 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Stupid robot, I want to speak to a human!" User Frustration Detection in Task-Oriented Dialog Systems
Nov 26, 2024



Detecting user frustration in modern-day task-oriented dialog (TOD) systems is imperative for maintaining overall user satisfaction, engagement, and retention. However, most recent research is focused on sentiment and emotion detection in academic settings, thus failing to fully encapsulate implications of real-world user data. To mitigate this gap, in this work, we focus on user frustration in a deployed TOD system, assessing the feasibility of out-of-the-box solutions for user frustration detection. Specifically, we compare the performance of our deployed keyword-based approach, open-source approaches to sentiment analysis, dialog breakdown detection methods, and emerging in-context learning LLM-based detection. Our analysis highlights the limitations of open-source methods for real-world frustration detection, while demonstrating the superior performance of the LLM-based approach, achieving a 16\% relative improvement in F1 score on an internal benchmark. Finally, we analyze advantages and limitations of our methods and provide an insight into user frustration detection task for industry practitioners.
Towards Self-Contained Answers: Entity-Based Answer Rewriting in Conversational Search
Mar 04, 2024



Conversational information-seeking (CIS) is an emerging paradigm for knowledge acquisition and exploratory search. Traditional web search interfaces enable easy exploration of entities, but this is limited in conversational settings due to the limited-bandwidth interface. This paper explore ways to rewrite answers in CIS, so that users can understand them without having to resort to external services or sources. Specifically, we focus on salient entities -- entities that are central to understanding the answer. As our first contribution, we create a dataset of conversations annotated with entities for saliency. Our analysis of the collected data reveals that the majority of answers contain salient entities. As our second contribution, we propose two answer rewriting strategies aimed at improving the overall user experience in CIS. One approach expands answers with inline definitions of salient entities, making the answer self-contained. The other approach complements answers with follow-up questions, offering users the possibility to learn more about specific entities. Results of a crowdsourcing-based study indicate that rewritten answers are clearly preferred over the original ones. We also find that inline definitions tend to be favored over follow-up questions, but this choice is highly subjective, thereby providing a promising future direction for personalization.
Reliable LLM-based User Simulator for Task-Oriented Dialogue Systems
Feb 20, 2024



In the realm of dialogue systems, user simulation techniques have emerged as a game-changer, redefining the evaluation and enhancement of task-oriented dialogue (TOD) systems. These methods are crucial for replicating real user interactions, enabling applications like synthetic data augmentation, error detection, and robust evaluation. However, existing approaches often rely on rigid rule-based methods or on annotated data. This paper introduces DAUS, a Domain-Aware User Simulator. Leveraging large language models, we fine-tune DAUS on real examples of task-oriented dialogues. Results on two relevant benchmarks showcase significant improvements in terms of user goal fulfillment. Notably, we have observed that fine-tuning enhances the simulator's coherence with user goals, effectively mitigating hallucinations -- a major source of inconsistencies in simulator responses.
Estimating the Usefulness of Clarifying Questions and Answers for Conversational Search
Jan 21, 2024While the body of research directed towards constructing and generating clarifying questions in mixed-initiative conversational search systems is vast, research aimed at processing and comprehending users' answers to such questions is scarce. To this end, we present a simple yet effective method for processing answers to clarifying questions, moving away from previous work that simply appends answers to the original query and thus potentially degrades retrieval performance. Specifically, we propose a classifier for assessing usefulness of the prompted clarifying question and an answer given by the user. Useful questions or answers are further appended to the conversation history and passed to a transformer-based query rewriting module. Results demonstrate significant improvements over strong non-mixed-initiative baselines. Furthermore, the proposed approach mitigates the performance drops when non useful questions and answers are utilized.
Analyzing Coherency in Facet-based Clarification Prompt Generation for Search
Jan 09, 2024Clarifying user's information needs is an essential component of modern search systems. While most of the approaches for constructing clarifying prompts rely on query facets, the impact of the quality of the facets is relatively unexplored. In this work, we concentrate on facet quality through the notion of facet coherency and assess its importance for overall usefulness for clarification in search. We find that existing evaluation procedures do not account for facet coherency, as evident by the poor correlation of coherency with automated metrics. Moreover, we propose a coherency classifier and assess the prevalence of incoherent facets in a well-established dataset on clarification. Our findings can serve as motivation for future work on the topic.
Exploiting Simulated User Feedback for Conversational Search: Ranking, Rewriting, and Beyond
May 07, 2023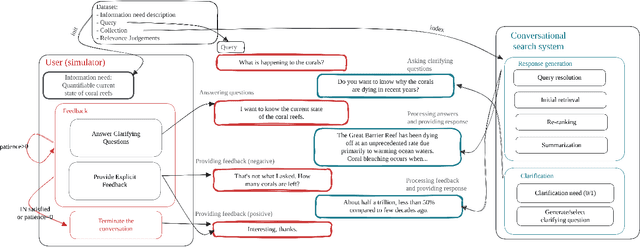


