 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Character-level Translations Worth the Wait? An Extensive Comparison of Character- and Subword-level Models for Machine Translation
Feb 28, 2023Pretrained large character-level language models have been recently revitalized and shown to be competitive with subword models across a range of NLP tasks. However, there has not been any research showing their effectiveness in neural machine translation (NMT). This work performs an extensive comparison across multiple languages and experimental conditions of state-of-the-art character- and subword-level pre-trained models (ByT5 and mT5, respectively) on NMT, and shows that the former not only are effective in translation, but frequently outperform subword models, particularly in cases where training data is limited. The only drawback of character models appears to be their inefficiency (at least 4 times slower to train and for inference). Further analysis indicates that character models are capable of implicitly translating on the word or subword level, thereby nullifying a major potential weakness of operating on the character level.
Subword-Delimited Downsampling for Better Character-Level Translation
Dec 02, 2022

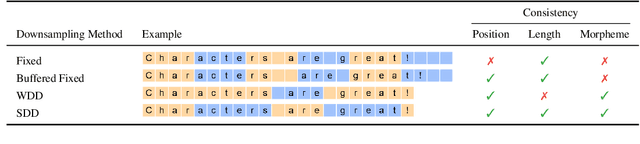

Subword-level models have been the dominant paradigm in NLP. However, character-level models have the benefit of seeing each character individually, providing the model with more detailed information that ultimately could lead to better models. Recent works have shown character-level models to be competitive with subword models, but costly in terms of time and computation. Character-level models with a downsampling component alleviate this, but at the cost of quality, particularly for machine translation. This work analyzes the problems of previous downsampling methods and introduces a novel downsampling method which is informed by subwords. This new downsampling method not only outperforms existing downsampling methods, showing that downsampling characters can be done without sacrificing quality, but also leads to promising performance compared to subword models for translation.
Patching Leaks in the Charformer for Efficient Character-Level Generation
May 27, 2022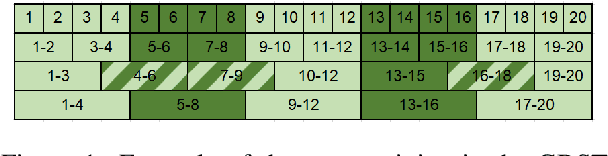

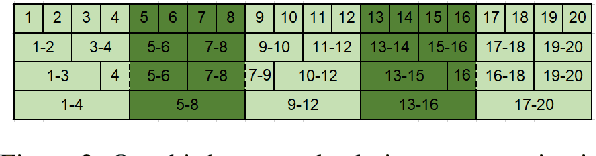
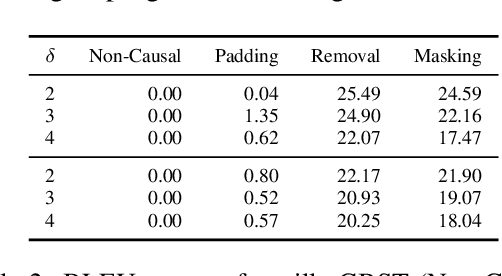
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.
