 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA gentle push funziona benissimo: making instructed models in Italian via contrastive activation steering
Nov 27, 2024Adapting models to a language that was only partially present in the pre-training data requires fine-tuning, which is expensive in terms of both data and computational resources. As an alternative to fine-tuning, we explore the potential of activation steering-based techniques to enhance model performance on Italian tasks. Through our experiments we show that Italian steering (i) can be successfully applied to different models, (ii) achieves performances comparable to, or even better than, fine-tuned models for Italian, and (iii) yields higher quality and consistency in Italian generations. We also discuss the utility of steering and fine-tuning in the contemporary LLM landscape where models are anyway getting high Italian performances even if not explicitly trained in this language.
Let the Models Respond: Interpreting Language Model Detoxification Through the Lens of Prompt Dependence
Sep 01, 2023


Due to language models' propensity to generate toxic or hateful responses, several techniques were developed to align model generations with users' preferences. Despite the effectiveness of such methods in improving the safety of model interactions, their impact on models' internal processes is still poorly understood. In this work, we apply popular detoxification approaches to several language models and quantify their impact on the resulting models' prompt dependence using feature attribution methods. We evaluate the effectiveness of counter-narrative fine-tuning and compare it with reinforcement learning-driven detoxification, observing differences in prompt reliance between the two methods despite their similar detoxification performances.
AI-UPV at EXIST 2023 -- Sexism Characterization Using Large Language Models Under The Learning with Disagreements Regime
Jul 07, 2023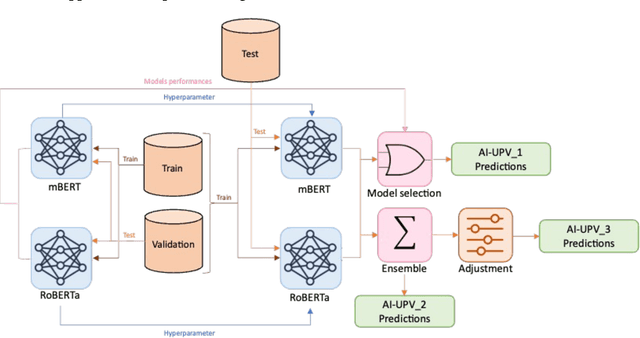
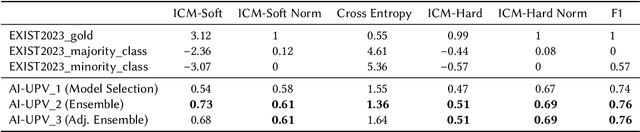
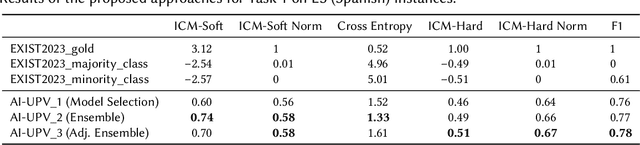
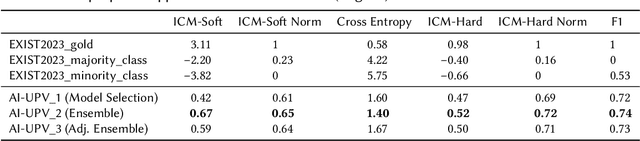
With the increasing influence of social media platforms, it has become crucial to develop automated systems capable of detecting instances of sexism and other disrespectful and hateful behaviors to promote a more inclusive and respectful online environment. Nevertheless, these tasks are considerably challenging considering different hate categories and the author's intentions, especially under the learning with disagreements regime. This paper describes AI-UPV team's participation in the EXIST (sEXism Identification in Social neTworks) Lab at CLEF 2023. The proposed approach aims at addressing the task of sexism identification and characterization under the learning with disagreements paradigm by training directly from the data with disagreements, without using any aggregated label. Yet, performances considering both soft and hard evaluations are reported. The proposed system uses large language models (i.e., mBERT and XLM-RoBERTa) and ensemble strategies for sexism identification and classification in English and Spanish. In particular, our system is articulated in three different pipelines. The ensemble approach outperformed the individual large language models obtaining the best performances both adopting a soft and a hard label evaluation. This work describes the participation in all the three EXIST tasks, considering a soft evaluation, it obtained fourth place in Task 2 at EXIST and first place in Task 3, with the highest ICM-Soft of -2.32 and a normalized ICM-Soft of 0.79. The source code of our approaches is publicly available at https://github.com/AngelFelipeMP/Sexism-LLM-Learning-With-Disagreement.
One Configuration to Rule Them All? Towards Hyperparameter Transfer in Topic Models using Multi-Objective Bayesian Optimization
Feb 15, 2022
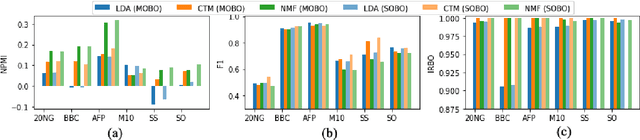


Topic models are statistical methods that extract underlying topics from document collections. When performing topic modeling, a user usually desires topics that are coherent, diverse between each other, and that constitute good document representations for downstream tasks (e.g. document classification). In this paper, we conduct a multi-objective hyperparameter optimization of three well-known topic models. The obtained results reveal the conflicting nature of different objectives and that the training corpus characteristics are crucial for the hyperparameter selection, suggesting that it is possible to transfer the optimal hyperparameter configurations between datasets.
Benchmark dataset of memes with text transcriptions for automatic detection of multi-modal misogynistic content
Jun 15, 2021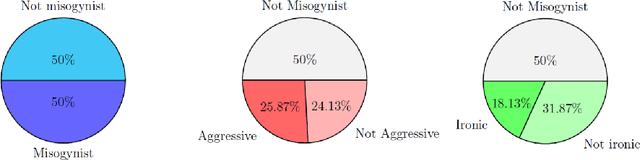
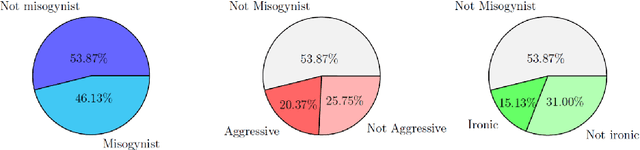

