 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhose Facts Win? LLM Source Preferences under Knowledge Conflicts
Jan 07, 2026As large language models (LLMs) are more frequently used in retrieval-augmented generation pipelines, it is increasingly relevant to study their behavior under knowledge conflicts. Thus far, the role of the source of the retrieved information has gone unexamined. We address this gap with a novel framework to investigate how source preferences affect LLM resolution of inter-context knowledge conflicts in English, motivated by interdisciplinary research on credibility. With a comprehensive, tightly-controlled evaluation of 13 open-weight LLMs, we find that LLMs prefer institutionally-corroborated information (e.g., government or newspaper sources) over information from people and social media. However, these source preferences can be reversed by simply repeating information from less credible sources. To mitigate repetition effects and maintain consistent preferences, we propose a novel method that reduces repetition bias by up to 99.8%, while also maintaining at least 88.8% of original preferences. We release all data and code to encourage future work on credibility and source preferences in knowledge-intensive NLP.
Investigating Gender Bias in News Summarization
Sep 14, 2023Summarization is an important application of large language models (LLMs). Most previous evaluation of summarization models has focused on their performance in content selection, grammaticality and coherence. However, it is well known that LLMs reproduce and reinforce harmful social biases. This raises the question: Do these biases affect model outputs in a relatively constrained setting like summarization? To help answer this question, we first motivate and introduce a number of definitions for biased behaviours in summarization models, along with practical measures to quantify them. Since we find biases inherent to the input document can confound our analysis, we additionally propose a method to generate input documents with carefully controlled demographic attributes. This allows us to sidestep this issue, while still working with somewhat realistic input documents. Finally, we apply our measures to summaries generated by both purpose-built summarization models and general purpose chat models. We find that content selection in single document summarization seems to be largely unaffected by bias, while hallucinations exhibit evidence of biases propagating to generated summaries.
Can current NLI systems handle German word order? Investigating language model performance on a new German challenge set of minimal pairs
Jun 07, 2023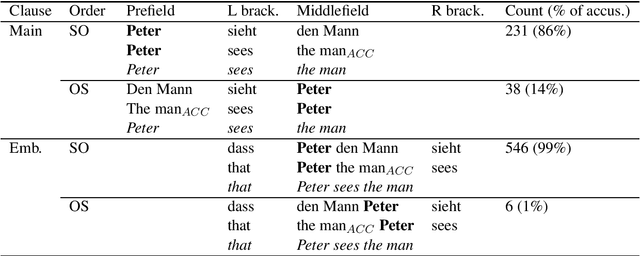
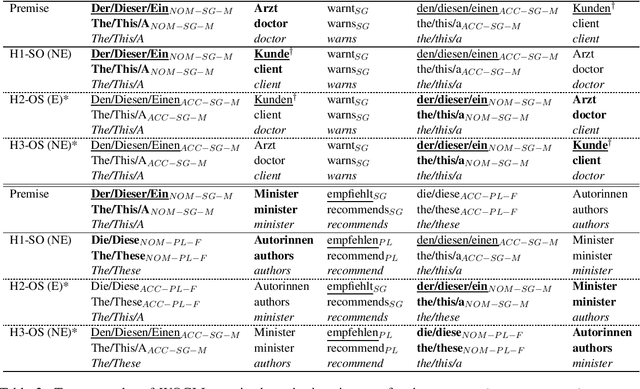
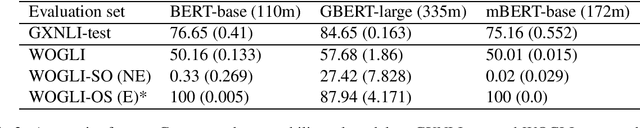

Compared to English, German word order is freer and therefore poses additional challenges for natural language inference (NLI). We create WOGLI (Word Order in German Language Inference), the first adversarial NLI dataset for German word order that has the following properties: (i) each premise has an entailed and a non-entailed hypothesis; (ii) premise and hypotheses differ only in word order and necessary morphological changes to mark case and number. In particular, each premise andits two hypotheses contain exactly the same lemmata. Our adversarial examples require the model to use morphological markers in order to recognise or reject entailment. We show that current German autoencoding models fine-tuned on translated NLI data can struggle on this challenge set, reflecting the fact that translated NLI datasets will not mirror all necessary language phenomena in the target language. We also examine performance after data augmentation as well as on related word order phenomena derived from WOGLI. Our datasets are publically available at https://github.com/ireinig/wogli.
