 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of a Single Blind Literary Taste Test with Short Anonymized Novel Fragments
Nov 03, 2020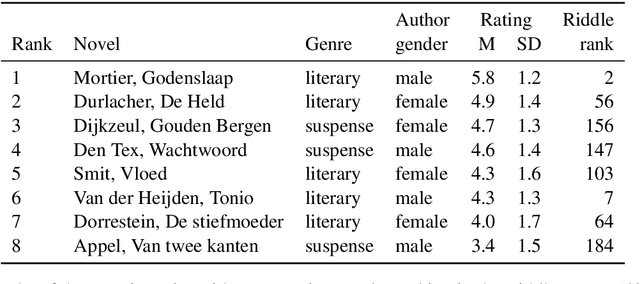

It is an open question to what extent perceptions of literary quality are derived from text-intrinsic versus social factors. While supervised models can predict literary quality ratings from textual factors quite successfully, as shown in the Riddle of Literary Quality project (Koolen et al., 2020), this does not prove that social factors are not important, nor can we assume that readers make judgments on literary quality in the same way and based on the same information as machine learning models. We report the results of a pilot study to gauge the effect of textual features on literary ratings of Dutch-language novels by participants in a controlled experiment with 48 participants. In an exploratory analysis, we compare the ratings to those from the large reader survey of the Riddle in which social factors were not excluded, and to machine learning predictions of those literary ratings. We find moderate to strong correlations of questionnaire ratings with the survey ratings, but the predictions are closer to the survey ratings. Code and data: https://github.com/andreasvc/litquest
A Benchmark of Rule-Based and Neural Coreference Resolution in Dutch Novels and News
Nov 03, 2020
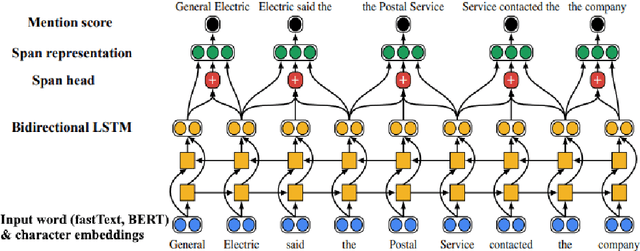


We evaluate a rule-based (Lee et al., 2013) and neural (Lee et al., 2018) coreference system on Dutch datasets of two domains: literary novels and news/Wikipedia text. The results provide insight into the relative strengths of data-driven and knowledge-driven systems, as well as the influence of domain, document length, and annotation schemes. The neural system performs best on news/Wikipedia text, while the rule-based system performs best on literature. The neural system shows weaknesses with limited training data and long documents, while the rule-based system is affected by annotation differences. The code and models used in this paper are available at https://github.com/andreasvc/crac2020
Embarrassingly Simple Unsupervised Aspect Extraction
Apr 28, 2020
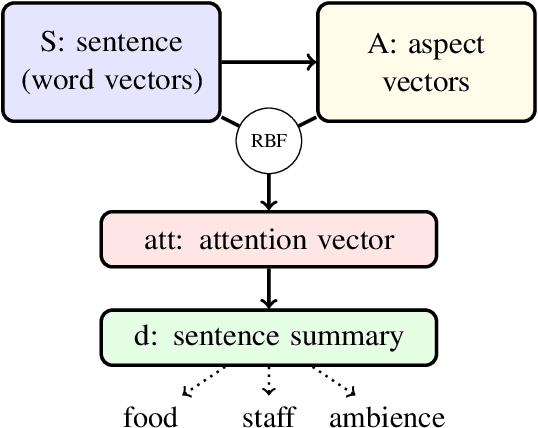