In this paper we present a benchmark dataset generated as part of a project for automatic identification of misogyny within online content, which focuses in particular on memes. The benchmark here described is composed of 800 memes collected from the most popular social media platforms, such as Facebook, Twitter, Instagram and Reddit, and consulting websites dedicated to collection and creation of memes. To gather misogynistic memes, specific keywords that refer to misogynistic content have been considered as search criterion, considering different manifestations of hatred against women, such as body shaming, stereotyping, objectification and violence. In parallel, memes with no misogynist content have been manually downloaded from the same web sources. Among all the collected memes, three domain experts have selected a dataset of 800 memes equally balanced between misogynistic and non-misogynistic ones. This dataset has been validated through a crowdsourcing platform, involving 60 subjects for the labelling process, in order to collect three evaluations for each instance. Two further binary labels have been collected from both the experts and the crowdsourcing platform, for memes evaluated as misogynistic, concerning aggressiveness and irony. Finally for each meme, the text has been manually transcribed. The dataset provided is thus composed of the 800 memes, the labels given by the experts and those obtained by the crowdsourcing validation, and the transcribed texts. This data can be used to approach the problem of automatic detection of misogynistic content on the Web relying on both textual and visual cues, facing phenomenons that are growing every day such as cybersexism and technology-facilitated violence.
Cross-lingual Contextualized Topic Models with Zero-shot Learning
Apr 16, 2020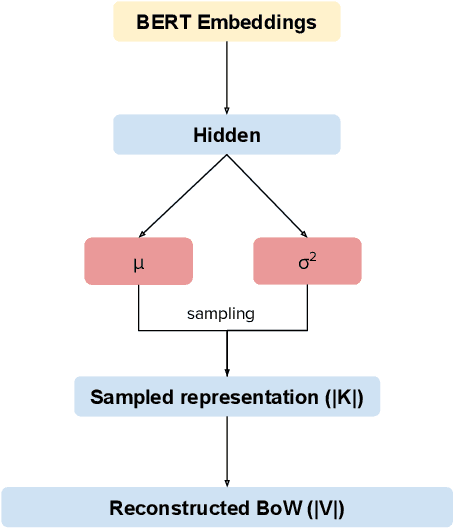
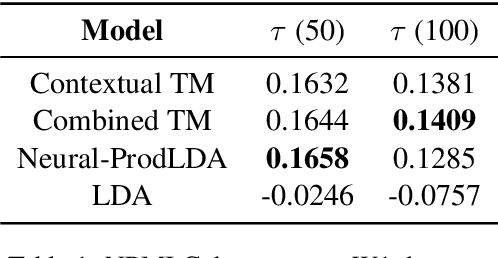
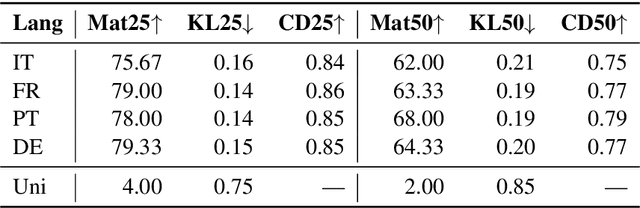
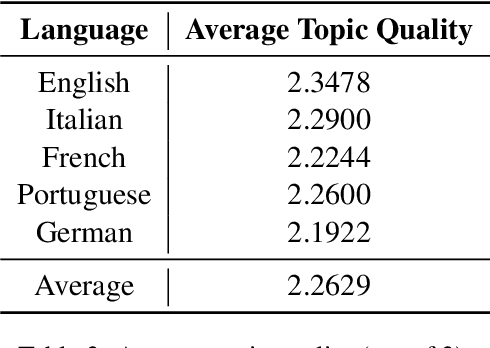
Many data sets in a domain (reviews, forums, news, etc.) exist in parallel languages. They all cover the same content, but the linguistic differences make it impossible to use traditional, bag-of-word-based topic models. Models have to be either single-language or suffer from a huge, but extremely sparse vocabulary. Both issues can be addressed by transfer learning. In this paper, we introduce a zero-shot cross-lingual topic model, i.e., our model learns topics on one language (here, English), and predicts them for documents in other languages. By using the text of the same document in different languages, we can evaluate the quality of the predictions. Our results show that topics are coherent and stable across languages, which suggests exciting future research directions.
Named entity recognition using conditional random fields with non-local relational constraints
Oct 07, 2013We begin by introducing the Computer Science branch of Natural Language Processing, then narrowing the attention on its subbranch of Information Extraction and particularly on Named Entity Recognition, discussing briefly its main methodological approaches. It follows an introduction to state-of-the-art Conditional Random Fields under the form of linear chains. Subsequently, the idea of constrained inference as a way to model long-distance relationships in a text is presented, based on an Integer Linear Programming representation of the problem. Adding such relationships to the problem as automatically inferred logical formulas, translatable into linear conditions, we propose to solve the resulting more complex problem with the aid of Lagrangian relaxation, of which some technical details are explained. Lastly, we give some experimental results.