 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's so special about BERT's layers? A closer look at the NLP pipeline in monolingual and multilingual models
Paper and Code

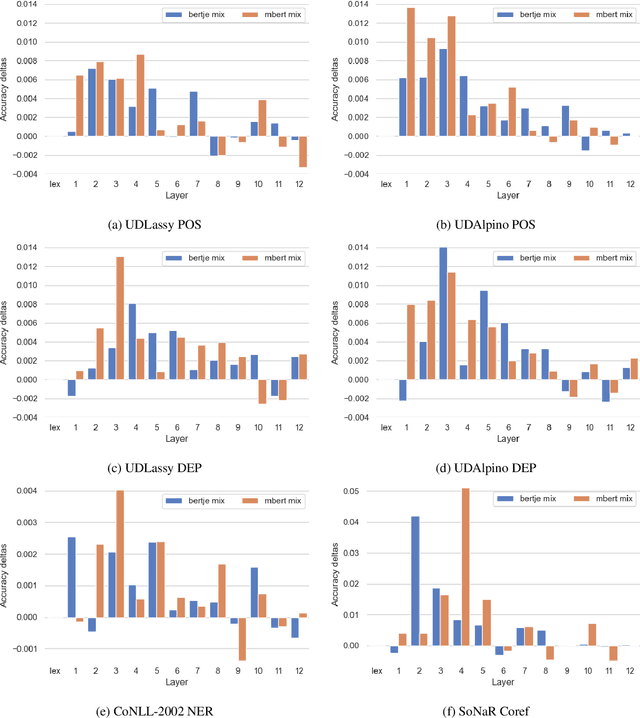

Experiments with transfer learning on pre-trained language models such as BERT have shown that the layers of these models resemble the classical NLP pipeline, with progressively more complex tasks being concentrated in later layers of the network. We investigate to what extent these results also hold for a language other than English. For this we probe a Dutch BERT-based model and the multilingual BERT model for Dutch NLP tasks. In addition, by considering the task of part-of-speech tagging in more detail, we show that also within a given task, information is spread over different parts of the network and the pipeline might not be as neat as it seems. Each layer has different specialisations and it is therefore useful to combine information from different layers for best results, instead of selecting a single layer based on the best overall performance.