 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSER_AMPEL: A multi-source dataset for SER of Italian older adults
Nov 24, 2023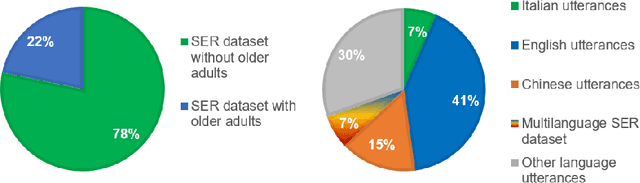



In this paper, SER_AMPEL, a multi-source dataset for speech emotion recognition (SER) is presented. The peculiarity of the dataset is that it is collected with the aim of providing a reference for speech emotion recognition in case of Italian older adults. The dataset is collected following different protocols, in particular considering acted conversations, extracted from movies and TV series, and recording natural conversations where the emotions are elicited by proper questions. The evidence of the need for such a dataset emerges from the analysis of the state of the art. Preliminary considerations on the critical issues of SER are reported analyzing the classification results on a subset of the proposed dataset.
A multi-artifact EEG denoising by frequency-based deep learning
Oct 26, 2023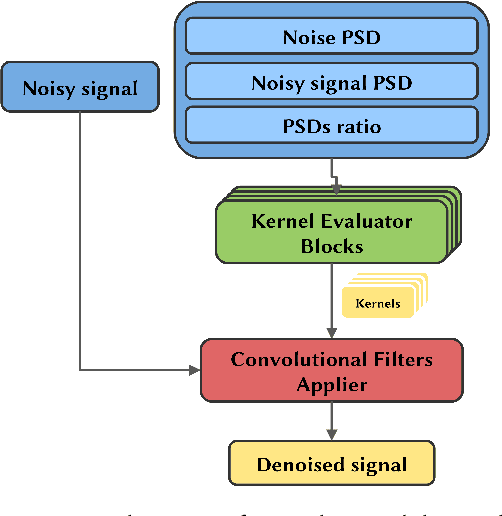
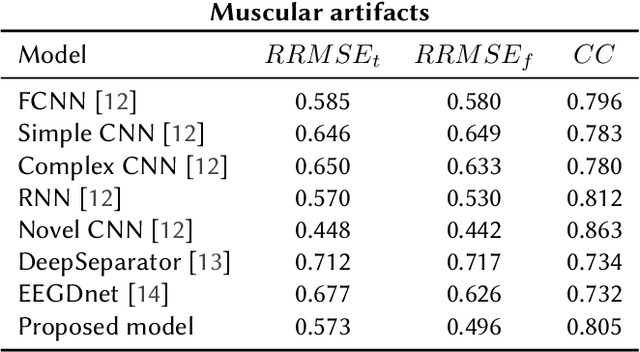
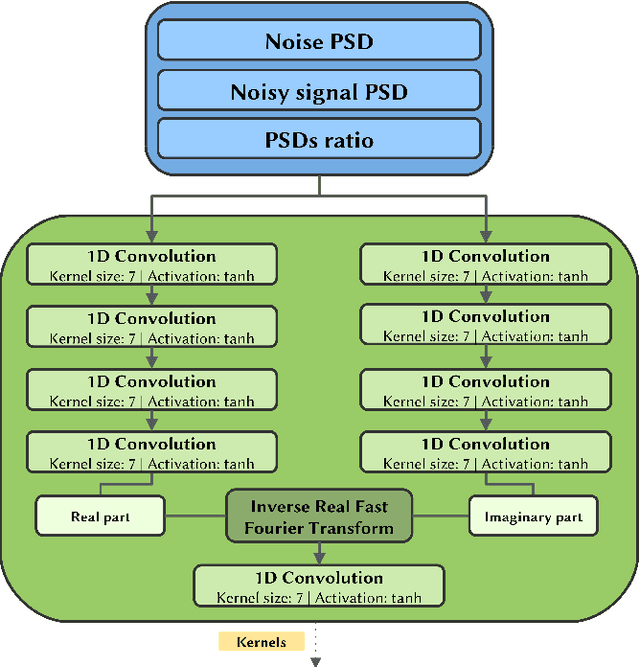
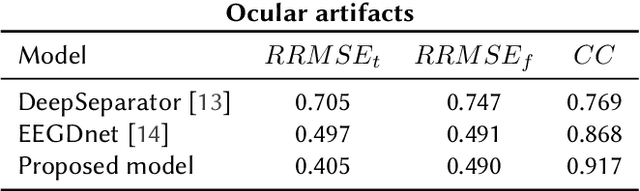
Electroencephalographic (EEG) signals are fundamental to neuroscience research and clinical applications such as brain-computer interfaces and neurological disorder diagnosis. These signals are typically a combination of neurological activity and noise, originating from various sources, including physiological artifacts like ocular and muscular movements. Under this setting, we tackle the challenge of distinguishing neurological activity from noise-related sources. We develop a novel EEG denoising model that operates in the frequency domain, leveraging prior knowledge about noise spectral features to adaptively compute optimal convolutional filters for noise separation. The model is trained to learn an empirical relationship connecting the spectral characteristics of noise and noisy signal to a non-linear transformation which allows signal denoising. Performance evaluation on the EEGdenoiseNet dataset shows that the proposed model achieves optimal results according to both temporal and spectral metrics. The model is found to remove physiological artifacts from input EEG data, thus achieving effective EEG denoising. Indeed, the model performance either matches or outperforms that achieved by benchmark models, proving to effectively remove both muscle and ocular artifacts without the need to perform any training on the particular type of artifact.
