 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADIUS: Ranking, Distribution, and Significance - A Comprehensive Alignment Suite for Survey Simulation
Mar 19, 2026Simulation of surveys using LLMs is emerging as a powerful application for generating human-like responses at scale. Prior work evaluates survey simulation using metrics borrowed from other domains, which are often ad hoc, fragmented, and non-standardized, leading to results that are difficult to compare. Moreover, existing metrics focus mainly on accuracy or distributional measures, overlooking the critical dimension of ranking alignment. In practice, a simulation can achieve high accuracy while still failing to capture the option most preferred by humans - a distinction that is critical in decision-making applications. We introduce RADIUS, a comprehensive two-dimensional alignment suite for survey simulation that captures: 1) RAnking alignment and 2) DIstribUtion alignment, each complemented by statistical Significance testing. RADIUS highlights the limitations of existing metrics, enables more meaningful evaluation of survey simulation, and provides an open-source implementation for reproducible and comparable assessment.
Trust Me on This: A User Study of Trustworthiness for RAG Responses
Jan 20, 2026The integration of generative AI into information access systems often presents users with synthesized answers that lack transparency. This study investigates how different types of explanations can influence user trust in responses from retrieval-augmented generation systems. We conducted a controlled, two-stage user study where participants chose the more trustworthy response from a pair-one objectively higher quality than the other-both with and without one of three explanation types: (1) source attribution, (2) factual grounding, and (3) information coverage. Our results show that while explanations significantly guide users toward selecting higher quality responses, trust is not dictated by objective quality alone: Users' judgments are also heavily influenced by response clarity, actionability, and their own prior knowledge.
Can Users Detect Biases or Factual Errors in Generated Responses in Conversational Information-Seeking?
Oct 28, 2024
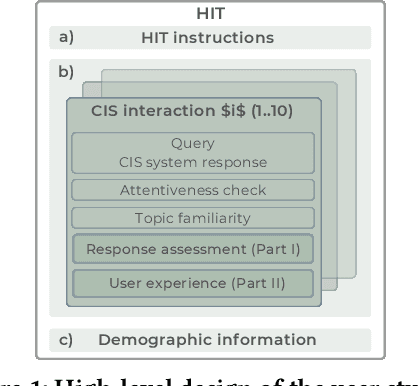
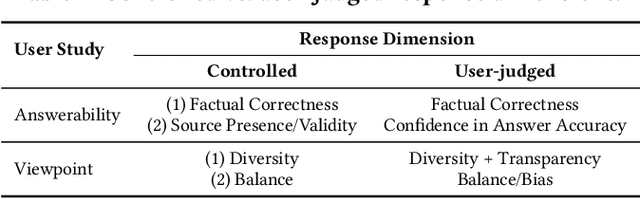
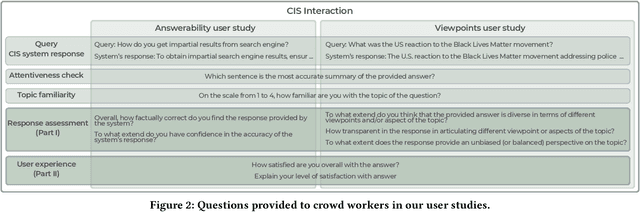
Information-seeking dialogues span a wide range of questions, from simple factoid to complex queries that require exploring multiple facets and viewpoints. When performing exploratory searches in unfamiliar domains, users may lack background knowledge and struggle to verify the system-provided information, making them vulnerable to misinformation. We investigate the limitations of response generation in conversational information-seeking systems, highlighting potential inaccuracies, pitfalls, and biases in the responses. The study addresses the problem of query answerability and the challenge of response incompleteness. Our user studies explore how these issues impact user experience, focusing on users' ability to identify biased, incorrect, or incomplete responses. We design two crowdsourcing tasks to assess user experience with different system response variants, highlighting critical issues to be addressed in future conversational information-seeking research. Our analysis reveals that it is easier for users to detect response incompleteness than query answerability and user satisfaction is mostly associated with response diversity, not factual correctness.
