 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Reliable is Multilingual LLM-as-a-Judge?
May 18, 2025LLM-as-a-Judge has emerged as a popular evaluation strategy, where advanced large language models assess generation results in alignment with human instructions. While these models serve as a promising alternative to human annotators, their reliability in multilingual evaluation remains uncertain. To bridge this gap, we conduct a comprehensive analysis of multilingual LLM-as-a-Judge. Specifically, we evaluate five models from different model families across five diverse tasks involving 25 languages. Our findings reveal that LLMs struggle to achieve consistent judgment results across languages, with an average Fleiss' Kappa of approximately 0.3, and some models performing even worse. To investigate the cause of inconsistency, we analyze various influencing factors. We observe that consistency varies significantly across languages, with particularly poor performance in low-resource languages. Additionally, we find that neither training on multilingual data nor increasing model scale directly improves judgment consistency. These findings suggest that LLMs are not yet reliable for evaluating multilingual predictions. We finally propose an ensemble strategy which improves the consistency of the multilingual judge in real-world applications.
The Mystery of Compositional Generalization in Graph-based Generative Commonsense Reasoning
Oct 08, 2024While LLMs have emerged as performant architectures for reasoning tasks, their compositional generalization capabilities have been questioned. In this work, we introduce a Compositional Generalization Challenge for Graph-based Commonsense Reasoning (CGGC) that goes beyond previous evaluations that are based on sequences or tree structures - and instead involves a reasoning graph: It requires models to generate a natural sentence based on given concepts and a corresponding reasoning graph, where the presented graph involves a previously unseen combination of relation types. To master this challenge, models need to learn how to reason over relation tupels within the graph, and how to compose them when conceptualizing a verbalization. We evaluate seven well-known LLMs using in-context learning and find that performant LLMs still struggle in compositional generalization. We investigate potential causes of this gap by analyzing the structures of reasoning graphs, and find that different structures present varying levels of difficulty for compositional generalization. Arranging the order of demonstrations according to the structures' difficulty shows that organizing samples in an easy-to-hard schema enhances the compositional generalization ability of LLMs.
Exploring Continual Learning of Compositional Generalization in NLI
Mar 07, 2024Compositional Natural Language Inference has been explored to assess the true abilities of neural models to perform NLI. Yet, current evaluations assume models to have full access to all primitive inferences in advance, in contrast to humans that continuously acquire inference knowledge. In this paper, we introduce the Continual Compositional Generalization in Inference (C2Gen NLI) challenge, where a model continuously acquires knowledge of constituting primitive inference tasks as a basis for compositional inferences. We explore how continual learning affects compositional generalization in NLI, by designing a continual learning setup for compositional NLI inference tasks. Our experiments demonstrate that models fail to compositionally generalize in a continual scenario. To address this problem, we first benchmark various continual learning algorithms and verify their efficacy. We then further analyze C2Gen, focusing on how to order primitives and compositional inference types and examining correlations between subtasks. Our analyses show that by learning subtasks continuously while observing their dependencies and increasing degrees of difficulty, continual learning can enhance composition generalization ability.
Dynamic MOdularized Reasoning for Compositional Structured Explanation Generation
Sep 14, 2023



Despite the success of neural models in solving reasoning tasks, their compositional generalization capabilities remain unclear. In this work, we propose a new setting of the structured explanation generation task to facilitate compositional reasoning research. Previous works found that symbolic methods achieve superior compositionality by using pre-defined inference rules for iterative reasoning. But these approaches rely on brittle symbolic transfers and are restricted to well-defined tasks. Hence, we propose a dynamic modularized reasoning model, MORSE, to improve the compositional generalization of neural models. MORSE factorizes the inference process into a combination of modules, where each module represents a functional unit. Specifically, we adopt modularized self-attention to dynamically select and route inputs to dedicated heads, which specializes them to specific functions. We conduct experiments for increasing lengths and shapes of reasoning trees on two benchmarks to test MORSE's compositional generalization abilities, and find it outperforms competitive baselines. Model ablation and deeper analyses show the effectiveness of dynamic reasoning modules and their generalization abilities.
