 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnow Your Users! Estimating User Domain Knowledge in Conversational Recommenders
Dec 15, 2025The ideal conversational recommender system (CRS) acts like a savvy salesperson, adapting its language and suggestions to each user's level of expertise. However, most current systems treat all users as experts, leading to frustrating and inefficient interactions when users are unfamiliar with a domain. Systems that can adapt their conversational strategies to a user's knowledge level stand to offer a much more natural and effective experience. To make a step toward such adaptive systems, we introduce a new task: estimating user domain knowledge from conversations, enabling a CRS to better understand user needs and personalize interactions. A key obstacle to developing such adaptive systems is the lack of suitable data; to our knowledge, no existing dataset captures the conversational behaviors of users with varying levels of domain knowledge. Furthermore, in most dialogue collection protocols, users are free to express their own preferences, which tends to concentrate on popular items and well-known features, offering little insight into how novices explore or learn about unfamiliar features. To address this, we design a game-based data collection protocol that elicits varied expressions of knowledge, release the resulting dataset, and provide an initial analysis to highlight its potential for future work on user-knowledge-aware CRS.
Should We Tailor the Talk? Understanding the Impact of Conversational Styles on Preference Elicitation in Conversational Recommender Systems
Apr 17, 2025



Conversational recommender systems (CRSs) provide users with an interactive means to express preferences and receive real-time personalized recommendations. The success of these systems is heavily influenced by the preference elicitation process. While existing research mainly focuses on what questions to ask during preference elicitation, there is a notable gap in understanding what role broader interaction patterns including tone, pacing, and level of proactiveness play in supporting users in completing a given task. This study investigates the impact of different conversational styles on preference elicitation, task performance, and user satisfaction with CRSs. We conducted a controlled experiment in the context of scientific literature recommendation, contrasting two distinct conversational styles, high involvement (fast paced, direct, and proactive with frequent prompts) and high considerateness (polite and accommodating, prioritizing clarity and user comfort) alongside a flexible experimental condition where users could switch between the two. Our results indicate that adapting conversational strategies based on user expertise and allowing flexibility between styles can enhance both user satisfaction and the effectiveness of recommendations in CRSs. Overall, our findings hold important implications for the design of future CRSs.
A Surprisingly Simple yet Effective Multi-Query Rewriting Method for Conversational Passage Retrieval
Jun 27, 2024
Conversational passage retrieval is challenging as it often requires the resolution of references to previous utterances and needs to deal with the complexities of natural language, such as coreference and ellipsis. To address these challenges, pre-trained sequence-to-sequence neural query rewriters are commonly used to generate a single de-contextualized query based on conversation history. Previous research shows that combining multiple query rewrites for the same user utterance has a positive effect on retrieval performance. We propose the use of a neural query rewriter to generate multiple queries and show how to integrate those queries in the passage retrieval pipeline efficiently. The main strength of our approach lies in its simplicity: it leverages how the beam search algorithm works and can produce multiple query rewrites at no additional cost. Our contributions further include devising ways to utilize multi-query rewrites in both sparse and dense first-pass retrieval. We demonstrate that applying our approach on top of a standard passage retrieval pipeline delivers state-of-the-art performance without sacrificing efficiency.
IAI MovieBot 2.0: An Enhanced Research Platform with Trainable Neural Components and Transparent User Modeling
Mar 01, 2024


While interest in conversational recommender systems has been on the rise, operational systems suitable for serving as research platforms for comprehensive studies are currently lacking. This paper introduces an enhanced version of the IAI MovieBot conversational movie recommender system, aiming to evolve it into a robust and adaptable platform for conducting user-facing experiments. The key highlights of this enhancement include the addition of trainable neural components for natural language understanding and dialogue policy, transparent and explainable modeling of user preferences, along with improvements in the user interface and research infrastructure.
PKG API: A Tool for Personal Knowledge Graph Management
Feb 12, 2024


Personal knowledge graphs (PKGs) offer individuals a way to store and consolidate their fragmented personal data in a central place, improving service personalization while maintaining full user control. Despite their potential, practical PKG implementations with user-friendly interfaces remain scarce. This work addresses this gap by proposing a complete solution to represent, manage, and interface with PKGs. Our approach includes (1) a user-facing PKG Client, enabling end-users to administer their personal data easily via natural language statements, and (2) a service-oriented PKG API. To tackle the complexity of representing these statements within a PKG, we present an RDF-based PKG vocabulary that supports this, along with properties for access rights and provenance.
DAGFiNN: A Conversational Conference Assistant
Nov 29, 2022


DAGFiNN is a conversational conference assistant that can be made available for a given conference both as a chatbot on the website and as a Furhat robot physically exhibited at the conference venue. Conference participants can interact with the assistant to get advice on various questions, ranging from where to eat in the city or how to get to the airport to which sessions we recommend them to attend based on the information we have about them. The overall objective is to provide a personalized and engaging experience and allow users to ask a broad range of questions that naturally arise before and during the conference.
Soliciting User Preferences in Conversational Recommender Systems via Usage-related Questions
Nov 26, 2021

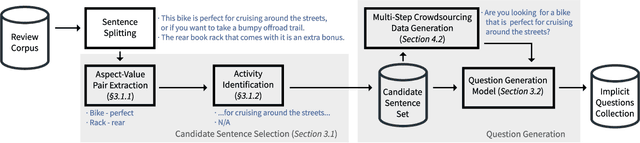
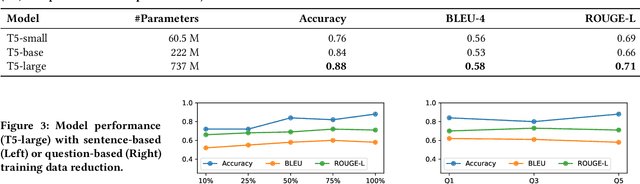
A key distinguishing feature of conversational recommender systems over traditional recommender systems is their ability to elicit user preferences using natural language. Currently, the predominant approach to preference elicitation is to ask questions directly about items or item attributes. These strategies do not perform well in cases where the user does not have sufficient knowledge of the target domain to answer such questions. Conversely, in a shopping setting, talking about the planned use of items does not present any difficulties, even for those that are new to a domain. In this paper, we propose a novel approach to preference elicitation by asking implicit questions based on item usage. Our approach consists of two main steps. First, we identify the sentences from a large review corpus that contain information about item usage. Then, we generate implicit preference elicitation questions from those sentences using a neural text-to-text model. The main contributions of this work also include a multi-stage data annotation protocol using crowdsourcing for collecting high-quality labeled training data for the neural model. We show that our approach is effective in selecting review sentences and transforming them to elicitation questions, even with limited training data. Additionally, we provide an analysis of patterns where the model does not perform optimally.