 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Clustering for Detecting Semantic Change Across Time and Languages
Paper and Code
Feb 01, 2024


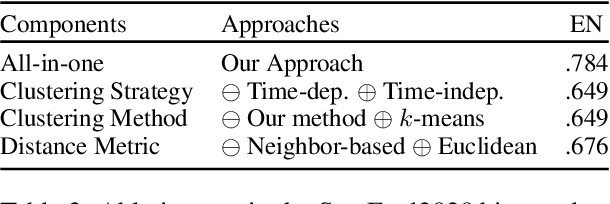
Despite the predominance of contextualized embeddings in NLP, approaches to detect semantic change relying on these embeddings and clustering methods underperform simpler counterparts based on static word embeddings. This stems from the poor quality of the clustering methods to produce sense clusters -- which struggle to capture word senses, especially those with low frequency. This issue hinders the next step in examining how changes in word senses in one language influence another. To address this issue, we propose a graph-based clustering approach to capture nuanced changes in both high- and low-frequency word senses across time and languages, including the acquisition and loss of these senses over time. Our experimental results show that our approach substantially surpasses previous approaches in the SemEval2020 binary classification task across four languages. Moreover, we showcase the ability of our approach as a versatile visualization tool to detect semantic changes in both intra-language and inter-language setups. We make our code and data publicly available.