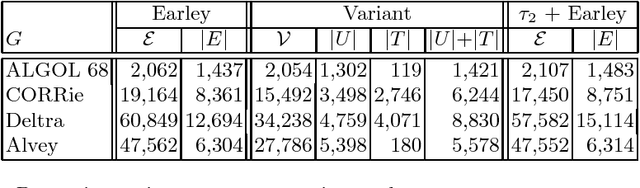
The Earley algorithm is a widely used parsing method in natural language processing applications. We introduce a variant of Earley parsing that is based on a ``delayed'' recognition of constituents. This allows us to start the recognition of a constituent only in cases in which all of its subconstituents have been found within the input string. This is particularly advantageous in several cases in which partial analysis of a constituent cannot be completed and in general in all cases of productions sharing some suffix of their right-hand sides (even for different left-hand side nonterminals). Although the two algorithms result in the same asymptotic time and space complexity, from a practical perspective our algorithm improves the time and space requirements of the original method, as shown by reported experimental results.
* 12 pages, 1 Postscript figure, uses psfig.tex and llncs.sty
Grammatical analysis in the OVIS spoken-dialogue system
May 01, 1997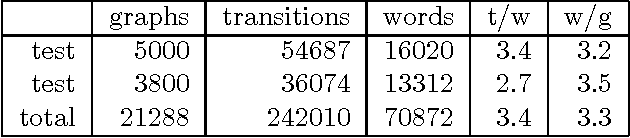
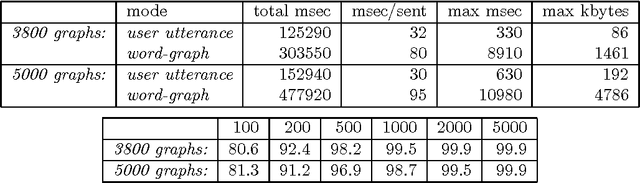
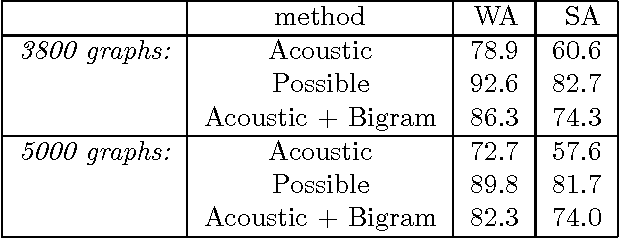
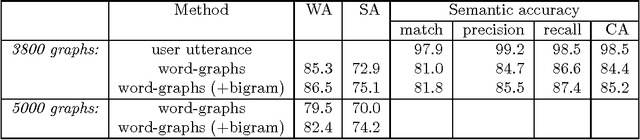
We argue that grammatical processing is a viable alternative to concept spotting for processing spoken input in a practical dialogue system. We discuss the structure of the grammar, the properties of the parser, and a method for achieving robustness. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
* 8 pages, uses aclap.sty
Efficient Tabular LR Parsing
May 13, 1996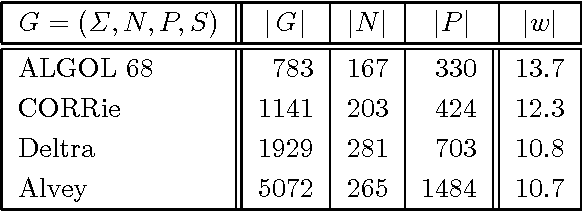
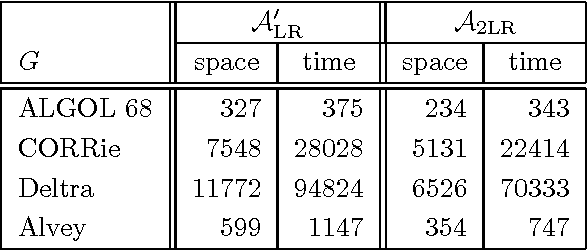
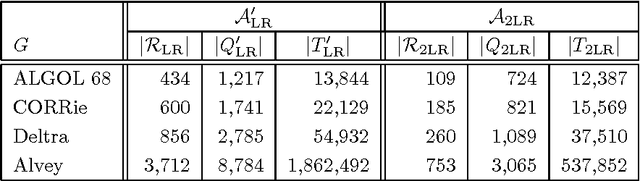
We give a new treatment of tabular LR parsing, which is an alternative to Tomita's generalized LR algorithm. The advantage is twofold. Firstly, our treatment is conceptually more attractive because it uses simpler concepts, such as grammar transformations and standard tabulation techniques also know as chart parsing. Secondly, the static and dynamic complexity of parsing, both in space and time, is significantly reduced.
* 8 pages, uses aclap.sty