 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext in Informational Bias Detection
Dec 03, 2020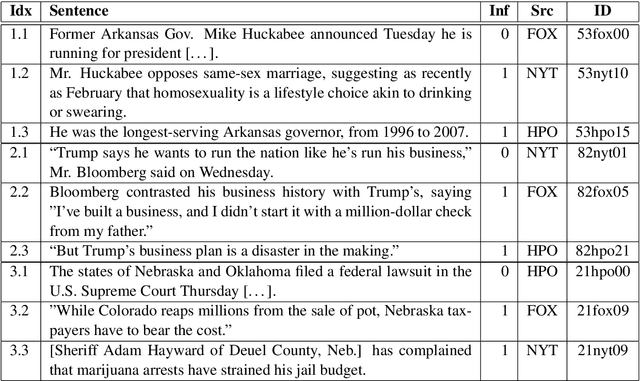
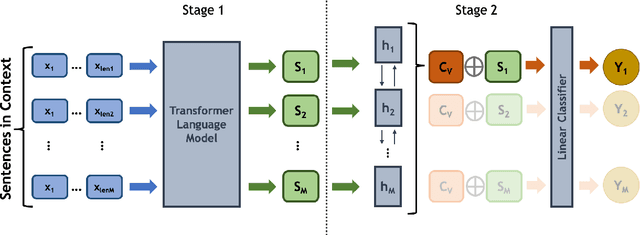
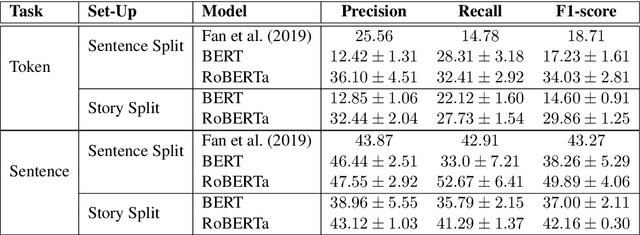
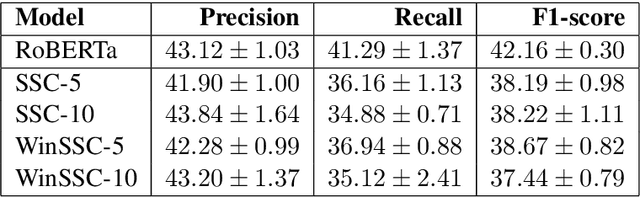
Informational bias is bias conveyed through sentences or clauses that provide tangential, speculative or background information that can sway readers' opinions towards entities. By nature, informational bias is context-dependent, but previous work on informational bias detection has not explored the role of context beyond the sentence. In this paper, we explore four kinds of context for informational bias in English news articles: neighboring sentences, the full article, articles on the same event from other news publishers, and articles from the same domain (but potentially different events). We find that integrating event context improves classification performance over a very strong baseline. In addition, we perform the first error analysis of models on this task. We find that the best-performing context-inclusive model outperforms the baseline on longer sentences, and sentences from politically centrist articles.
Distant Supervision and Noisy Label Learning for Low Resource Named Entity Recognition: A Study on Hausa and Yorùbá
Mar 31, 2020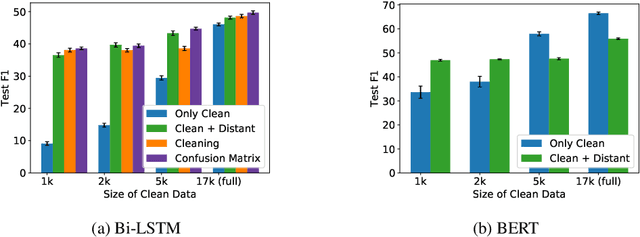
The lack of labeled training data has limited the development of natural language processing tools, such as named entity recognition, for many languages spoken in developing countries. Techniques such as distant and weak supervision can be used to create labeled data in a (semi-) automatic way. Additionally, to alleviate some of the negative effects of the errors in automatic annotation, noise-handling methods can be integrated. Pretrained word embeddings are another key component of most neural named entity classifiers. With the advent of more complex contextual word embeddings, an interesting trade-off between model size and performance arises. While these techniques have been shown to work well in high-resource settings, we want to study how they perform in low-resource scenarios. In this work, we perform named entity recognition for Hausa and Yor\`ub\'a, two languages that are widely spoken in several developing countries. We evaluate different embedding approaches and show that distant supervision can be successfully leveraged in a realistic low-resource scenario where it can more than double a classifier's performance.