 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-UPV at EXIST 2023 -- Sexism Characterization Using Large Language Models Under The Learning with Disagreements Regime
Jul 07, 2023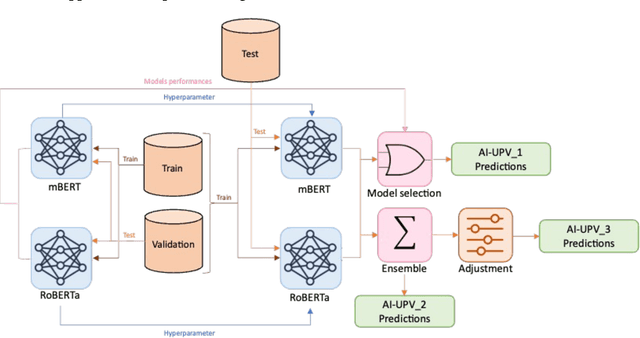
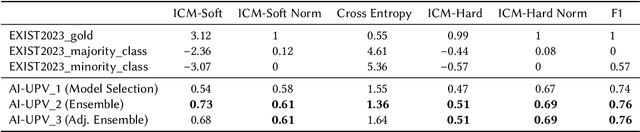
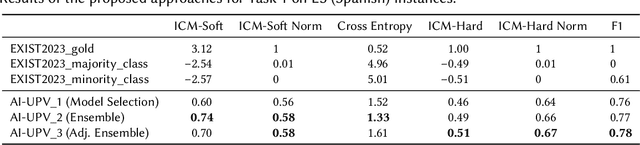
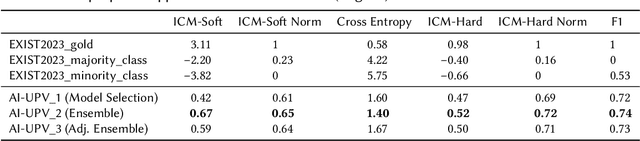
With the increasing influence of social media platforms, it has become crucial to develop automated systems capable of detecting instances of sexism and other disrespectful and hateful behaviors to promote a more inclusive and respectful online environment. Nevertheless, these tasks are considerably challenging considering different hate categories and the author's intentions, especially under the learning with disagreements regime. This paper describes AI-UPV team's participation in the EXIST (sEXism Identification in Social neTworks) Lab at CLEF 2023. The proposed approach aims at addressing the task of sexism identification and characterization under the learning with disagreements paradigm by training directly from the data with disagreements, without using any aggregated label. Yet, performances considering both soft and hard evaluations are reported. The proposed system uses large language models (i.e., mBERT and XLM-RoBERTa) and ensemble strategies for sexism identification and classification in English and Spanish. In particular, our system is articulated in three different pipelines. The ensemble approach outperformed the individual large language models obtaining the best performances both adopting a soft and a hard label evaluation. This work describes the participation in all the three EXIST tasks, considering a soft evaluation, it obtained fourth place in Task 2 at EXIST and first place in Task 3, with the highest ICM-Soft of -2.32 and a normalized ICM-Soft of 0.79. The source code of our approaches is publicly available at https://github.com/AngelFelipeMP/Sexism-LLM-Learning-With-Disagreement.
Benchmark dataset of memes with text transcriptions for automatic detection of multi-modal misogynistic content
Jun 15, 2021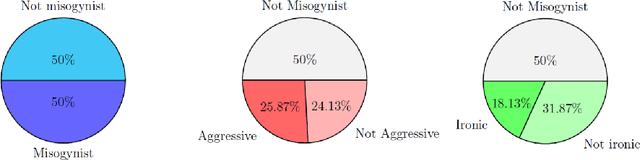
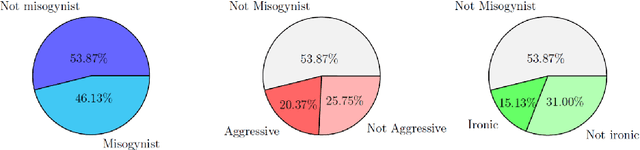

In this paper we present a benchmark dataset generated as part of a project for automatic identification of misogyny within online content, which focuses in particular on memes. The benchmark here described is composed of 800 memes collected from the most popular social media platforms, such as Facebook, Twitter, Instagram and Reddit, and consulting websites dedicated to collection and creation of memes. To gather misogynistic memes, specific keywords that refer to misogynistic content have been considered as search criterion, considering different manifestations of hatred against women, such as body shaming, stereotyping, objectification and violence. In parallel, memes with no misogynist content have been manually downloaded from the same web sources. Among all the collected memes, three domain experts have selected a dataset of 800 memes equally balanced between misogynistic and non-misogynistic ones. This dataset has been validated through a crowdsourcing platform, involving 60 subjects for the labelling process, in order to collect three evaluations for each instance. Two further binary labels have been collected from both the experts and the crowdsourcing platform, for memes evaluated as misogynistic, concerning aggressiveness and irony. Finally for each meme, the text has been manually transcribed. The dataset provided is thus composed of the 800 memes, the labels given by the experts and those obtained by the crowdsourcing validation, and the transcribed texts. This data can be used to approach the problem of automatic detection of misogynistic content on the Web relying on both textual and visual cues, facing phenomenons that are growing every day such as cybersexism and technology-facilitated violence.