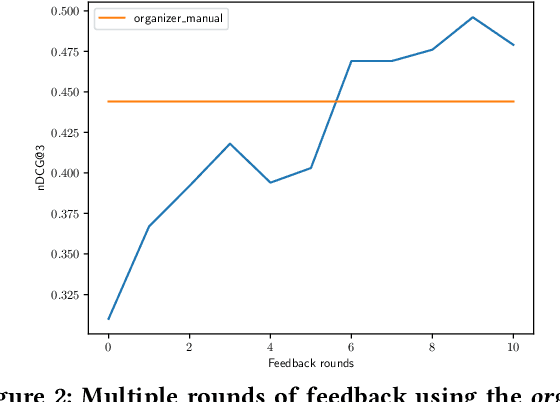
This research aims to explore various methods for assessing user feedback in mixed-initiative conversational search (CS) systems. While CS systems enjoy profuse advancements across multiple aspects, recent research fails to successfully incorporate feedback from the users. One of the main reasons for that is the lack of system-user conversational interaction data. To this end, we propose a user simulator-based framework for multi-turn interactions with a variety of mixed-initiative CS systems. Specifically, we develop a user simulator, dubbed ConvSim, that, once initialized with an information need description, is capable of providing feedback to a system's responses, as well as answering potential clarifying questions. Our experiments on a wide variety of state-of-the-art passage retrieval and neural re-ranking models show that effective utilization of user feedback can lead to 16% retrieval performance increase in terms of nDCG@3. Moreover, we observe consistent improvements as the number of feedback rounds increases (35% relative improvement in terms of nDCG@3 after three rounds). This points to a research gap in the development of specific feedback processing modules and opens a potential for significant advancements in CS. To support further research in the topic, we release over 30,000 transcripts of system-simulator interactions based on well-established CS datasets.
Evaluating Mixed-initiative Conversational Search Systems via User Simulation
Apr 20, 2022
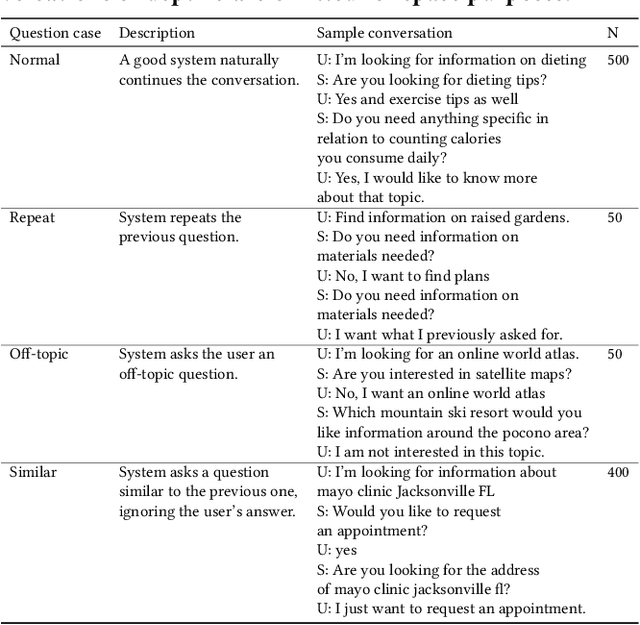
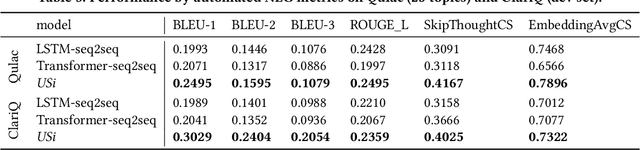

