 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTACLer: Tailored Curriculum Reinforcement Learning for Efficient Reasoning
Jan 29, 2026Large Language Models (LLMs) have shown remarkable performance on complex reasoning tasks, especially when equipped with long chain-of-thought (CoT) reasoning. However, eliciting long CoT typically requires large-scale reinforcement learning (RL) training, while often leading to overthinking with redundant intermediate steps. To improve learning and reasoning efficiency, while preserving or even enhancing performance, we propose TACLer, a model-tailored curriculum reinforcement learning framework that gradually increases the complexity of the data based on the model's proficiency in multi-stage RL training. TACLer features two core components: (i) tailored curriculum learning that determines what knowledge the model lacks and needs to learn in progressive stages; (ii) a hybrid Thinking/NoThinking reasoning paradigm that balances accuracy and efficiency by enabling or disabling the Thinking mode. Our experiments show that TACLer yields a twofold advantage in learning and reasoning: (i) it reduces computational cost, cutting training compute by over 50% compared to long thinking models and reducing inference token usage by over 42% relative to the base model; and (ii) it improves accuracy by over 9% on the base model, consistently outperforming state-of-the-art Nothinking and Thinking baselines across four math datasets with complex problems.
Practising responsibility: Ethics in NLP as a hands-on course
Dec 31, 2025As Natural Language Processing (NLP) systems become more pervasive, integrating ethical considerations into NLP education has become essential. However, this presents inherent challenges in curriculum development: the field's rapid evolution from both academia and industry, and the need to foster critical thinking beyond traditional technical training. We introduce our course on Ethical Aspects in NLP and our pedagogical approach, grounded in active learning through interactive sessions, hands-on activities, and "learning by teaching" methods. Over four years, the course has been refined and adapted across different institutions, educational levels, and interdisciplinary backgrounds; it has also yielded many reusable products, both in the form of teaching materials and in the form of actual educational products aimed at diverse audiences, made by the students themselves. By sharing our approach and experience, we hope to provide inspiration for educators seeking to incorporate social impact considerations into their curricula.
When Harry Meets Superman: The Role of The Interlocutor in Persona-Based Dialogue Generation
May 30, 2025Endowing dialogue agents with persona information has proven to significantly improve the consistency and diversity of their generations. While much focus has been placed on aligning dialogues with provided personas, the adaptation to the interlocutor's profile remains largely underexplored. In this work, we investigate three key aspects: (1) a model's ability to align responses with both the provided persona and the interlocutor's; (2) its robustness when dealing with familiar versus unfamiliar interlocutors and topics, and (3) the impact of additional fine-tuning on specific persona-based dialogues. We evaluate dialogues generated with diverse speaker pairings and topics, framing the evaluation as an author identification task and employing both LLM-as-a-judge and human evaluations. By systematically masking or disclosing information about the interlocutor, we assess its impact on dialogue generation. Results show that access to the interlocutor's persona improves the recognition of the target speaker, while masking it does the opposite. Although models generalise well across topics, they struggle with unfamiliar interlocutors. Finally, we found that in zero-shot settings, LLMs often copy biographical details, facilitating identification but trivialising the task.
Unsupervised Word-level Quality Estimation for Machine Translation Through the Lens of Annotators (Dis)agreement
May 29, 2025Word-level quality estimation (WQE) aims to automatically identify fine-grained error spans in machine-translated outputs and has found many uses, including assisting translators during post-editing. Modern WQE techniques are often expensive, involving prompting of large language models or ad-hoc training on large amounts of human-labeled data. In this work, we investigate efficient alternatives exploiting recent advances in language model interpretability and uncertainty quantification to identify translation errors from the inner workings of translation models. In our evaluation spanning 14 metrics across 12 translation directions, we quantify the impact of human label variation on metric performance by using multiple sets of human labels. Our results highlight the untapped potential of unsupervised metrics, the shortcomings of supervised methods when faced with label uncertainty, and the brittleness of single-annotator evaluation practices.
QE4PE: Word-level Quality Estimation for Human Post-Editing
Mar 04, 2025Word-level quality estimation (QE) detects erroneous spans in machine translations, which can direct and facilitate human post-editing. While the accuracy of word-level QE systems has been assessed extensively, their usability and downstream influence on the speed, quality and editing choices of human post-editing remain understudied. Our QE4PE study investigates the impact of word-level QE on machine translation (MT) post-editing in a realistic setting involving 42 professional post-editors across two translation directions. We compare four error-span highlight modalities, including supervised and uncertainty-based word-level QE methods, for identifying potential errors in the outputs of a state-of-the-art neural MT model. Post-editing effort and productivity are estimated by behavioral logs, while quality improvements are assessed by word- and segment-level human annotation. We find that domain, language and editors' speed are critical factors in determining highlights' effectiveness, with modest differences between human-made and automated QE highlights underlining a gap between accuracy and usability in professional workflows.
