 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Context for Discourse Relation Classification in Scientific Writing
Oct 30, 2025With the increasing use of generative Artificial Intelligence (AI) methods to support science workflows, we are interested in the use of discourse-level information to find supporting evidence for AI generated scientific claims. A first step towards this objective is to examine the task of inferring discourse structure in scientific writing. In this work, we present a preliminary investigation of pretrained language model (PLM) and Large Language Model (LLM) approaches for Discourse Relation Classification (DRC), focusing on scientific publications, an under-studied genre for this task. We examine how context can help with the DRC task, with our experiments showing that context, as defined by discourse structure, is generally helpful. We also present an analysis of which scientific discourse relation types might benefit most from context.
Joint Modeling of Entities and Discourse Relations for Coherence Assessment
Sep 04, 2025



In linguistics, coherence can be achieved by different means, such as by maintaining reference to the same set of entities across sentences and by establishing discourse relations between them. However, most existing work on coherence modeling focuses exclusively on either entity features or discourse relation features, with little attention given to combining the two. In this study, we explore two methods for jointly modeling entities and discourse relations for coherence assessment. Experiments on three benchmark datasets show that integrating both types of features significantly enhances the performance of coherence models, highlighting the benefits of modeling both simultaneously for coherence evaluation.
What Causes the Failure of Explicit to Implicit Discourse Relation Recognition?
Apr 01, 2024We consider an unanswered question in the discourse processing community: why do relation classifiers trained on explicit examples (with connectives removed) perform poorly in real implicit scenarios? Prior work claimed this is due to linguistic dissimilarity between explicit and implicit examples but provided no empirical evidence. In this study, we show that one cause for such failure is a label shift after connectives are eliminated. Specifically, we find that the discourse relations expressed by some explicit instances will change when connectives disappear. Unlike previous work manually analyzing a few examples, we present empirical evidence at the corpus level to prove the existence of such shift. Then, we analyze why label shift occurs by considering factors such as the syntactic role played by connectives, ambiguity of connectives, and more. Finally, we investigate two strategies to mitigate the label shift: filtering out noisy data and joint learning with connectives. Experiments on PDTB 2.0, PDTB 3.0, and the GUM dataset demonstrate that classifiers trained with our strategies outperform strong baselines.
Graph-based Clustering for Detecting Semantic Change Across Time and Languages
Feb 01, 2024


Despite the predominance of contextualized embeddings in NLP, approaches to detect semantic change relying on these embeddings and clustering methods underperform simpler counterparts based on static word embeddings. This stems from the poor quality of the clustering methods to produce sense clusters -- which struggle to capture word senses, especially those with low frequency. This issue hinders the next step in examining how changes in word senses in one language influence another. To address this issue, we propose a graph-based clustering approach to capture nuanced changes in both high- and low-frequency word senses across time and languages, including the acquisition and loss of these senses over time. Our experimental results show that our approach substantially surpasses previous approaches in the SemEval2020 binary classification task across four languages. Moreover, we showcase the ability of our approach as a versatile visualization tool to detect semantic changes in both intra-language and inter-language setups. We make our code and data publicly available.
Normed Spaces for Graph Embedding
Dec 03, 2023



Theoretical results from discrete geometry suggest that normed spaces can abstractly embed finite metric spaces with surprisingly low theoretical bounds on distortion in low dimensions. In this paper, inspired by this theoretical insight, we highlight normed spaces as a more flexible and computationally efficient alternative to several popular Riemannian manifolds for learning graph embeddings. Normed space embeddings significantly outperform several popular manifolds on a large range of synthetic and real-world graph reconstruction benchmark datasets while requiring significantly fewer computational resources. We also empirically verify the superiority of normed space embeddings on growing families of graphs associated with negative, zero, and positive curvature, further reinforcing the flexibility of normed spaces in capturing diverse graph structures as graph sizes increase. Lastly, we demonstrate the utility of normed space embeddings on two applied graph embedding tasks, namely, link prediction and recommender systems. Our work highlights the potential of normed spaces for geometric graph representation learning, raises new research questions, and offers a valuable tool for experimental mathematics in the field of finite metric space embeddings. We make our code and data publically available.
Investigating Multilingual Coreference Resolution by Universal Annotations
Oct 26, 2023Multilingual coreference resolution (MCR) has been a long-standing and challenging task. With the newly proposed multilingual coreference dataset, CorefUD (Nedoluzhko et al., 2022), we conduct an investigation into the task by using its harmonized universal morphosyntactic and coreference annotations. First, we study coreference by examining the ground truth data at different linguistic levels, namely mention, entity and document levels, and across different genres, to gain insights into the characteristics of coreference across multiple languages. Second, we perform an error analysis of the most challenging cases that the SotA system fails to resolve in the CRAC 2022 shared task using the universal annotations. Last, based on this analysis, we extract features from universal morphosyntactic annotations and integrate these features into a baseline system to assess their potential benefits for the MCR task. Our results show that our best configuration of features improves the baseline by 0.9% F1 score.
Modeling Graphs Beyond Hyperbolic: Graph Neural Networks in Symmetric Positive Definite Matrices
Jun 24, 2023Recent research has shown that alignment between the structure of graph data and the geometry of an embedding space is crucial for learning high-quality representations of the data. The uniform geometry of Euclidean and hyperbolic spaces allows for representing graphs with uniform geometric and topological features, such as grids and hierarchies, with minimal distortion. However, real-world graph data is characterized by multiple types of geometric and topological features, necessitating more sophisticated geometric embedding spaces. In this work, we utilize the Riemannian symmetric space of symmetric positive definite matrices (SPD) to construct graph neural networks that can robustly handle complex graphs. To do this, we develop an innovative library that leverages the SPD gyrocalculus tools \cite{lopez2021gyroSPD} to implement the building blocks of five popular graph neural networks in SPD. Experimental results demonstrate that our graph neural networks in SPD substantially outperform their counterparts in Euclidean and hyperbolic spaces, as well as the Cartesian product thereof, on complex graphs for node and graph classification tasks. We release the library and datasets at \url{https://github.com/andyweizhao/SPD4GNNs}.
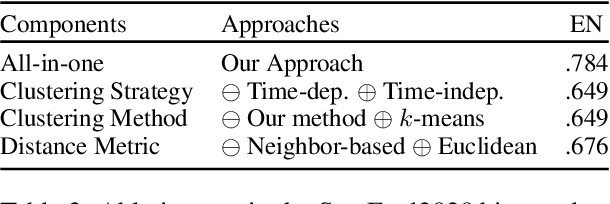
Annotation-Inspired Implicit Discourse Relation Classification with Auxiliary Discourse Connective Generation
Jun 10, 2023