Grounded and Transparent Response Generation for Conversational Information-Seeking Systems
Jun 27, 2024
While previous conversational information-seeking (CIS) research has focused on passage retrieval, reranking, and query rewriting, the challenge of synthesizing retrieved information into coherent responses remains. The proposed research delves into the intricacies of response generation in CIS systems. Open-ended information-seeking dialogues introduce multiple challenges that may lead to potential pitfalls in system responses. The study focuses on generating responses grounded in the retrieved passages and being transparent about the system's limitations. Specific research questions revolve around obtaining confidence-enriched information nuggets, automatic detection of incomplete or incorrect responses, generating responses communicating the system's limitations, and evaluating enhanced responses. By addressing these research tasks the study aspires to contribute to the advancement of conversational response generation, fostering more trustworthy interactions in CIS dialogues, and paving the way for grounded and transparent systems to meet users' needs in an information-driven world.
Explainability for Transparent Conversational Information-Seeking
May 06, 2024
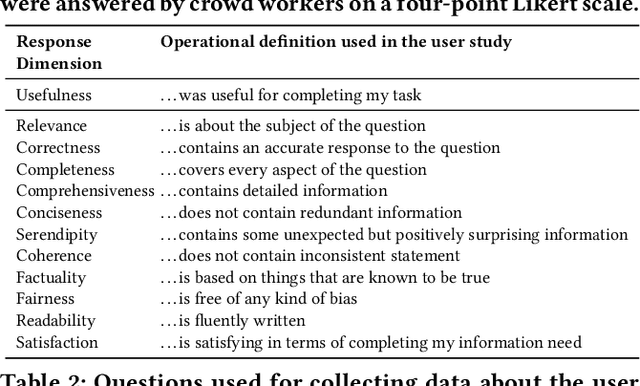

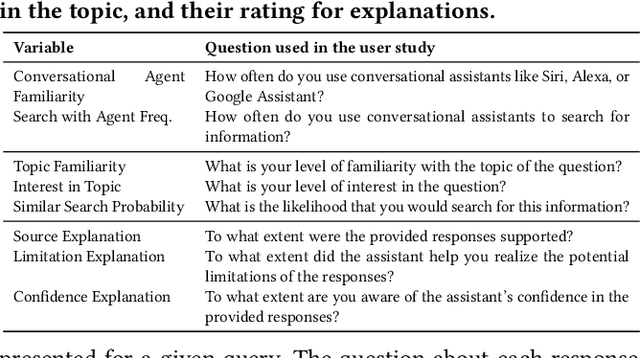
The increasing reliance on digital information necessitates advancements in conversational search systems, particularly in terms of information transparency. While prior research in conversational information-seeking has concentrated on improving retrieval techniques, the challenge remains in generating responses useful from a user perspective. This study explores different methods of explaining the responses, hypothesizing that transparency about the source of the information, system confidence, and limitations can enhance users' ability to objectively assess the response. By exploring transparency across explanation type, quality, and presentation mode, this research aims to bridge the gap between system-generated responses and responses verifiable by the user. We design a user study to answer questions concerning the impact of (1) the quality of explanations enhancing the response on its usefulness and (2) ways of presenting explanations to users. The analysis of the collected data reveals lower user ratings for noisy explanations, although these scores seem insensitive to the quality of the response. Inconclusive results on the explanations presentation format suggest that it may not be a critical factor in this setting.
PKG API: A Tool for Personal Knowledge Graph Management
Feb 12, 2024


Personal knowledge graphs (PKGs) offer individuals a way to store and consolidate their fragmented personal data in a central place, improving service personalization while maintaining full user control. Despite their potential, practical PKG implementations with user-friendly interfaces remain scarce. This work addresses this gap by proposing a complete solution to represent, manage, and interface with PKGs. Our approach includes (1) a user-facing PKG Client, enabling end-users to administer their personal data easily via natural language statements, and (2) a service-oriented PKG API. To tackle the complexity of representing these statements within a PKG, we present an RDF-based PKG vocabulary that supports this, along with properties for access rights and provenance.