Sentiment recognition of Italian elderly through domain adaptation on cross-corpus speech dataset
Nov 14, 2022The aim of this work is to define a speech emotion recognition (SER) model able to recognize positive, neutral and negative emotions in natural conversations of Italian elderly people. Several datasets for SER are available in the literature. However most of them are in English or Chinese, have been recorded while actors and actresses pronounce short phrases and thus are not related to natural conversation. Moreover only few speeches among all the databases are related to elderly people. Therefore, in this work, a multi-language and multi-age corpus is considered merging a dataset in English, that includes also elderly people, with a dataset in Italian. A general model, trained on young and adult English actors and actresses is proposed, based on XGBoost. Then two strategies of domain adaptation are proposed to adapt the model either to elderly people and to Italian speakers. The results suggest that this approach increases the classification performance, underlining also that new datasets should be collected.
The evolution of AI approaches for motor imagery EEG-based BCIs
Oct 11, 2022

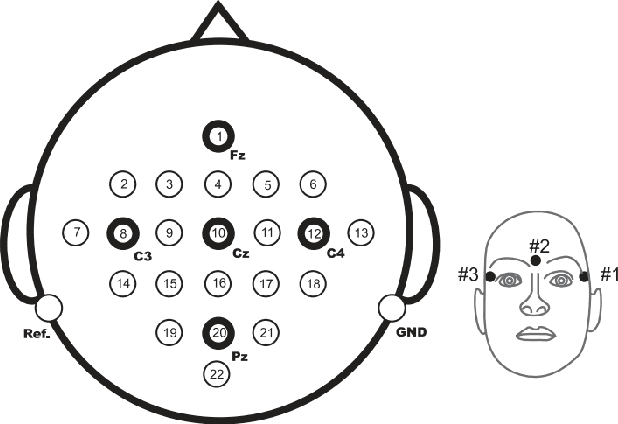

The Motor Imagery (MI) electroencephalography (EEG) based Brain Computer Interfaces (BCIs) allow the direct communication between humans and machines by exploiting the neural pathways connected to motor imagination. Therefore, these systems open the possibility of developing applications that could span from the medical field to the entertainment industry. In this context, Artificial Intelligence (AI) approaches become of fundamental importance especially when wanting to provide a correct and coherent feedback to BCI users. Moreover, publicly available datasets in the field of MI EEG-based BCIs have been widely exploited to test new techniques from the AI domain. In this work, AI approaches applied to datasets collected in different years and with different devices but with coherent experimental paradigms are investigated with the aim of providing a concise yet sufficiently comprehensive survey on the evolution and influence of AI techniques on MI EEG-based BCI data.