We present a simple but effective method for aspect identification in sentiment analysis. Our unsupervised method only requires word embeddings and a POS tagger, and is therefore straightforward to apply to new domains and languages. We introduce Contrastive Attention (CAt), a novel single-head attention mechanism based on an RBF kernel, which gives a considerable boost in performance and makes the model interpretable. Previous work relied on syntactic features and complex neural models. We show that given the simplicity of current benchmark datasets for aspect extraction, such complex models are not needed. The code to reproduce the experiments reported in this paper is available at https://github.com/clips/cat
What's so special about BERT's layers? A closer look at the NLP pipeline in monolingual and multilingual models
Apr 14, 2020
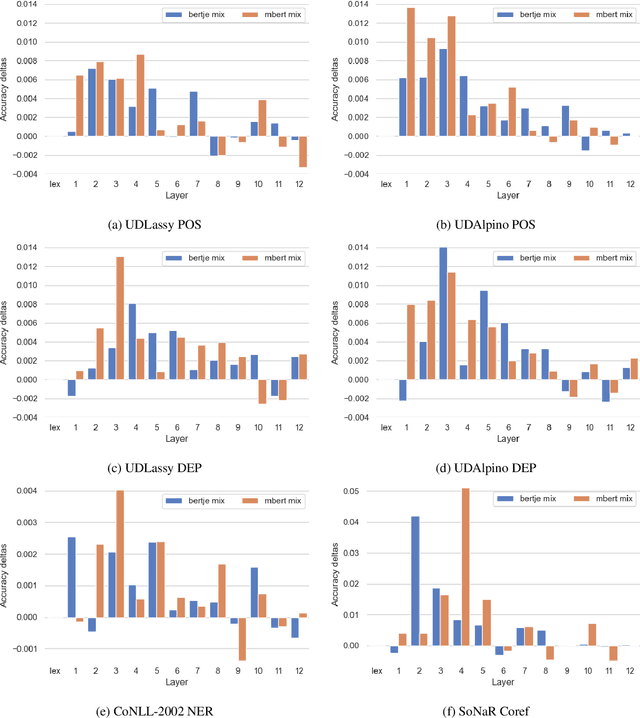

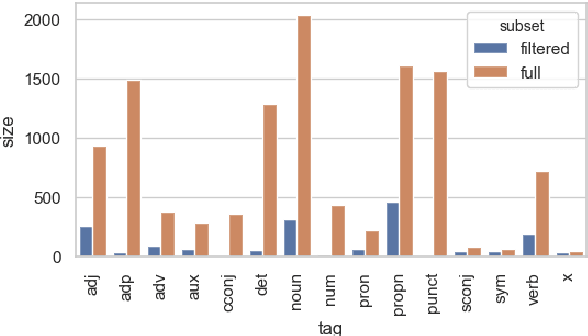
Experiments with transfer learning on pre-trained language models such as BERT have shown that the layers of these models resemble the classical NLP pipeline, with progressively more complex tasks being concentrated in later layers of the network. We investigate to what extent these results also hold for a language other than English. For this we probe a Dutch BERT-based model and the multilingual BERT model for Dutch NLP tasks. In addition, by considering the task of part-of-speech tagging in more detail, we show that also within a given task, information is spread over different parts of the network and the pipeline might not be as neat as it seems. Each layer has different specialisations and it is therefore useful to combine information from different layers for best results, instead of selecting a single layer based on the best overall performance.
BERTje: A Dutch BERT Model
Dec 19, 2019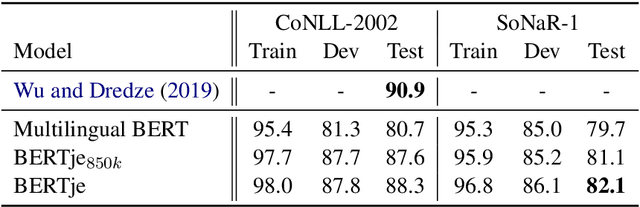
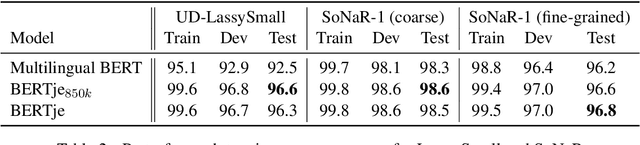