With a Little Push, NLI Models can Robustly and Efficiently Predict Faithfulness
May 26, 2023Conditional language models still generate unfaithful output that is not supported by their input. These unfaithful generations jeopardize trust in real-world applications such as summarization or human-machine interaction, motivating a need for automatic faithfulness metrics. To implement such metrics, NLI models seem attractive, since they solve a strongly related task that comes with a wealth of prior research and data. But recent research suggests that NLI models require costly additional machinery to perform reliably across datasets, e.g., by running inference on a cartesian product of input and generated sentences, or supporting them with a question-generation/answering step. In this work we show that pure NLI models _can_ outperform more complex metrics when combining task-adaptive data augmentation with robust inference procedures. We propose: (1) Augmenting NLI training data to adapt NL inferences to the specificities of faithfulness prediction in dialogue; (2) Making use of both entailment and contradiction probabilities in NLI, and (3) Using Monte-Carlo dropout during inference. Applied to the TRUE benchmark, which combines faithfulness datasets across diverse domains and tasks, our approach strongly improves a vanilla NLI model and significantly outperforms previous work, while showing favourable computational cost.
SimCSum: Joint Learning of Simplification and Cross-lingual Summarization for Cross-lingual Science Journalism
Apr 04, 2023Cross-lingual science journalism generates popular science stories of scientific articles different from the source language for a non-expert audience. Hence, a cross-lingual popular summary must contain the salient content of the input document, and the content should be coherent, comprehensible, and in a local language for the targeted audience. We improve these aspects of cross-lingual summary generation by joint training of two high-level NLP tasks, simplification and cross-lingual summarization. The former task reduces linguistic complexity, and the latter focuses on cross-lingual abstractive summarization. We propose a novel multi-task architecture - SimCSum consisting of one shared