Personalized PPG Normalization based on Subject Heartbeat in Resting State Condition
Feb 23, 2022


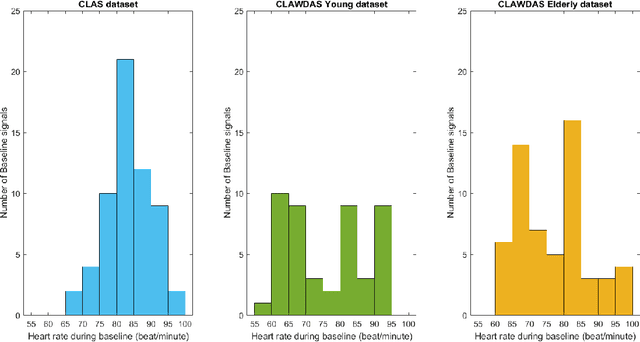
Physiological responses are nowadays widely used to recognize the affective state of subjects in real-life scenarios. However, these data are intrinsically subject-dependent, making machine learning techniques for data classification not easily applicable due to inter-subject variability. In this work, the reduction of inter-subject heterogeneity is considered in the case of PhotoPlethysmoGraphy (PPG), which is successfully used to detect stress and evaluate experienced cognitive load. To face the inter-subject heterogeneity, a novel personalized PPG normalization is here proposed. A subject-normalized discrete domain where the PPG signals are properly re-scaled is introduced, considering the subject's heartbeat frequency in resting state conditions. The effectiveness of the proposed normalization is evaluated in comparison with other normalization procedures in a binary classification task, where cognitive load and relaxing state are considered. The results obtained on two different datasets available in the literature confirm that applying the proposed normalization strategy permits to increase classification performance.
Novel EEG-based BCIs for Elderly Rehabilitation Enhancement
Oct 08, 2021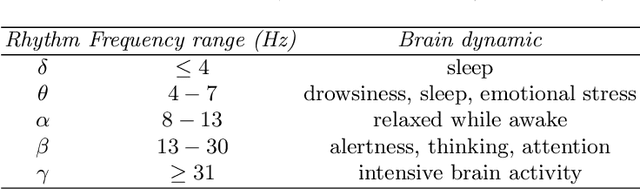
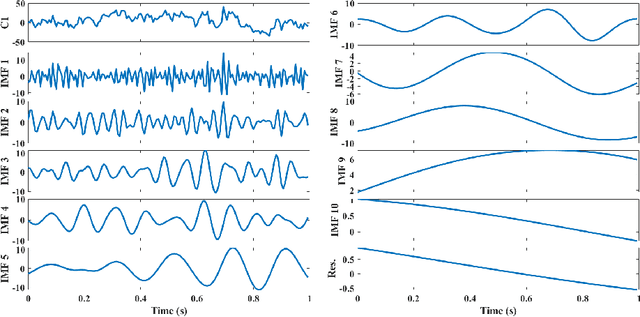
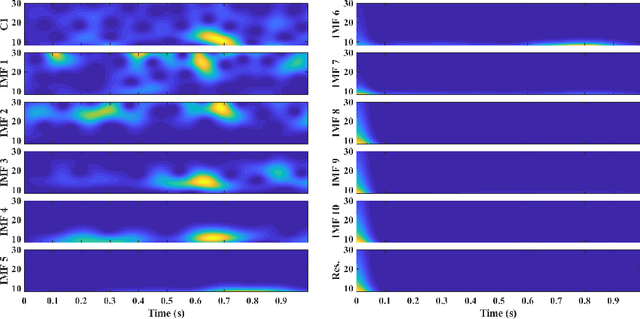

The ageing process may lead to cognitive and physical impairments, which may affect elderly everyday life. In recent years, the use of Brain Computer Interfaces (BCIs) based on Electroencephalography (EEG) has revealed to be particularly effective to promote and enhance rehabilitation procedures, especially by exploiting motor imagery experimental paradigms. Moreover, BCIs seem to increase patients' engagement and have proved to be reliable tools for elderly overall wellness improvement. However, EEG signals usually present a low signal-to-noise ratio and can be recorded for a limited time. Thus, irrelevant information and faulty samples could affect the BCI performance. Introducing a methodology that allows the extraction of informative components from the EEG signal while maintaining its intrinsic characteristics, may provide a solution to both the described issues: noisy data may be avoided by having only relevant components and combining relevant components may represent a good strategy to substitute the data without requiring long or repeated EEG recordings. Moreover, substituting faulty trials may significantly improve the classification performances of a BCI when translating imagined movement to rehabilitation systems. To this end, in this work the EEG signal decomposition by means of multivariate empirical mode decomposition is proposed to obtain its oscillatory modes, called Intrinsic Mode Functions (IMFs). Subsequently, a novel procedure for relevant IMF selection criterion based on the IMF time-frequency representation and entropy is provided. After having verified the reliability of the EEG signal reconstruction with the relevant IMFs only, the relevant IMFs are combined to produce new artificial data and provide new samples to use for BCI training.
