 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source (Pre-)Training for Cross-Domain Measurement, Unit and Context Extraction
Aug 05, 2023We present a cross-domain approach for automated measurement and context extraction based on pre-trained language models. We construct a multi-source, multi-domain corpus and train an end-to-end extraction pipeline. We then apply multi-source task-adaptive pre-training and fine-tuning to benchmark the cross-domain generalization capability of our model. Further, we conceptualize and apply a task-specific error analysis and derive insights for future work. Our results suggest that multi-source training leads to the best overall results, while single-source training yields the best results for the respective individual domain. While our setup is successful at extracting quantity values and units, more research is needed to improve the extraction of contextual entities. We make the cross-domain corpus used in this work available online.
A Temporally Sensitive Submodularity Framework for Timeline Summarization
Oct 18, 2018
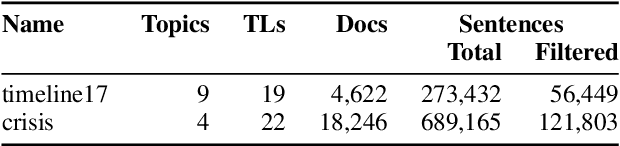
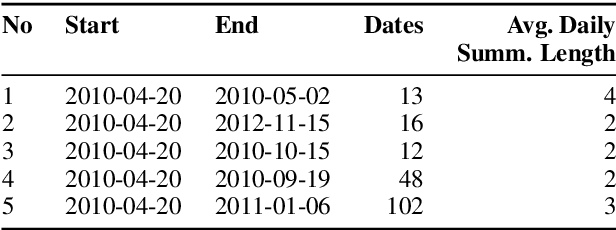

Timeline summarization (TLS) creates an overview of long-running events via dated daily summaries for the most important dates. TLS differs from standard multi-document summarization (MDS) in the importance of date selection, interdependencies between summaries of different dates and by having very short summaries compared to the number of corpus documents. However, we show that MDS optimization models using submodular functions can be adapted to yield well-performing TLS models by designing objective functions and constraints that model the temporal dimension inherent in TLS. Importantly, these adaptations retain the elegance and advantages of the original MDS models (clear separation of features and inference, performance guarantees and scalability, little need for supervision) that current TLS-specific models lack. An open-source implementation of the framework and all models described in this paper is available online.
Dynamic Entity Representations in Neural Language Models
Aug 02, 2017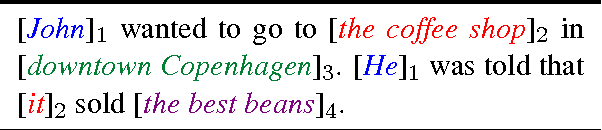

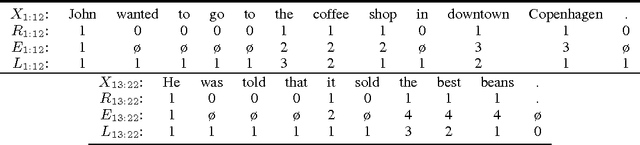

Understanding a long document requires tracking how entities are introduced and evolve over time. We present a new type of language model, EntityNLM, that can explicitly model entities, dynamically update their representations, and contextually generate their mentions. Our model is generative and flexible; it can model an arbitrary number of entities in context while generating each entity mention at an arbitrary length. In addition, it can be used for several different tasks such as language modeling, coreference resolution, and entity prediction. Experimental results with all these tasks demonstrate that our model consistently outperforms strong baselines and prior work.