Hyper-X: A Unified Hypernetwork for Multi-Task Multilingual Transfer
May 24, 2022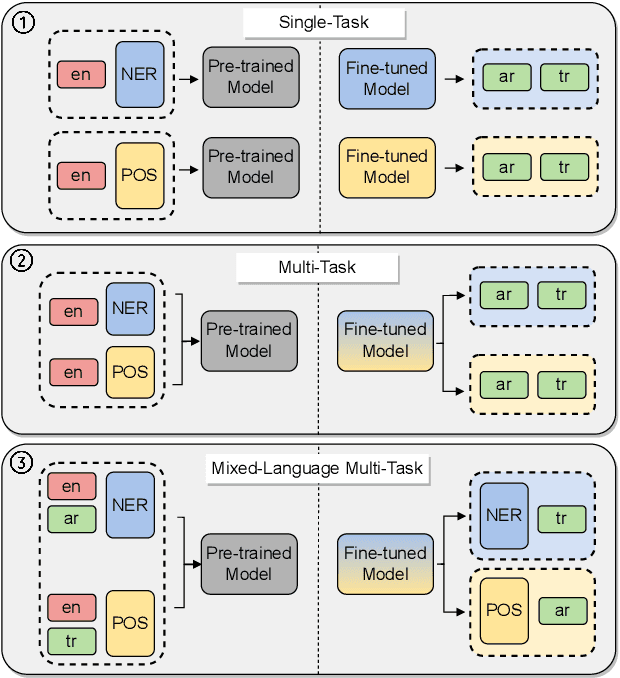

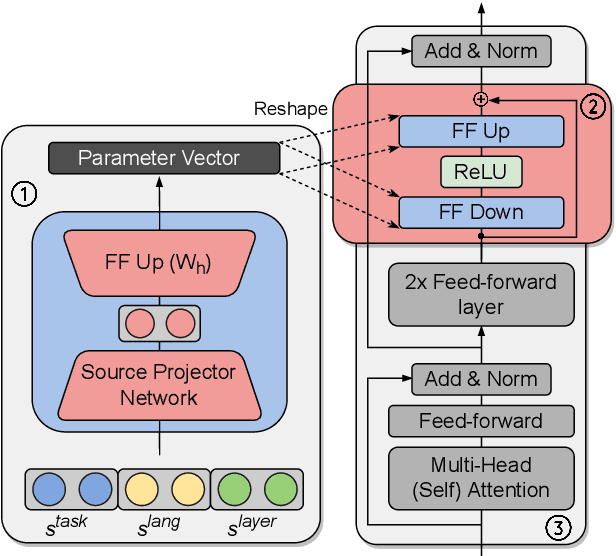
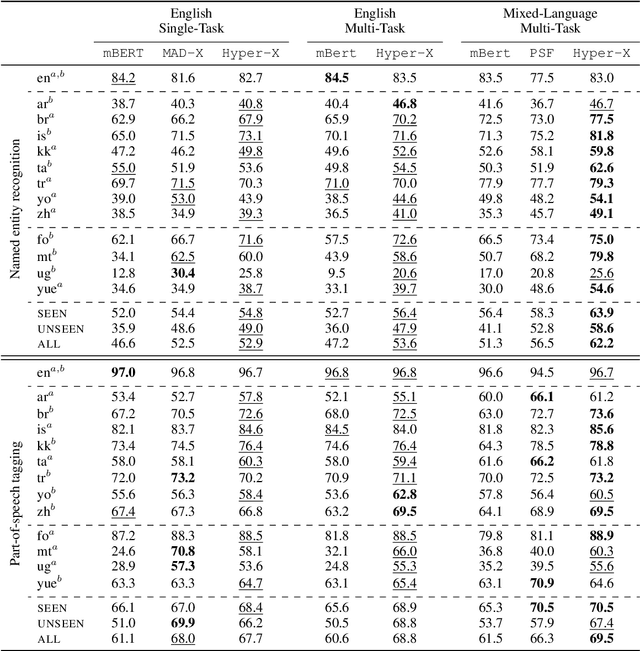
Massively multilingual models are promising for transfer learning across tasks and languages. However, existing methods are unable to fully leverage training data when it is available in different task-language combinations. To exploit such heterogeneous supervision we propose Hyper-X, a unified hypernetwork that generates weights for parameter-efficient adapter modules conditioned on both tasks and language embeddings. By learning to combine task and language-specific knowledge our model enables zero-shot transfer for unseen languages and task-language combinations. Our experiments on a diverse set of languages demonstrate that Hyper-X achieves the best gain when a mixture of multiple resources is available while performing on par with strong baselines in the standard scenario. Finally, Hyper-X consistently produces strong results in few-shot scenarios for new languages and tasks showing the effectiveness of our approach beyond zero-shot transfer.