Benchmark dataset of memes with text transcriptions for automatic detection of multi-modal misogynistic content
Jun 15, 2021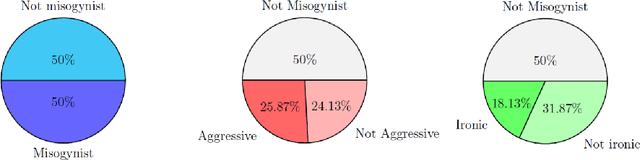
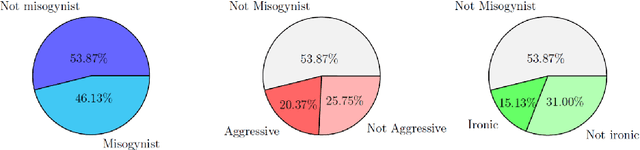

In this paper we present a benchmark dataset generated as part of a project for automatic identification of misogyny within online content, which focuses in particular on memes. The benchmark here described is composed of 800 memes collected from the most popular social media platforms, such as Facebook, Twitter, Instagram and Reddit, and consulting websites dedicated to collection and creation of memes. To gather misogynistic memes, specific keywords that refer to misogynistic content have been considered as search criterion, considering different manifestations of hatred against women, such as body shaming, stereotyping, objectification and violence. In parallel, memes with no misogynist content have been manually downloaded from the same web sources. Among all the collected memes, three domain experts have selected a dataset of 800 memes equally balanced between misogynistic and non-misogynistic ones. This dataset has been validated through a crowdsourcing platform, involving 60 subjects for the labelling process, in order to collect three evaluations for each instance. Two further binary labels have been collected from both the experts and the crowdsourcing platform, for memes evaluated as misogynistic, concerning aggressiveness and irony. Finally for each meme, the text has been manually transcribed. The dataset provided is thus composed of the 800 memes, the labels given by the experts and those obtained by the crowdsourcing validation, and the transcribed texts. This data can be used to approach the problem of automatic detection of misogynistic content on the Web relying on both textual and visual cues, facing phenomenons that are growing every day such as cybersexism and technology-facilitated violence.