The transformer-based pre-trained language model BERT has helped to improve state-of-the-art performance on many natural language processing (NLP) tasks. Using the same architecture and parameters, we developed and evaluated a monolingual Dutch BERT model called BERTje. Compared to the multilingual BERT model, which includes Dutch but is only based on Wikipedia text, BERTje is based on a large and diverse dataset of 2.4 billion tokens. BERTje consistently outperforms the equally-sized multilingual BERT model on downstream NLP tasks (part-of-speech tagging, named-entity recognition, semantic role labeling, and sentiment analysis). Our pre-trained Dutch BERT model is made available at https://github.com/wietsedv/bertje.
A Data-Oriented Model of Literary Language
Jan 26, 2017


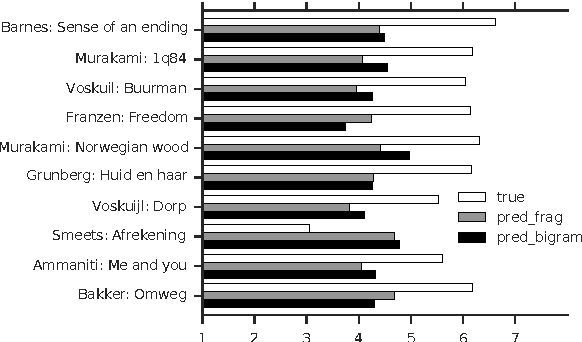
We consider the task of predicting how literary a text is, with a gold standard from human ratings. Aside from a standard bigram baseline, we apply rich syntactic tree fragments, mined from the training set, and a series of hand-picked features. Our model is the first to distinguish degrees of highly and less literary novels using a variety of lexical and syntactic features, and explains 76.0 % of the variation in literary ratings.
* To be published in EACL 2017, 11 pages
LAF-Fabric: a data analysis tool for Linguistic Annotation Framework with an application to the Hebrew Bible
Oct 01, 2014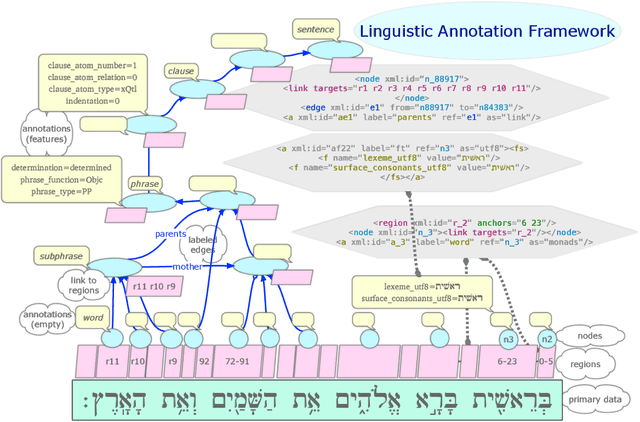
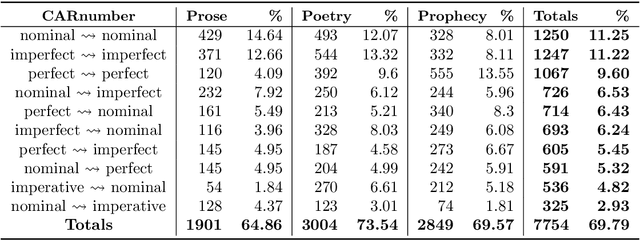


The Linguistic Annotation Framework (LAF) provides a general, extensible stand-off markup system for corpora. This paper discusses LAF-Fabric, a new tool to analyse LAF resources in general with an extension to process the Hebrew Bible in particular. We first walk through the history of the Hebrew Bible as text database in decennium-wide steps. Then we describe how LAF-Fabric may serve as an analysis tool for this corpus. Finally, we describe three analytic projects/workflows that benefit from the new LAF representation: 1) the study of linguistic variation: extract cooccurrence data of common nouns between the books of the Bible (Martijn Naaijer); 2) the study of the grammar of Hebrew poetry in the Psalms: extract clause typology (Gino Kalkman); 3) construction of a parser of classical Hebrew by Data Oriented Parsing: generate tree structures from the database (Andreas van Cranenburgh).