The Importance of Context in Very Low Resource Language Modeling
May 10, 2022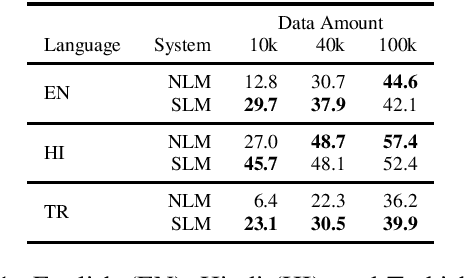
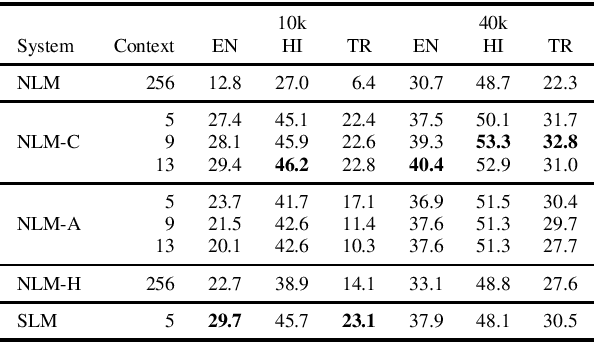
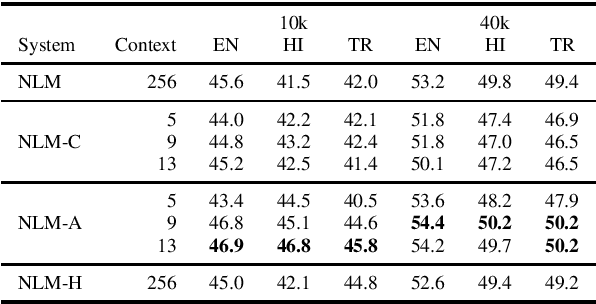
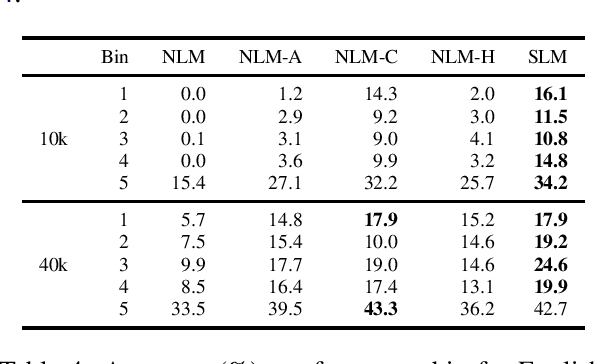
This paper investigates very low resource language model pretraining, when less than 100 thousand sentences are available. We find that, in very low resource scenarios, statistical n-gram language models outperform state-of-the-art neural models. Our experiments show that this is mainly due to the focus of the former on a local context. As such, we introduce three methods to improve a neural model's performance in the low-resource setting, finding that limiting the model's self-attention is the most effective one, improving on downstream tasks such as NLI and POS tagging by up to 5% for the languages we test on: English, Hindi, and Turkish.
Unsupervised Translation of German--Lower Sorbian: Exploring Training and Novel Transfer Methods on a Low-Resource Language
Sep 24, 2021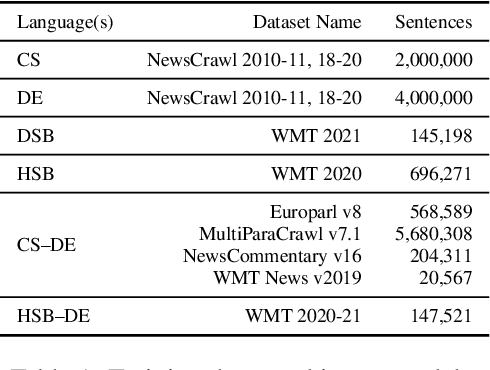
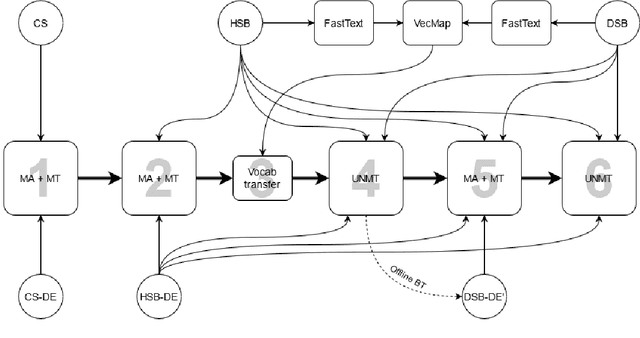
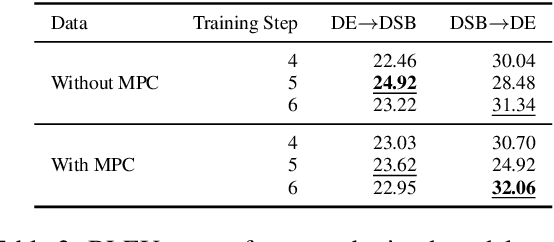
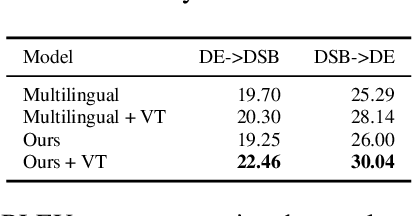
This paper describes the methods behind the systems submitted by the University of Groningen for the WMT 2021 Unsupervised Machine Translation task for German--Lower Sorbian (DE--DSB): a high-resource language to a low-resource one. Our system uses a transformer encoder-decoder architecture in which we make three changes to the standard training procedure. First, our training focuses on two languages at a time, contrasting