 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMIT-ADM+S at the MMU-RAG NeurIPS 2025 Competition
Feb 24, 2026This paper presents the award-winning RMIT-ADM+S system for the Text-to-Text track of the NeurIPS~2025 MMU-RAG Competition. We introduce Routing-to-RAG (R2RAG), a research-focused retrieval-augmented generation (RAG) architecture composed of lightweight components that dynamically adapt the retrieval strategy based on inferred query complexity and evidence sufficiency. The system uses smaller LLMs, enabling operation on a single consumer-grade GPU while supporting complex research tasks. It builds on the G-RAG system, winner of the ACM~SIGIR~2025 LiveRAG Challenge, and extends it with modules informed by qualitative review of outputs. R2RAG won the Best Dynamic Evaluation award in the Open Source category, demonstrating high effectiveness with careful design and efficient use of resources.
Characterizing Personality from Eye-Tracking: The Role of Gaze and Its Absence in Interactive Search Environments
Jan 13, 2026Personality traits influence how individuals engage, behave, and make decisions during the information-seeking process. However, few studies have linked personality to observable search behaviors. This study aims to characterize personality traits through a multimodal time-series model that integrates eye-tracking data and gaze missingness-periods when the user's gaze is not captured. This approach is based on the idea that people often look away when they think, signaling disengagement or reflection. We conducted a user study with 25 participants, who used an interactive application on an iPad, allowing them to engage with digital artifacts from a museum. We rely on raw gaze data from an eye tracker, minimizing preprocessing so that behavioral patterns can be preserved without substantial data cleaning. From this perspective, we trained models to predict personality traits using gaze signals. Our results from a five-fold cross-validation study demonstrate strong predictive performance across all five dimensions: Neuroticism (Macro F1 = 77.69%), Conscientiousness (74.52%), Openness (77.52%), Agreeableness (73.09%), and Extraversion (76.69%). The ablation study examines whether the absence of gaze information affects the model performance, demonstrating that incorporating missingness improves multimodal time-series modeling. The full model, which integrates both time-series signals and missingness information, achieves 10-15% higher accuracy and macro F1 scores across all Big Five traits compared to the model without time-series signals and missingness. These findings provide evidence that personality can be inferred from search-related gaze behavior and demonstrate the value of incorporating missing gaze data into time-series multimodal modeling.
RMIT-ADM+S at the SIGIR 2025 LiveRAG Challenge
Jun 17, 2025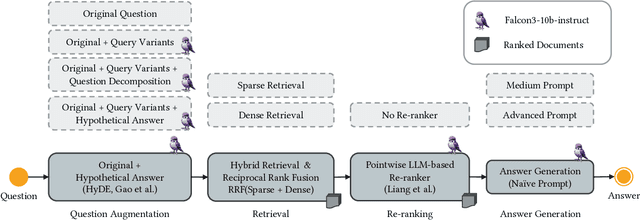
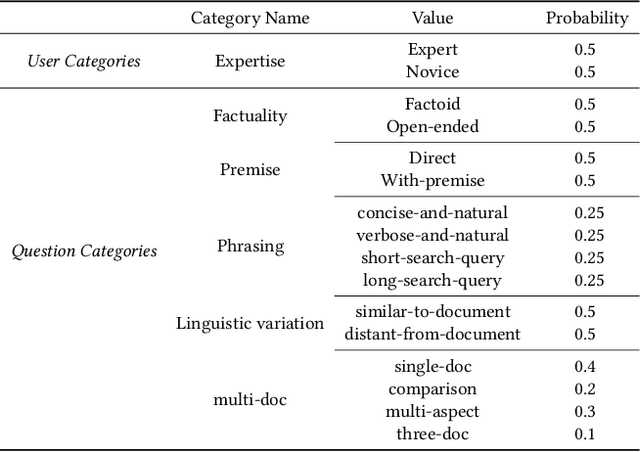


This paper presents the RMIT--ADM+S participation in the SIGIR 2025 LiveRAG Challenge. Our Generation-Retrieval-Augmented Generation (GRAG) approach relies on generating a hypothetical answer that is used in the retrieval phase, alongside the original question. GRAG also incorporates a pointwise large language model (LLM)-based re-ranking step prior to final answer generation. We describe the system architecture and the rationale behind our design choices. In particular, a systematic evaluation using the Grid of Points (GoP) framework and N-way ANOVA enabled comparison across multiple configurations, including query variant generation, question decomposition, rank fusion strategies, and prompting techniques for answer generation. Our system achieved a Relevance score of 1.199 and a Faithfulness score of 0.477 on the private leaderboard, placing among the top four finalists in the LiveRAG 2025 Challenge.