Modeling Structural Similarities between Documents for Coherence Assessment with Graph Convolutional Networks
Jun 10, 2023
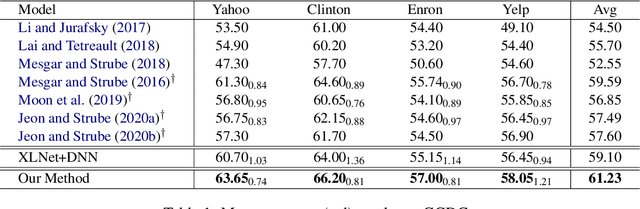


Coherence is an important aspect of text quality, and various approaches have been applied to coherence modeling. However, existing methods solely focus on a single document's coherence patterns, ignoring the underlying correlation between documents. We investigate a GCN-based coherence model that is capable of capturing structural similarities between documents. Our model first creates a graph structure for each document, from where we mine different subgraph patterns. We then construct a heterogeneous graph for the training corpus, connecting documents based on their shared subgraphs. Finally, a GCN is applied to the heterogeneous graph to model the connectivity relationships. We evaluate our method on two tasks, assessing discourse coherence and automated essay scoring. Results show that our GCN-based model outperforms all baselines, achieving a new state-of-the-art on both tasks.
SETI: Systematicity Evaluation of Textual Inference
May 24, 2023We propose SETI (Systematicity Evaluation of Textual Inference), a novel and comprehensive benchmark designed for evaluating pre-trained language models (PLMs) for their systematicity capabilities in the domain of textual inference. Specifically, SETI offers three different NLI tasks and corresponding datasets to evaluate various types of systematicity in reasoning processes. In order to solve these tasks, models are required to perform compositional inference based on known primitive constituents. We conduct experiments of SETI on six widely used PLMs. Results show that various PLMs are able to solve unseen compositional inferences when having encountered the knowledge of how to combine primitives, with good performance. However, they are considerably limited when this knowledge is unknown to the model (40-100% points decrease). Furthermore, we find that PLMs can improve drastically once exposed to crucial compositional knowledge in minimalistic shots. These findings position SETI as the first benchmark for measuring the future progress of PLMs in achieving systematicity generalization in the textual inference.
Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter
May 20, 2021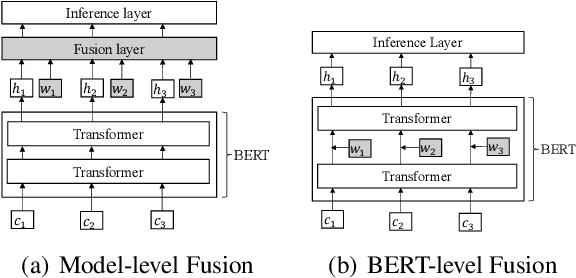
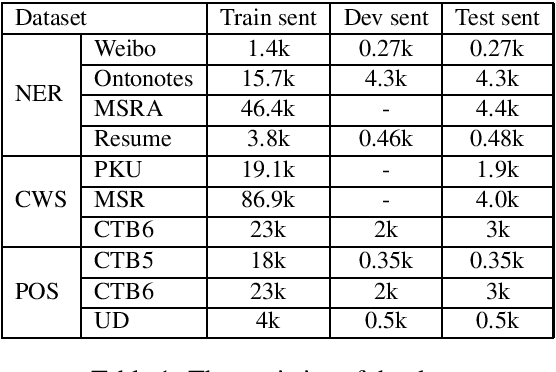
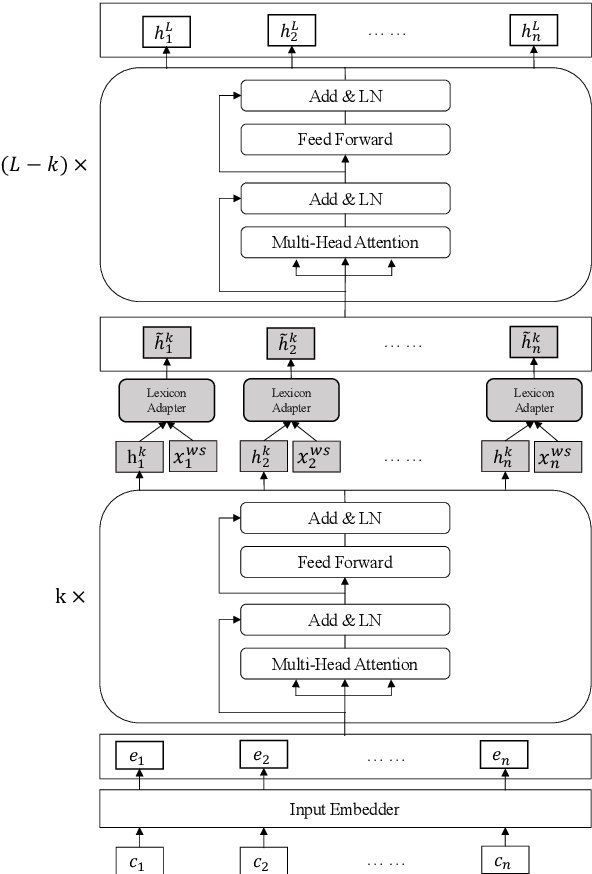
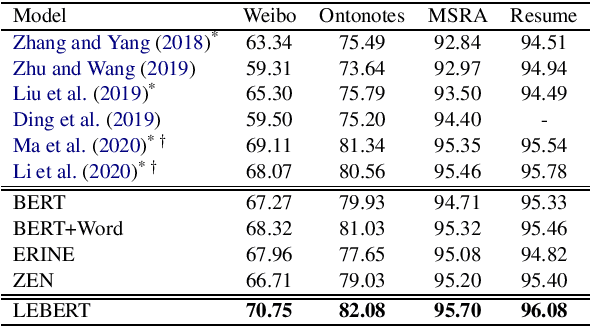
Lexicon information and pre-trained models, such as BERT, have been combined to explore Chinese sequence labelling tasks due to their respective strengths. However, existing methods solely fuse lexicon features via a shallow and random initialized sequence layer and do not integrate them into the bottom layers of BERT. In this paper, we propose Lexicon Enhanced BERT (LEBERT) for Chinese sequence labelling, which integrates external lexicon knowledge into BERT layers directly by a Lexicon Adapter layer. Compared with the existing methods, our model facilitates deep lexicon knowledge fusion at the lower layers of BERT. Experiments on ten Chinese datasets of three tasks including Named Entity Recognition, Word Segmentation, and Part-of-Speech tagging, show that LEBERT achieves the state-of-the-art results.
Multi-modal Summarization for Video-containing Documents
Sep 17, 2020

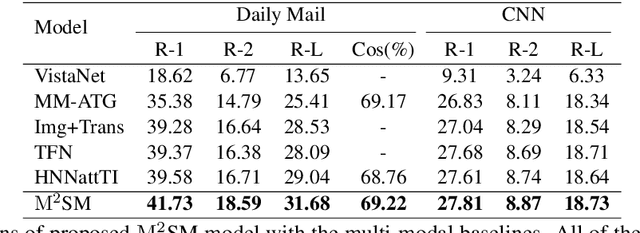
Summarization of multimedia data becomes increasingly significant as it is the basis for many real-world applications, such as question answering, Web search, and so forth. Most existing multi-modal summarization works however have used visual complementary features extracted from images rather than videos, thereby losing abundant information. Hence, we propose a novel multi-modal summarization task to summarize from a document and its associated video. In this work, we also build a baseline general model with effective strategies, i.e., bi-hop attention and improved late fusion mechanisms to bridge the gap between different modalities, and a bi-stream summarization strategy to employ text and video summarization simultaneously. Comprehensive experiments show that the proposed model is beneficial for multi-modal summarization and superior to existing methods. Moreover, we collect a novel dataset and it provides a new resource for future study that results from documents and videos.