with a wealth of research on multilingual systems. Second, we introduce a novel method for initializing the vocabulary of an unseen language, achieving improvements of 3.2 BLEU for DE$\rightarrow$DSB and 4.0 BLEU for DSB$\rightarrow$DE. Lastly, we experiment with the order in which offline and online back-translation are used to train an unsupervised system, finding that using online back-translation first works better for DE$\rightarrow$DSB by 2.76 BLEU. Our submissions ranked first (tied with another team) for DSB$\rightarrow$DE and third for DE$\rightarrow$DSB.
UDapter: Language Adaptation for Truly Universal Dependency Parsing
Apr 29, 2020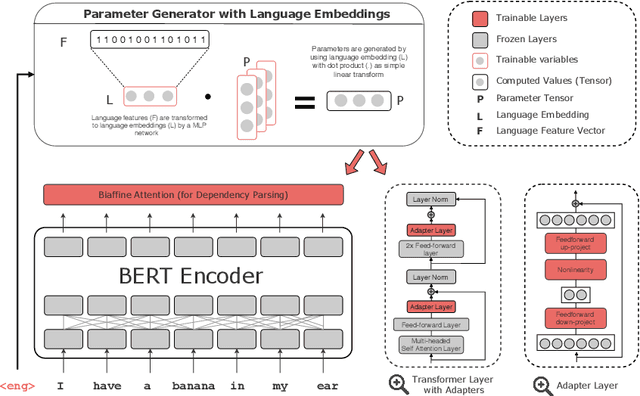
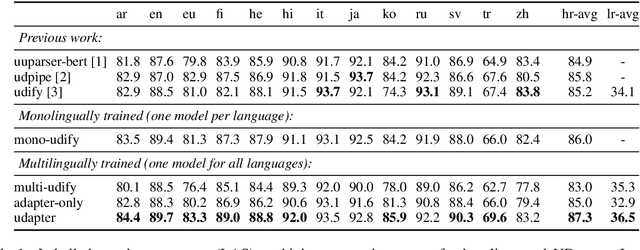
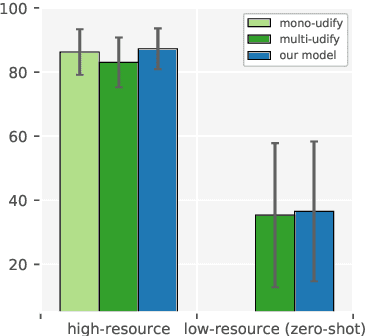

Recent advances in the field of multilingual dependency parsing have brought the idea of a truly universal parser closer to reality. However, cross-language interference and restrained model capacity remain a major obstacle to this pursuit. To address these issues, we propose a novel multilingual task adaptation approach based on recent work in parameter-efficient transfer learning, which allows for an easy but effective integration of existing linguistic typology features into the parsing network. The resulting parser, UDapter, consistently outperforms strong monolingual and multilingual baselines on both high-resource and low-resource (zero-shot) languages, setting a new state of the art in multilingual UD parsing. Our in-depth analyses show that soft parameter sharing via typological features is key to this success.