Clarifying the underlying user information need by asking clarifying questions is an important feature of modern conversational search system. However, evaluation of such systems through answering prompted clarifying questions requires significant human effort, which can be time-consuming and expensive. In this paper, we propose a conversational User Simulator, called USi, for automatic evaluation of such conversational search systems. Given a description of an information need, USi is capable of automatically answering clarifying questions about the topic throughout the search session. Through a set of experiments, including automated natural language generation metrics and crowdsourcing studies, we show that responses generated by USi are both inline with the underlying information need and comparable to human-generated answers. Moreover, we make the first steps towards multi-turn interactions, where conversational search systems asks multiple questions to the (simulated) user with a goal of clarifying the user need. To this end, we expand on currently available datasets for studying clarifying questions, i.e., Qulac and ClariQ, by performing a crowdsourcing-based multi-turn data acquisition. We show that our generative, GPT2-based model, is capable of providing accurate and natural answers to unseen clarifying questions in the single-turn setting and discuss capabilities of our model in the multi-turn setting. We provide the code, data, and the pre-trained model to be used for further research on the topic.
User Engagement Prediction for Clarification in Search
Feb 08, 2021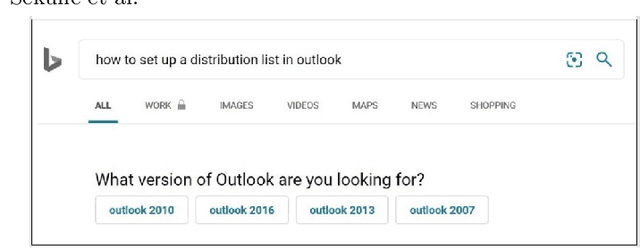
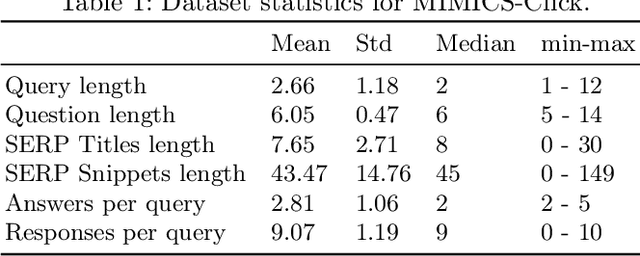
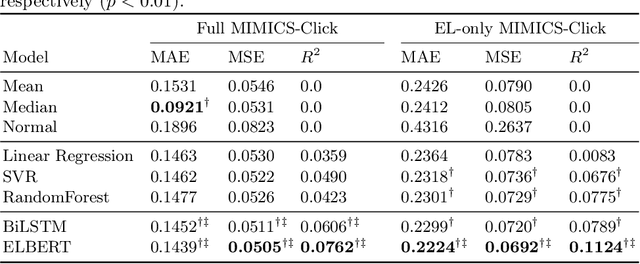
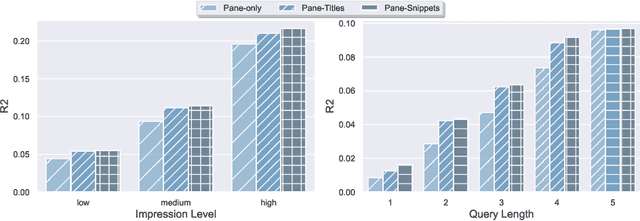
Clarification is increasingly becoming a vital factor in various topics of information retrieval, such as conversational search and modern Web search engines. Prompting the user for clarification in a search session can be very beneficial to the system as the user's explicit feedback helps the system improve retrieval massively. However, it comes with a very high risk of frustrating the user in case the system fails in asking decent clarifying questions. Therefore, it is of great importance to determine when and how to ask for clarification. To this aim, in this work, we model search clarification prediction as user engagement problem. We assume that the better a clarification is, the higher user engagement with it would be. We propose a Transformer-based model to tackle the task. The comparison with competitive baselines on large-scale real-life clarification engagement data proves the effectiveness of our model. Also, we analyse the effect of all result page elements on the performance and find that, among others, the ranked list of the search engine leads to considerable improvements. Our extensive analysis of task-specific features guides future research.
Reasoning with Latent Structure Refinement for Document-Level Relation Extraction
May 15, 2020


