 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSER_AMPEL: A multi-source dataset for SER of Italian older adults
Nov 24, 2023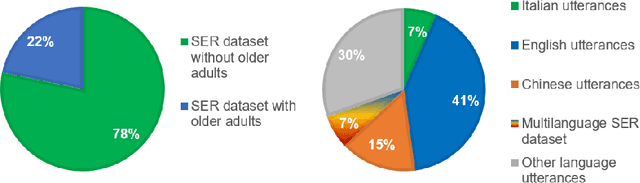



In this paper, SER_AMPEL, a multi-source dataset for speech emotion recognition (SER) is presented. The peculiarity of the dataset is that it is collected with the aim of providing a reference for speech emotion recognition in case of Italian older adults. The dataset is collected following different protocols, in particular considering acted conversations, extracted from movies and TV series, and recording natural conversations where the emotions are elicited by proper questions. The evidence of the need for such a dataset emerges from the analysis of the state of the art. Preliminary considerations on the critical issues of SER are reported analyzing the classification results on a subset of the proposed dataset.
Sentiment recognition of Italian elderly through domain adaptation on cross-corpus speech dataset
Nov 14, 2022The aim of this work is to define a speech emotion recognition (SER) model able to recognize positive, neutral and negative emotions in natural conversations of Italian elderly people. Several datasets for SER are available in the literature. However most of them are in English or Chinese, have been recorded while actors and actresses pronounce short phrases and thus are not related to natural conversation. Moreover only few speeches among all the databases are related to elderly people. Therefore, in this work, a multi-language and multi-age corpus is considered merging a dataset in English, that includes also elderly people, with a dataset in Italian. A general model, trained on young and adult English actors and actresses is proposed, based on XGBoost. Then two strategies of domain adaptation are proposed to adapt the model either to elderly people and to Italian speakers. The results suggest that this approach increases the classification performance, underlining also that new datasets should be collected.
Personalized PPG Normalization based on Subject Heartbeat in Resting State Condition
Feb 23, 2022


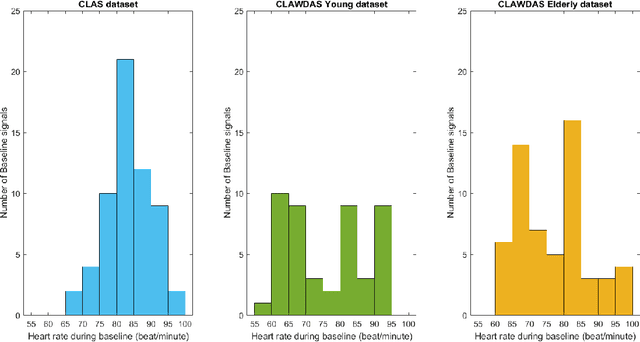
Physiological responses are nowadays widely used to recognize the affective state of subjects in real-life scenarios. However, these data are intrinsically subject-dependent, making machine learning techniques for data classification not easily applicable due to inter-subject variability. In this work, the reduction of inter-subject heterogeneity is considered in the case of PhotoPlethysmoGraphy (PPG), which is successfully used to detect stress and evaluate experienced cognitive load. To face the inter-subject heterogeneity, a novel personalized PPG normalization is here proposed. A subject-normalized discrete domain where the PPG signals are properly re-scaled is introduced, considering the subject's heartbeat frequency in resting state conditions. The effectiveness of the proposed normalization is evaluated in comparison with other normalization procedures in a binary classification task, where cognitive load and relaxing state are considered. The results obtained on two different datasets available in the literature confirm that applying the proposed normalization strategy permits to increase classification performance.