BERTje: A Dutch BERT Model
Dec 19, 2019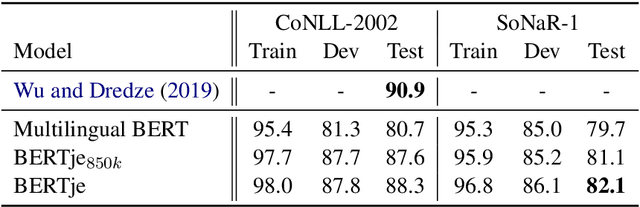
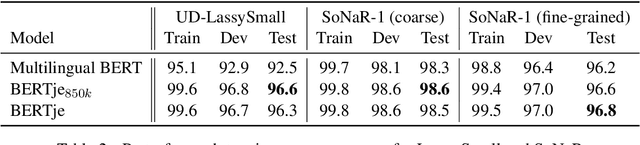


The transformer-based pre-trained language model BERT has helped to improve state-of-the-art performance on many natural language processing (NLP) tasks. Using the same architecture and parameters, we developed and evaluated a monolingual Dutch BERT model called BERTje. Compared to the multilingual BERT model, which includes Dutch but is only based on Wikipedia text, BERTje is based on a large and diverse dataset of 2.4 billion tokens. BERTje consistently outperforms the equally-sized multilingual BERT model on downstream NLP tasks (part-of-speech tagging, named-entity recognition, semantic role labeling, and sentiment analysis). Our pre-trained Dutch BERT model is made available at https://github.com/wietsedv/bertje.
MoNoise: Modeling Noise Using a Modular Normalization System
Oct 10, 2017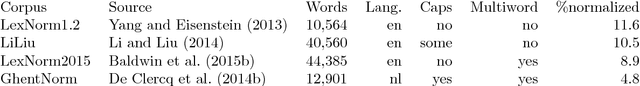

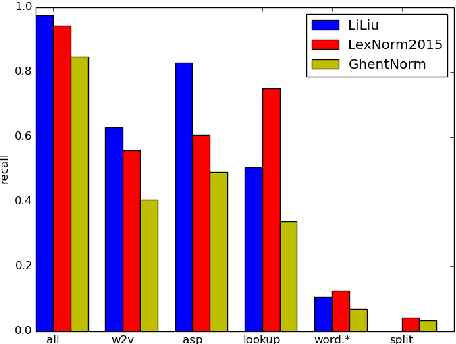
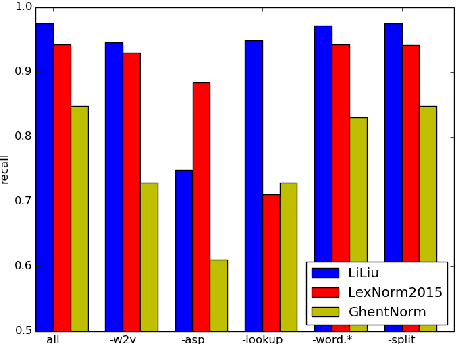
We propose MoNoise: a normalization model focused on generalizability and efficiency, it aims at being easily reusable and adaptable. Normalization is the task of translating texts from a non- canonical domain to a more canonical domain, in our case: from social media data to standard language. Our proposed model is based on a modular candidate generation in which each module is responsible for a different type of normalization action. The most important generation modules are a spelling correction system and a word embeddings module. Depending on the definition of the normalization task, a static lookup list can be crucial for performance. We train a random forest classifier to rank the candidates, which generalizes well to all different types of normaliza- tion actions. Most features for the ranking originate from the generation modules; besides these features, N-gram features prove to be an important source of information. We show that MoNoise beats the state-of-the-art on different normalization benchmarks for English and Dutch, which all define the task of normalization slightly different.