encoder and two parallel decoders jointly learning simplification and cross-lingual summarization. We empirically investigate the performance of SimCSum by comparing it with several strong baselines over several evaluation metrics and by human evaluation. Overall, SimCSum demonstrates statistically significant improvements over the state-of-the-art on two non-synthetic cross-lingual scientific datasets. Furthermore, we conduct an in-depth investigation into the linguistic properties of generated summaries and an error analysis.
How to Find Strong Summary Coherence Measures? A Toolbox and a Comparative Study for Summary Coherence Measure Evaluation
Sep 15, 2022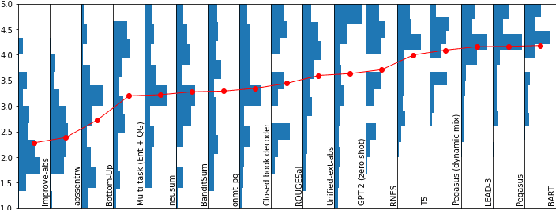
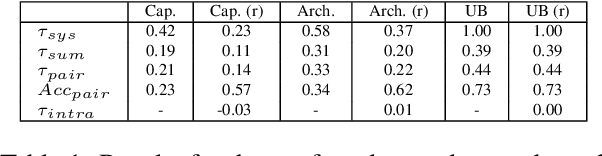

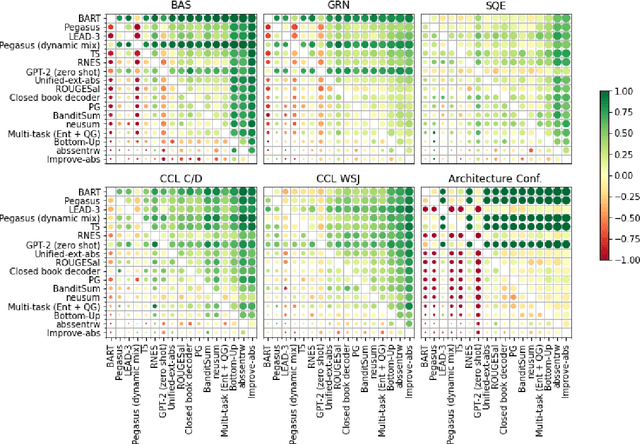
Automatically evaluating the coherence of summaries is of great significance both to enable cost-efficient summarizer evaluation and as a tool for improving coherence by selecting high-scoring candidate summaries. While many different approaches have been suggested to model summary coherence, they are often evaluated using disparate datasets and metrics. This makes it difficult to understand their relative performance and identify ways forward towards better summary coherence modelling. In this work, we conduct a large-scale investigation of various methods for summary coherence modelling on an even playing field. Additionally, we introduce two novel analysis measures, intra-system correlation and bias matrices, that help identify biases in coherence measures and provide robustness against system-level confounders. While none of the currently available automatic coherence measures are able to assign reliable coherence scores to system summaries across all evaluation metrics, large-scale language models fine-tuned on self-supervised tasks show promising results, as long as fine-tuning takes into account that they need to generalize across different summary lengths.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
How to Evaluate a Summarizer: Study Design and Statistical Analysis for Manual Linguistic Quality Evaluation
Jan 27, 2021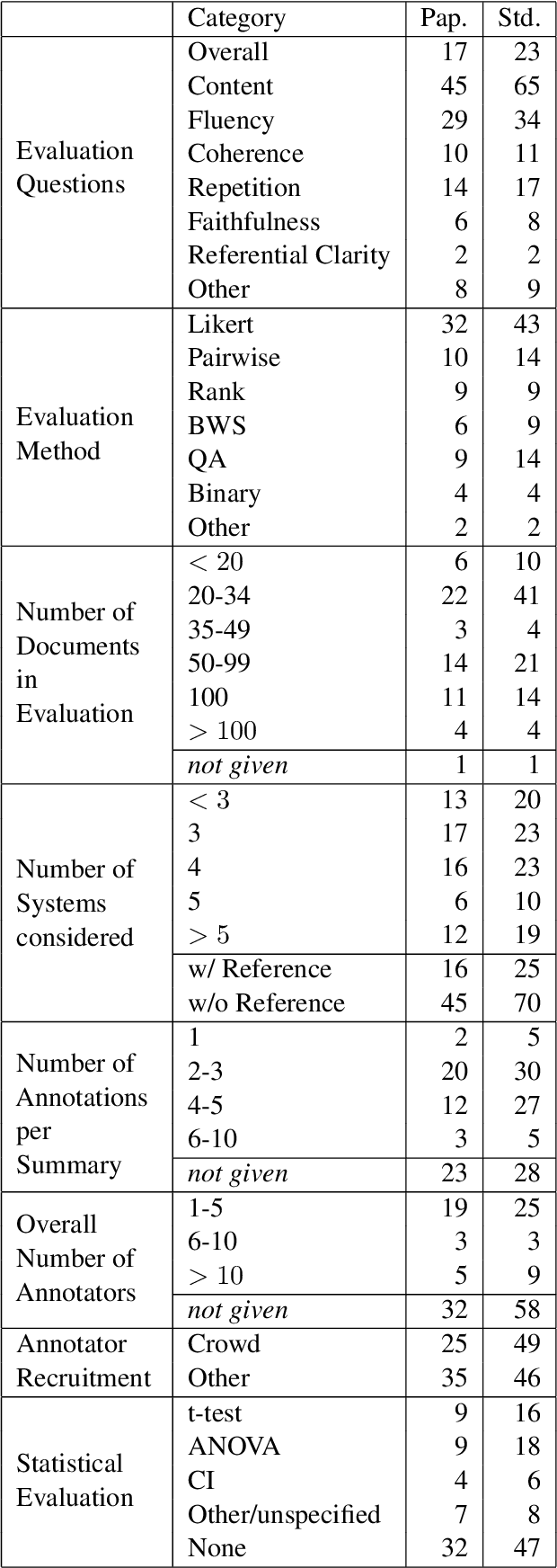
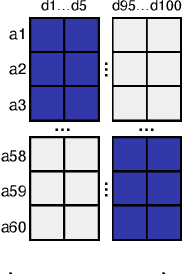

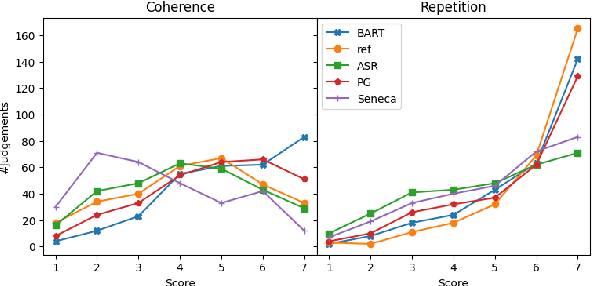