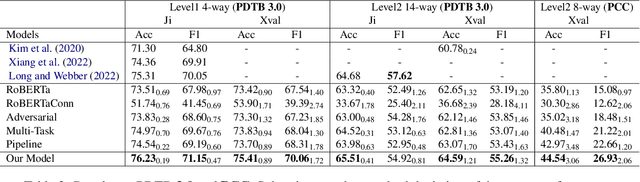

Implicit discourse relation classification is a challenging task due to the absence of discourse connectives. To overcome this issue, we design an end-to-end neural model to explicitly generate discourse connectives for the task, inspired by the annotation process of PDTB. Specifically, our model jointly learns to generate discourse connectives between arguments and predict discourse relations based on the arguments and the generated connectives. To prevent our relation classifier from being misled by poor connectives generated at the early stage of training while alleviating the discrepancy between training and inference, we adopt Scheduled Sampling to the joint learning. We evaluate our method on three benchmarks, PDTB 2.0, PDTB 3.0, and PCC. Results show that our joint model significantly outperforms various baselines on three datasets, demonstrating its superiority for the task.
Modeling Structural Similarities between Documents for Coherence Assessment with Graph Convolutional Networks
Jun 10, 2023
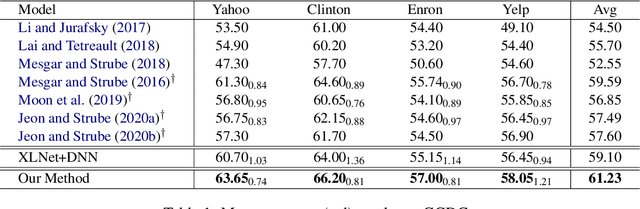


Coherence is an important aspect of text quality, and various approaches have been applied to coherence modeling. However, existing methods solely focus on a single document's coherence patterns, ignoring the underlying correlation between documents. We investigate a GCN-based coherence model that is capable of capturing structural similarities between documents. Our model first creates a graph structure for each document, from where we mine different subgraph patterns. We then construct a heterogeneous graph for the training corpus, connecting documents based on their shared subgraphs. Finally, a GCN is applied to the heterogeneous graph to model the connectivity relationships. We evaluate our method on two tasks, assessing discourse coherence and automated essay scoring. Results show that our GCN-based model outperforms all baselines, achieving a new state-of-the-art on both tasks.
SimCSum: Joint Learning of Simplification and Cross-lingual Summarization for Cross-lingual Science Journalism
Apr 04, 2023Cross-lingual science journalism generates popular science stories of scientific articles different from the source language for a non-expert audience. Hence, a cross-lingual popular summary must contain the salient content of the input document, and the content should be coherent, comprehensible, and in a local language for the targeted audience. We improve these aspects of cross-lingual summary generation by joint training of two high-level NLP tasks, simplification and cross-lingual summarization. The former task reduces linguistic complexity, and the latter focuses on cross-lingual abstractive summarization. We propose a novel multi-task architecture - SimCSum consisting of one shared encoder and two parallel decoders jointly learning simplification and cross-lingual summarization. We empirically investigate the performance of SimCSum by comparing it with several strong baselines over several evaluation metrics and by human evaluation. Overall, SimCSum demonstrates statistically significant improvements over the state-of-the-art on two non-synthetic cross-lingual scientific datasets. Furthermore, we conduct an in-depth investigation into the linguistic properties of generated summaries and an error analysis.