Bilingual Learning of Multi-sense Embeddings with Discrete Autoencoders
Mar 30, 2016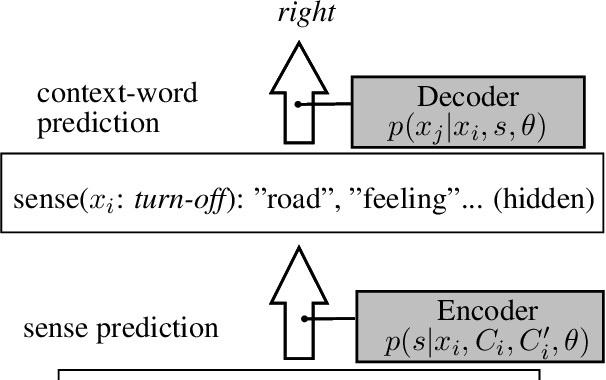
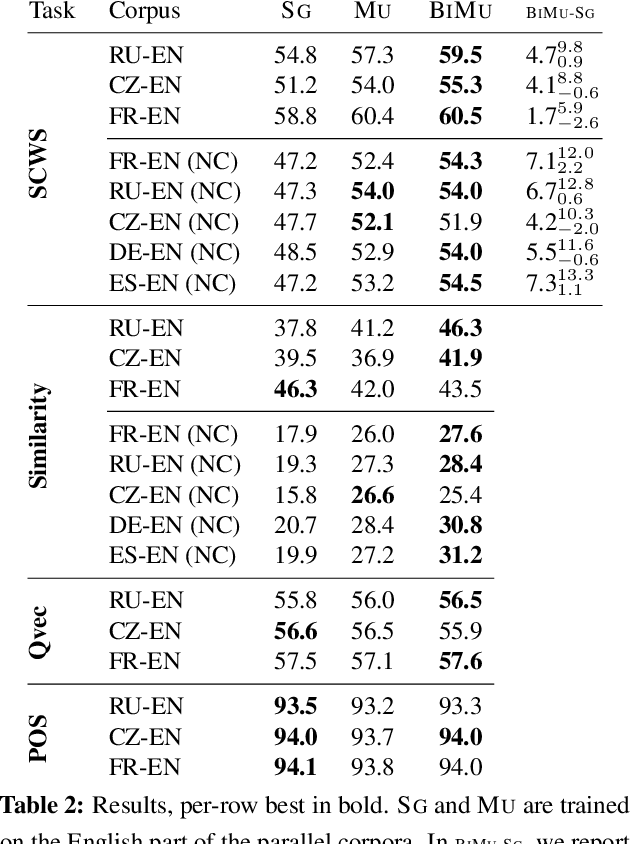
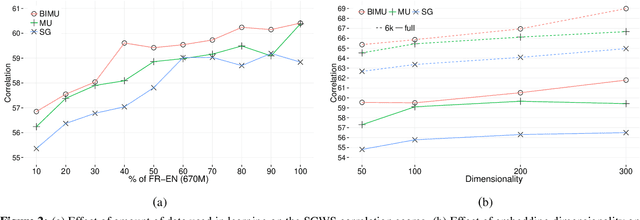
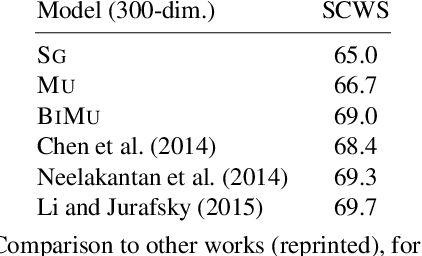
We present an approach to learning multi-sense word embeddings relying both on monolingual and bilingual information. Our model consists of an encoder, which uses monolingual and bilingual context (i.e. a parallel sentence) to choose a sense for a given word, and a decoder which predicts context words based on the chosen sense. The two components are estimated jointly. We observe that the word representations induced from bilingual data outperform the monolingual counterparts across a range of evaluation tasks, even though crosslingual information is not available at test time.