Manual evaluation is essential to judge progress on automatic text summarization. However, we conduct a survey on recent summarization system papers that reveals little agreement on how to perform such evaluation studies. We conduct two evaluation experiments on two aspects of summaries' linguistic quality (coherence and repetitiveness) to compare Likert-type and ranking annotations and show that best choice of evaluation method can vary from one aspect to another. In our survey, we also find that study parameters such as the overall number of annotators and distribution of annotators to annotation items are often not fully reported and that subsequent statistical analysis ignores grouping factors arising from one annotator judging multiple summaries. Using our evaluation experiments, we show that the total number of annotators can have a strong impact on study power and that current statistical analysis methods can inflate type I error rates up to eight-fold. In addition, we highlight that for the purpose of system comparison the current practice of eliciting multiple judgements per summary leads to less powerful and reliable annotations given a fixed study budget.
Context in Informational Bias Detection
Dec 03, 2020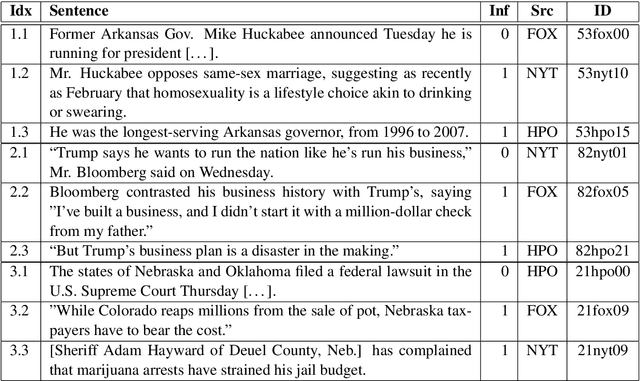
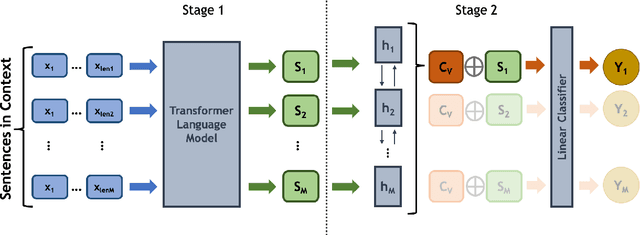
Informational bias is bias conveyed through sentences or clauses that provide tangential, speculative or background information that can sway readers' opinions towards entities. By nature, informational bias is context-dependent, but previous work on informational bias detection has not explored the role of context beyond the sentence. In this paper, we explore four kinds of context for informational bias in English news articles: neighboring sentences, the full article, articles on the same event from other news publishers, and articles from the same domain (but potentially different events). We find that integrating event context improves classification performance over a very strong baseline. In addition, we perform the first error analysis of models on this task. We find that the best-performing context-inclusive model outperforms the baseline on longer sentences, and sentences from politically centrist articles.