Estimating the Usefulness of Clarifying Questions and Answers for Conversational Search
Jan 21, 2024While the body of research directed towards constructing and generating clarifying questions in mixed-initiative conversational search systems is vast, research aimed at processing and comprehending users' answers to such questions is scarce. To this end, we present a simple yet effective method for processing answers to clarifying questions, moving away from previous work that simply appends answers to the original query and thus potentially degrades retrieval performance. Specifically, we propose a classifier for assessing usefulness of the prompted clarifying question and an answer given by the user. Useful questions or answers are further appended to the conversation history and passed to a transformer-based query rewriting module. Results demonstrate significant improvements over strong non-mixed-initiative baselines. Furthermore, the proposed approach mitigates the performance drops when non useful questions and answers are utilized.
Towards Reliable and Factual Response Generation: Detecting Unanswerable Questions in Information-Seeking Conversations
Jan 21, 2024


Generative AI models face the challenge of hallucinations that can undermine users' trust in such systems. We approach the problem of conversational information seeking as a two-step process, where relevant passages in a corpus are identified first and then summarized into a final system response. This way we can automatically assess if the answer to the user's question is present in the corpus. Specifically, our proposed method employs a sentence-level classifier to detect if the answer is present, then aggregates these predictions on the passage level, and eventually across the top-ranked passages to arrive at a final answerability estimate. For training and evaluation, we develop a dataset based on the TREC CAsT benchmark that includes answerability labels on the sentence, passage, and ranking levels. We demonstrate that our proposed method represents a strong baseline and outperforms a state-of-the-art LLM on the answerability prediction task.
Towards Filling the Gap in Conversational Search: From Passage Retrieval to Conversational Response Generation
Aug 17, 2023Research on conversational search has so far mostly focused on query rewriting and multi-stage passage retrieval. However, synthesizing the top retrieved passages into a complete, relevant, and concise response is still an open challenge. Having snippet-level annotations of relevant passages would enable both (1) the training of response generation models that are able to ground answers in actual statements and (2) the automatic evaluation of the generated responses in terms of completeness. In this paper, we address the problem of collecting high-quality snippet-level answer annotations for two of the TREC Conversational Assistance track datasets. To ensure quality, we first perform a preliminary annotation study, employing different task designs, crowdsourcing platforms, and workers with different qualifications. Based on the outcomes of this study, we refine our annotation protocol before proceeding with the full-scale data collection. Overall, we gather annotations for 1.8k question-paragraph pairs, each annotated by three independent crowd workers. The process of collecting data at this magnitude also led to multiple insights about the problem that can inform the design of future response-generation methods. This is an extended version of the article published with the same title in the Proceedings of CIKM'23.
Protagonists' Tagger in Literary Domain -- New Datasets and a Method for Person Entity Linkage
Oct 04, 2021



Semantic annotation of long texts, such as novels, remains an open challenge in Natural Language Processing (NLP). This research investigates the problem of detecting person entities and assigning them unique identities, i.e., recognizing people (especially main characters) in novels. We prepared a method for person entity linkage (named entity recognition and disambiguation) and new testing datasets. The datasets comprise 1,300 sentences from 13 classic novels of different genres that a novel reader had manually annotated. Our process of identifying literary characters in a text, implemented in protagonistTagger, comprises two stages: (1) named entity recognition (NER) of persons, (2) named entity disambiguation (NED) - matching each recognized person with the literary character's full name, based on approximate text matching. The protagonistTagger achieves both precision and recall of above 83% on the prepared testing sets. Finally, we gathered a corpus of 13 full-text novels tagged with protagonistTagger that comprises more than 35,000 mentions of literary characters.