Characterising Topic Familiarity and Query Specificity Using Eye-Tracking Data
May 06, 2025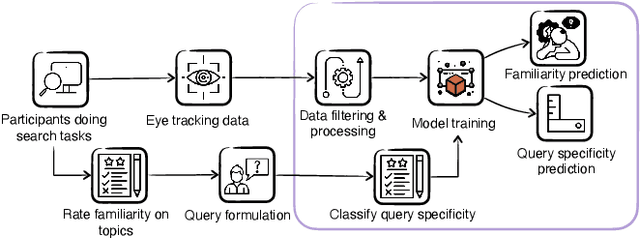


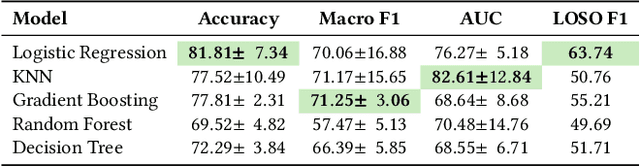
Eye-tracking data has been shown to correlate with a user's knowledge level and query formulation behaviour. While previous work has focused primarily on eye gaze fixations for attention analysis, often requiring additional contextual information, our study investigates the memory-related cognitive dimension by relying solely on pupil dilation and gaze velocity to infer users' topic familiarity and query specificity without needing any contextual information. Using eye-tracking data collected via a lab user study (N=18), we achieved a Macro F1 score of 71.25% for predicting topic familiarity with a Gradient Boosting classifier, and a Macro F1 score of 60.54% with a k-nearest neighbours (KNN) classifier for query specificity. Furthermore, we developed a novel annotation guideline -- specifically tailored for question answering -- to manually classify queries as Specific or Non-specific. This study demonstrates the feasibility of eye-tracking to better understand topic familiarity and query specificity in search.
Information Retrieval for Climate Impact
Apr 01, 2025The purpose of the MANILA24 Workshop on information retrieval for climate impact was to bring together researchers from academia, industry, governments, and NGOs to identify and discuss core research problems in information retrieval to assess climate change impacts. The workshop aimed to foster collaboration by bringing communities together that have so far not been very well connected -- information retrieval, natural language processing, systematic reviews, impact assessments, and climate science. The workshop brought together a diverse set of researchers and practitioners interested in contributing to the development of a technical research agenda for information retrieval to assess climate change impacts.
Control Search Rankings, Control the World: What is a Good Search Engine?
Feb 05, 2025
This paper examines the ethical question, 'What is a good search engine?' Since search engines are gatekeepers of global online information, it is vital they do their job ethically well. While the Internet is now several decades old, the topic remains under-explored from interdisciplinary perspectives. This paper presents a novel role-based approach involving four ethical models of types of search engine behavior: Customer Servant, Librarian, Journalist, and Teacher. It explores these ethical models with reference to the research field of information retrieval, and by means of a case study involving the COVID-19 global pandemic. It also reflects on the four ethical models in terms of the history of search engine development, from earlier crude efforts in the 1990s, to the very recent prospect of Large Language Model-based conversational information seeking systems taking on the roles of established web search engines like Google. Finally, the paper outlines considerations that inform present and future regulation and accountability for search engines as they continue to evolve. The paper should interest information retrieval researchers and others interested in the ethics of search engines.
Can Users Detect Biases or Factual Errors in Generated Responses in Conversational Information-Seeking?