GA for feature selection of EEG heterogeneous data
Mar 12, 2021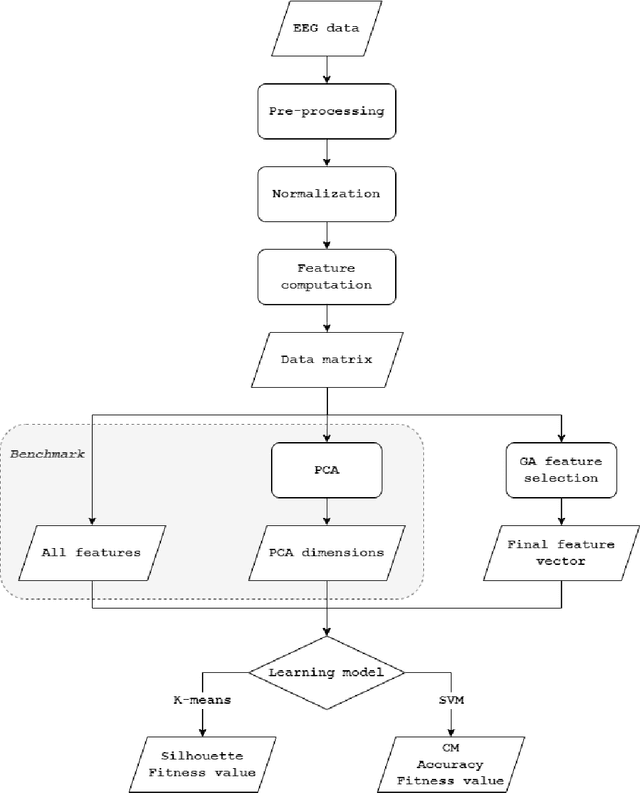
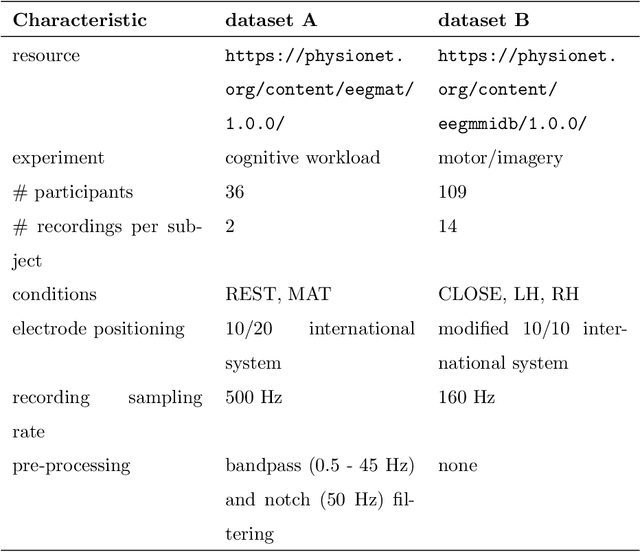
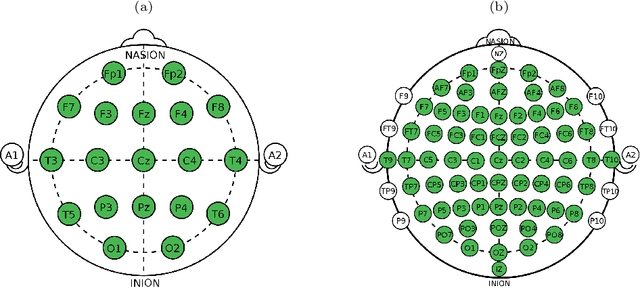
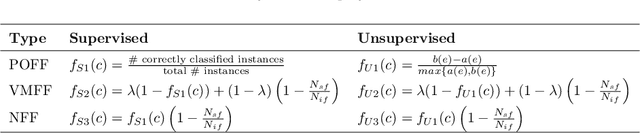
The electroencephalographic (EEG) signals provide highly informative data on brain activities and functions. However, their heterogeneity and high dimensionality may represent an obstacle for their interpretation. The introduction of a priori knowledge seems the best option to mitigate high dimensionality problems, but could lose some information and patterns present in the data, while data heterogeneity remains an open issue that often makes generalization difficult. In this study, we propose a genetic algorithm (GA) for feature selection that can be used with a supervised or unsupervised approach. Our proposal considers three different fitness functions without relying on expert knowledge. Starting from two publicly available datasets on cognitive workload and motor movement/imagery, the EEG signals are processed, normalized and their features computed in the time, frequency and time-frequency domains. The feature vector selection is performed by applying our GA proposal and compared with two benchmarking techniques. The results show that different combinations of our proposal achieve better results in respect to the benchmark in terms of overall performance and feature reduction. Moreover, the proposed GA, based on a novel fitness function here presented, outperforms the benchmark when the two different datasets considered are merged together, showing the effectiveness of our proposal on heterogeneous data.