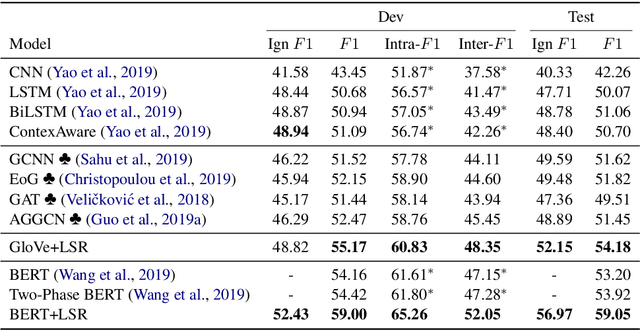
Document-level relation extraction requires integrating information within and across multiple sentences of a document and capturing complex interactions between inter-sentence entities. However, effective aggregation of relevant information in the document remains a challenging research question. Existing approaches construct static document-level graphs based on syntactic trees, co-references or heuristics from the unstructured text to model the dependencies. Unlike previous methods that may not be able to capture rich non-local interactions for inference, we propose a novel model that empowers the relational reasoning across sentences by automatically inducing the latent document-level graph. We further develop a refinement strategy, which enables the model to incrementally aggregate relevant information for multi-hop reasoning. Specifically, our model achieves an F1 score of 59.05 on a large-scale document-level dataset (DocRED), significantly improving over the previous results, and also yields new state-of-the-art results on the CDR and GDA dataset. Furthermore, extensive analyses show that the model is able to discover more accurate inter-sentence relations.
Adapting Deep Learning Methods for Mental Health Prediction on Social Media
Mar 17, 2020
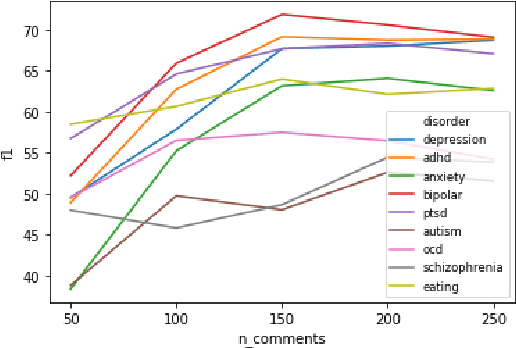


Mental health poses a significant challenge for an individual's well-being. Text analysis of rich resources, like social media, can contribute to deeper understanding of illnesses and provide means for their early detection. We tackle a challenge of detecting social media users' mental status through deep learning-based models, moving away from traditional approaches to the task. In a binary classification task on predicting if a user suffers from one of nine different disorders, a hierarchical attention network outperforms previously set benchmarks for four of the disorders. Furthermore, we explore the limitations of our model and analyze phrases relevant for classification by inspecting the model's word-level attention weights.
* W-NUT at EMNLP 2019