Oct 28, 2024
Information-seeking dialogues span a wide range of questions, from simple factoid to complex queries that require exploring multiple facets and viewpoints. When performing exploratory searches in unfamiliar domains, users may lack background knowledge and struggle to verify the system-provided information, making them vulnerable to misinformation. We investigate the limitations of response generation in conversational information-seeking systems, highlighting potential inaccuracies, pitfalls, and biases in the responses. The study addresses the problem of query answerability and the challenge of response incompleteness. Our user studies explore how these issues impact user experience, focusing on users' ability to identify biased, incorrect, or incomplete responses. We design two crowdsourcing tasks to assess user experience with different system response variants, highlighting critical issues to be addressed in future conversational information-seeking research. Our analysis reveals that it is easier for users to detect response incompleteness than query answerability and user satisfaction is mostly associated with response diversity, not factual correctness.
Towards Investigating Biases in Spoken Conversational Search
Sep 02, 2024


Voice-based systems like Amazon Alexa, Google Assistant, and Apple Siri, along with the growing popularity of OpenAI's ChatGPT and Microsoft's Copilot, serve diverse populations, including visually impaired and low-literacy communities. This reflects a shift in user expectations from traditional search to more interactive question-answering models. However, presenting information effectively in voice-only channels remains challenging due to their linear nature. This limitation can impact the presentation of complex queries involving controversial topics with multiple perspectives. Failing to present diverse viewpoints may perpetuate or introduce biases and affect user attitudes. Balancing information load and addressing biases is crucial in designing a fair and effective voice-based system. To address this, we (i) review how biases and user attitude changes have been studied in screen-based web search, (ii) address challenges in studying these changes in voice-based settings like SCS, (iii) outline research questions, and (iv) propose an experimental setup with variables, data, and instruments to explore biases in a voice-based setting like Spoken Conversational Search.
Towards Detecting and Mitigating Cognitive Bias in Spoken Conversational Search
May 21, 2024Instruments such as eye-tracking devices have contributed to understanding how users interact with screen-based search engines. However, user-system interactions in audio-only channels -- as is the case for Spoken Conversational Search (SCS) -- are harder to characterize, given the lack of instruments to effectively and precisely capture interactions. Furthermore, in this era of information overload, cognitive bias can significantly impact how we seek and consume information -- especially in the context of controversial topics or multiple viewpoints. This paper draws upon insights from multiple disciplines (including information seeking, psychology, cognitive science, and wearable sensors) to provoke novel conversations in the community. To this end, we discuss future opportunities and propose a framework including multimodal instruments and methods for experimental designs and settings. We demonstrate preliminary results as an example. We also outline the challenges and offer suggestions for adopting this multimodal approach, including ethical considerations, to assist future researchers and practitioners in exploring cognitive biases in SCS.
Explainability for Transparent Conversational Information-Seeking
May 06, 2024

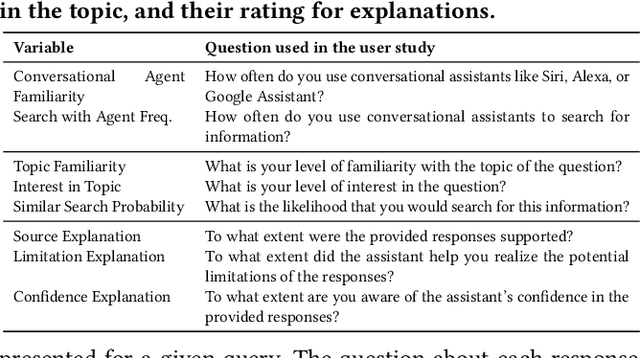
The increasing reliance on digital information necessitates advancements in conversational search systems, particularly in terms of information transparency. While prior research in conversational information-seeking has concentrated on improving retrieval techniques, the challenge remains in generating responses useful from a user perspective. This study explores different methods of explaining the responses, hypothesizing that transparency about the source of the information, system confidence, and limitations can enhance users' ability to objectively assess the response. By exploring transparency across explanation type, quality, and presentation mode, this research aims to bridge the gap between system-generated responses and responses verifiable by the user. We design a user study to answer questions concerning the impact of (1) the quality of explanations enhancing the response on its usefulness and (2) ways of presenting explanations to users. The analysis of the collected data reveals lower user ratings for noisy explanations, although these scores seem insensitive to the quality of the response. Inconclusive results on the explanations presentation format suggest that it may not be a critical factor in this setting.