 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePresence or Absence: Are Unknown Word Usages in Dictionaries?
Jun 02, 2024



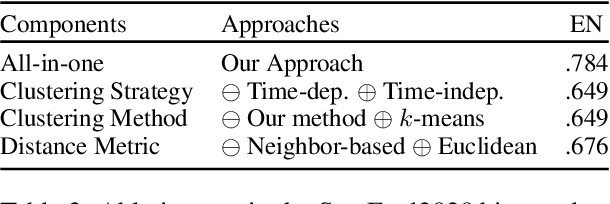
In this work, we outline the components and results of our system submitted to the AXOLOTL-24 shared task for Finnish, Russian and German languages. Our system is fully unsupervised. It leverages a graph-based clustering approach to predict mappings between unknown word usages and dictionary entries for Subtask 1, and generates dictionary-like definitions for those novel word usages through the state-of-the-art Large Language Models such as GPT-4 and LLaMA-3 for Subtask 2. In Subtask 1, our system outperforms the baseline system by a large margin, and it offers interpretability for the mapping results by distinguishing between matched and unmatched (novel) word usages through our graph-based clustering approach. Our system ranks first in Finnish and German, and ranks second in Russian on the Subtask 2 test-phase leaderboard. These results show the potential of our system in managing dictionary entries, particularly for updating dictionaries to include novel sense entries. Our code and data are made publicly available\footnote{\url{https://github.com/xiaohemaikoo/axolotl24-ABDN-NLP}}.
Graph-based Clustering for Detecting Semantic Change Across Time and Languages
Feb 01, 2024


Despite the predominance of contextualized embeddings in NLP, approaches to detect semantic change relying on these embeddings and clustering methods underperform simpler counterparts based on static word embeddings. This stems from the poor quality of the clustering methods to produce sense clusters -- which struggle to capture word senses, especially those with low frequency. This issue hinders the next step in examining how changes in word senses in one language influence another. To address this issue, we propose a graph-based clustering approach to capture nuanced changes in both high- and low-frequency word senses across time and languages, including the acquisition and loss of these senses over time. Our experimental results show that our approach substantially surpasses previous approaches in the SemEval2020 binary classification task across four languages. Moreover, we showcase the ability of our approach as a versatile visualization tool to detect semantic changes in both intra-language and inter-language setups. We make our code and data publicly available.
A No-Reference Quality Assessment Method for Digital Human Head
Oct 25, 2023

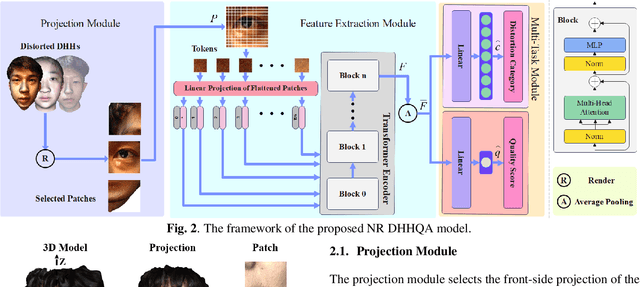
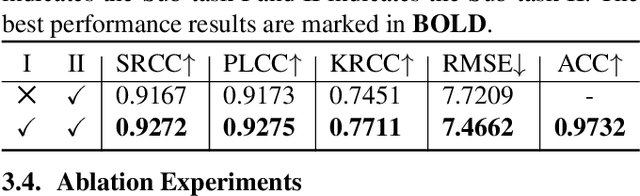
In recent years, digital humans have been widely applied in augmented/virtual reality (A/VR), where viewers are allowed to freely observe and interact with the volumetric content. However, the digital humans may be degraded with various distortions during the procedure of generation and transmission. Moreover, little effort has been put into the perceptual quality assessment of digital humans. Therefore, it is urgent to carry out objective quality assessment methods to tackle the challenge of digital human quality assessment (DHQA). In this paper, we develop a novel no-reference (NR) method based on Transformer to deal with DHQA in a multi-task manner. Specifically, the front 2D projections of the digital humans are rendered as inputs and the vision transformer (ViT) is employed for the feature extraction. Then we design a multi-task module to jointly classify the distortion types and predict the perceptual quality levels of digital humans. The experimental results show that the proposed method well correlates with the subjective ratings and outperforms the state-of-the-art quality assessment methods.