Multidimensional Consistency Improves Reasoning in Language Models
Mar 04, 2025While Large language models (LLMs) have proved able to address some complex reasoning tasks, we also know that they are highly sensitive to input variation, which can lead to different solution paths and final answers. Answer consistency across input variations can thus be taken as a sign of stronger confidence. Leveraging this insight, we introduce a framework, {\em Multidimensional Reasoning Consistency} where, focusing on math problems, models are systematically pushed to diversify solution paths towards a final answer, thereby testing them for answer consistency across multiple input variations. We induce variations in (i) order of shots in prompt, (ii) problem phrasing, and (iii) languages used. Extensive experiments on a large range of open-source state-of-the-art LLMs of various sizes show that reasoning consistency differs by variation dimension, and that by aggregating consistency across dimensions, our framework consistently enhances mathematical reasoning performance on both monolingual dataset GSM8K and multilingual dataset MGSM, especially for smaller models.
Are You Doubtful? Oh, It Might Be Difficult Then! Exploring the Use of Model Uncertainty for Question Difficulty Estimation
Dec 16, 2024



In an educational setting, an estimate of the difficulty of multiple-choice questions (MCQs), a commonly used strategy to assess learning progress, constitutes very useful information for both teachers and students. Since human assessment is costly from multiple points of view, automatic approaches to MCQ item difficulty estimation are investigated, yielding however mixed success until now. Our approach to this problem takes a different angle from previous work: asking various Large Language Models to tackle the questions included in two different MCQ datasets, we leverage model uncertainty to estimate item difficulty. By using both model uncertainty features as well as textual features in a Random Forest regressor, we show that uncertainty features contribute substantially to difficulty prediction, where difficulty is inversely proportional to the number of students who can correctly answer a question. In addition to showing the value of our approach, we also observe that our model achieves state-of-the-art results on the BEA publicly available dataset.
A gentle push funziona benissimo: making instructed models in Italian via contrastive activation steering
Nov 27, 2024Adapting models to a language that was only partially present in the pre-training data requires fine-tuning, which is expensive in terms of both data and computational resources. As an alternative to fine-tuning, we explore the potential of activation steering-based techniques to enhance model performance on Italian tasks. Through our experiments we show that Italian steering (i) can be successfully applied to different models, (ii) achieves performances comparable to, or even better than, fine-tuned models for Italian, and (iii) yields higher quality and consistency in Italian generations. We also discuss the utility of steering and fine-tuning in the contemporary LLM landscape where models are anyway getting high Italian performances even if not explicitly trained in this language.
Choosy Babies Need One Coach: Inducing Mode-Seeking Behavior in BabyLlama with Reverse KL Divergence
Oct 29, 2024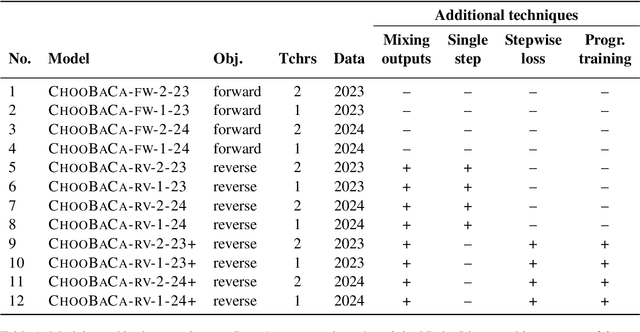

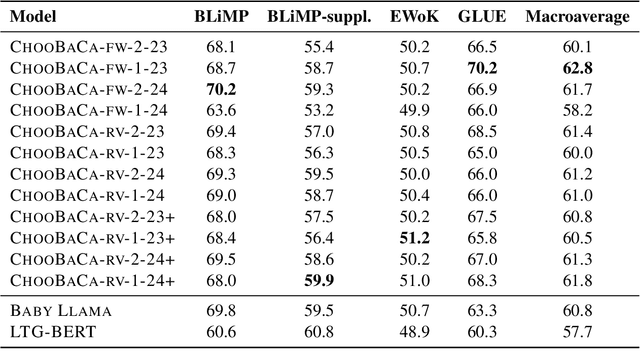
This study presents our submission to the Strict-Small Track of the 2nd BabyLM Challenge. We use a teacher-student distillation setup with the BabyLLaMa model (Timiryasov and Tastet, 2023) as a backbone. To make the student's learning process more focused, we replace the objective function with a reverse Kullback-Leibler divergence, known to cause mode-seeking (rather than mode-averaging) behaviour in computational learners. We further experiment with having a single teacher (instead of an ensemble of two teachers) and implement additional optimization strategies to improve the distillation process. Our experiments show that under reverse KL divergence, a single-teacher model often outperforms or matches multiple-teacher models across most tasks. Additionally, incorporating advanced optimization techniques further enhances model performance, demonstrating the effectiveness and robustness of our proposed approach. These findings support our idea that "choosy babies need one coach".
Non Verbis, Sed Rebus: Large Language Models are Weak Solvers of Italian Rebuses
Aug 01, 2024Rebuses are puzzles requiring constrained multi-step reasoning to identify a hidden phrase from a set of images and letters. In this work, we introduce a large collection of verbalized rebuses for the Italian language and use it to assess the rebus-solving capabilities of state-of-the-art large language models. While general-purpose systems such as LLaMA-3 and GPT-4o perform poorly on this task, ad-hoc fine-tuning seems to improve models' performance. However, we find that performance gains from training are largely motivated by memorization. Our results suggest that rebus solving remains a challenging test bed to evaluate large language models' linguistic proficiency and sequential instruction-following skills.