Discrete Optimization for Unsupervised Sentence Summarization with Word-Level Extraction
May 04, 2020
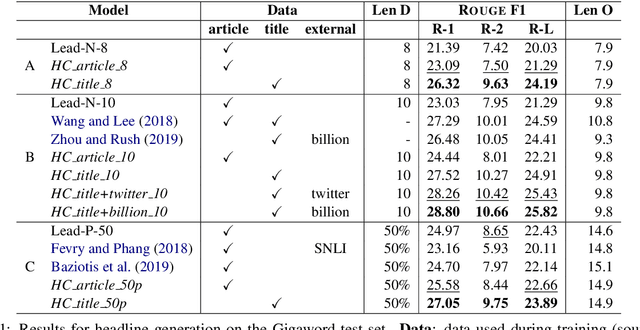
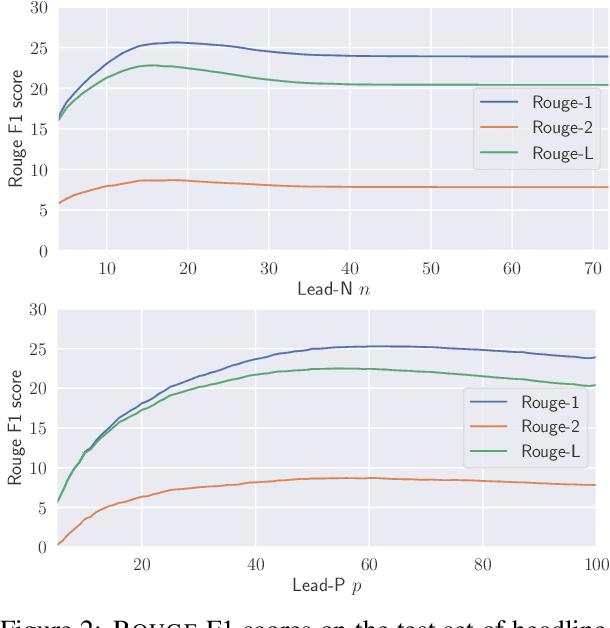
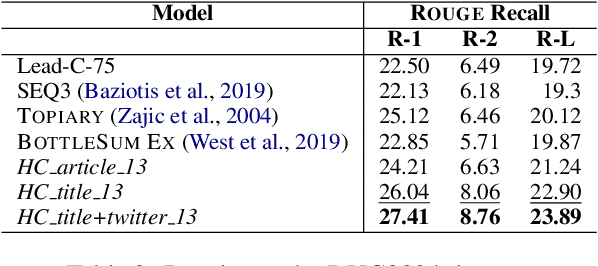
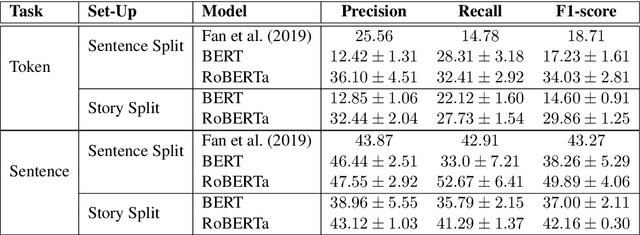
Automatic sentence summarization produces a shorter version of a sentence, while preserving its most important information. A good summary is characterized by language fluency and high information overlap with the source sentence. We model these two aspects in an unsupervised objective function, consisting of language modeling and semantic similarity metrics. We search for a high-scoring summary by discrete optimization. Our proposed method achieves a new state-of-the art for unsupervised sentence summarization according to ROUGE scores. Additionally, we demonstrate that the commonly reported ROUGE F1 metric is sensitive to summary length. Since this is unwillingly exploited in recent work, we emphasize that future evaluation should explicitly group summarization systems by output length brackets.